Quantum Enhanced Inference in Markov Logic Networks
Markov logic networks (MLNs) reconcile two opposing schools in machine learning and artificial intelligence: causal networks, which account for uncertainty extremely well, and first-order logic, which allows for formal deduction. An MLN is essentially a first-order logic template to generate Markov networks. Inference in MLNs is probabilistic and it is often performed by approximate methods such as Markov chain Monte Carlo (MCMC) Gibbs sampling. An MLN has many regular, symmetric structures that can be exploited at both first-order level and in the generated Markov network. We analyze the graph structures that are produced by various lifting methods and investigate the extent to which quantum protocols can be used to speed up Gibbs sampling with state preparation and measurement schemes. We review different such approaches, discuss their advantages, theoretical limitations, and their appeal to implementations. We find that a straightforward application of a recent result yields exponential speedup compared to classical heuristics in approximate probabilistic inference, thereby demonstrating another example where advanced quantum resources can potentially prove useful in machine learning.
💡 Research Summary
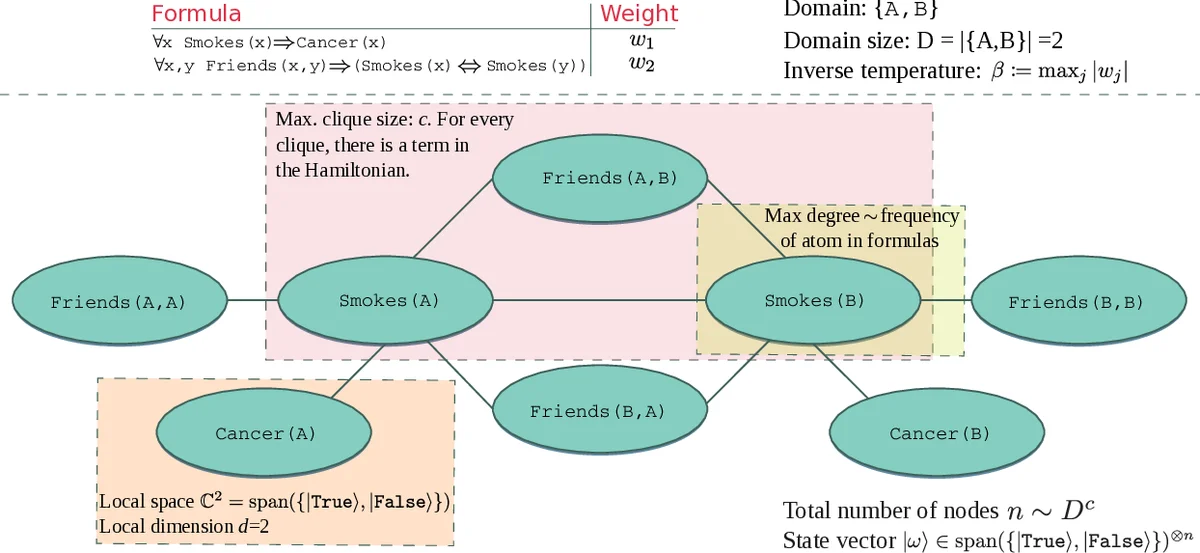
The paper “Quantum Enhanced Inference in Markov Logic Networks” investigates how recent quantum algorithms for Gibbs‑state preparation can be leveraged to accelerate probabilistic inference in Markov Logic Networks (MLNs). MLNs combine first‑order logical templates with undirected graphical models, producing a ground Markov network whose size grows as O(D^c), where D is the domain size and c the maximum number of atoms per formula. Classical inference, whether exact (#P‑complete) or approximate (NP‑hard), typically relies on Markov chain Monte Carlo (MCMC) Gibbs sampling, which becomes computationally prohibitive as the number of groundings explodes.
The authors first perform a detailed structural analysis of the graphs generated by various lifting (symmetry‑exploiting) techniques. They tabulate how formula characteristics—number of atoms, clique size, shared variables, domain size—affect graph metrics such as total node count, maximum degree, and number of local factors. By grouping symmetric groundings before grounding (lifted inference), the effective number of factors can be reduced from O(n) to O(n^α) with 0 ≤ α ≤ 1, where n denotes the total number of possible ground atoms.
Next, the paper maps the MLN probability distribution
P_M(ω) = exp(∑_j w_j N(f_j, ω))/Z
to a thermal Gibbs state of a quantum system. Each weighted formula w_j f_j is translated into a local Hamiltonian term h_ℓ acting on the qubits that correspond to the atoms in a particular grounding. The full Hamiltonian H is a sum of k‑local terms (k equals the maximum clique size) and the inverse temperature β is set to max_j|w_j|. Consequently, the target distribution becomes P_M(ω) = ⟨ω|e^{‑βH}|ω⟩/Z, i.e., the diagonal of a Gibbs state of H.
The quantum Gibbs‑sampling procedure consists of two phases. (1) State preparation: using the algorithm of Chowdhury and Somma (arXiv 2018) the authors prepare a mixed state ε‑close to e^{‑βH}/Z. The algorithm’s gate complexity scales as O(p d n β/Z · polylog(p d n β/Z / ε)), where p is a polynomial factor, d=2 is the local qubit dimension, n is the number of qubits (ground atoms), and the number of local terms is O(n^α) under the lifting assumption. The crucial assumption is that each local term’s support size c is constant, which holds for many MLNs with bounded clause size. (2) Measurement: after preparation, local computational‑basis measurements on each qubit yield a sample from the desired distribution; this step costs O(n) time.
Comparing complexities, classical MCMC typically requires O(poly(n)) steps per sample, but each step may involve evaluating many factors, leading to an overall cost that can be exponential in the clique size or domain. The quantum approach, by contrast, replaces the repeated factor evaluations with a one‑time Hamiltonian simulation whose cost grows only linearly (or near‑linearly) with n, provided β is not too large (i.e., the system is not at extremely low temperature). When β is large, cooling the quantum system becomes difficult, and the authors suggest hybrid quantum‑classical schemes or tempering strategies.
The paper also discusses practical implementation constraints. Current quantum hardware supports only 2‑local or, at best, 3‑local interactions, and gate errors limit the achievable β and system size. Nevertheless, for MLNs with bounded clause size (constant c) and a modest number of lifted factors (α ≈ 0.5–0.8), the required Hamiltonian can be embedded into existing superconducting or trapped‑ion platforms. The authors outline how to decompose each h_ℓ into native gate sets, estimate the depth needed for a given β, and argue that the preparation phase remains feasible for n in the low‑hundreds—a regime already of interest for many relational learning tasks.
In conclusion, the authors demonstrate that a straightforward application of a recent quantum Gibbs‑state preparation algorithm yields, in theory, an exponential speed‑up over the best known classical heuristics for approximate inference in MLNs. The speed‑up hinges on exploiting the symmetries identified by lifted inference and on the assumption of bounded clause size. While hardware limitations currently restrict the size of problems that can be tackled, the work provides a clear roadmap: (i) identify lifted structures to reduce the number of Hamiltonian terms, (ii) map the reduced MLN to a k‑local Hamiltonian, (iii) employ quantum Gibbs‑state preparation, and (iv) perform local measurements to obtain samples. Future research directions include extending the method to non‑constant clause sizes, developing error‑robust cooling protocols for low‑temperature regimes, and performing empirical benchmarks on real‑world relational datasets.
Comments & Academic Discussion
Loading comments...
Leave a Comment