Expert Gate: Lifelong Learning with a Network of Experts
In this paper we introduce a model of lifelong learning, based on a Network of Experts. New tasks / experts are learned and added to the model sequentially, building on what was learned before. To ensure scalability of this process,data from previous…
Authors: Rahaf Aljundi, Punarjay Chakravarty, Tinne Tuytelaars
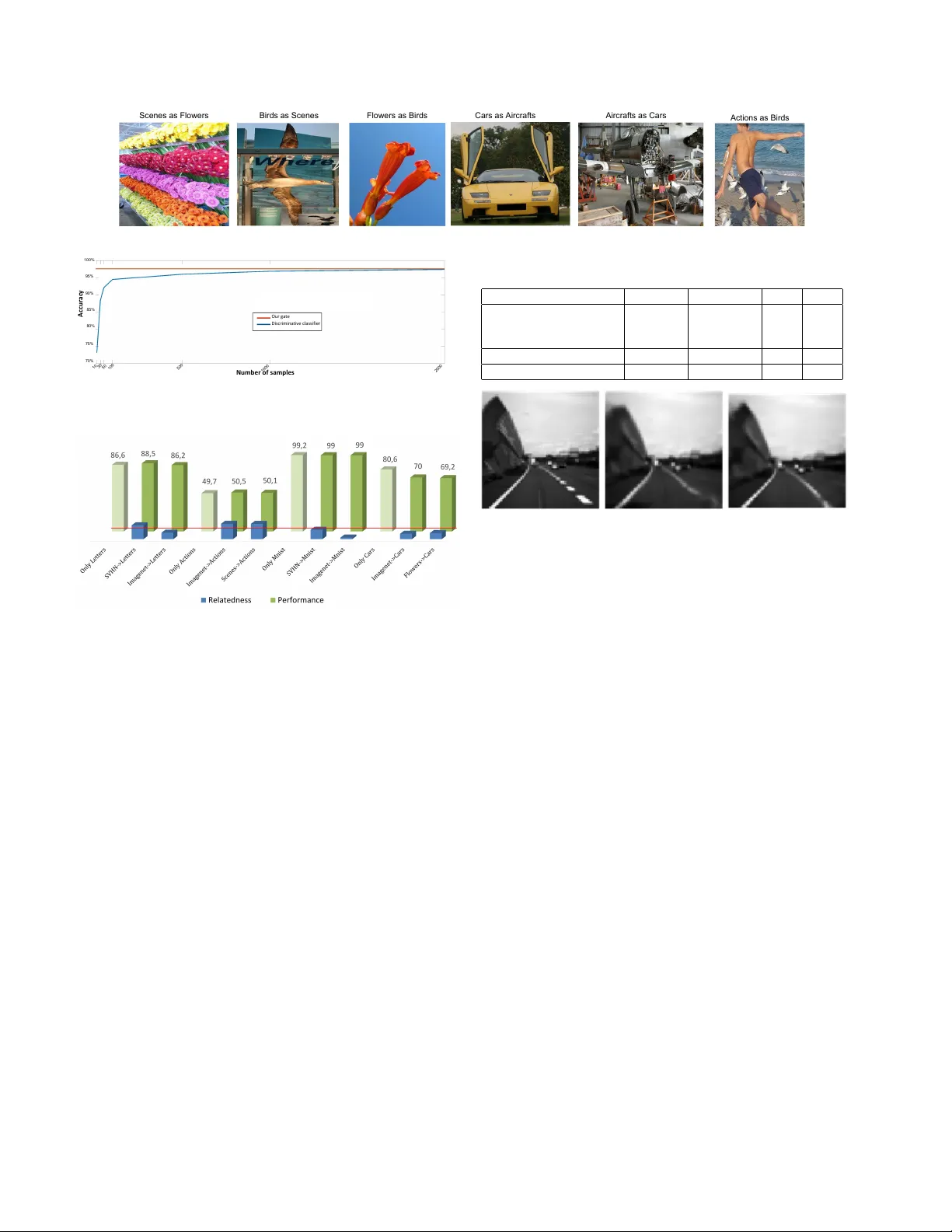
Expert Gate: Lifelong Learning with a Netw ork of Experts Rahaf Aljundi Punarjay Chakrav arty { rahaf.aljundi, Punarjay .Chakra varty , T inne.T uytelaars } @esat.kuleuven.be KU Leuven, ESA T -PSI, IMEC, Belgium T inne T uytelaars Abstract In this paper we intr oduce a model of lifelong learning, based on a Network of Experts. New tasks / e xperts ar e learned and added to the model sequentially , building on what was learned befor e. T o ensure scalability of this pro- cess, data fr om pr evious tasks cannot be stor ed and hence is not available when learning a new task. A critical issue in such context, not addressed in the literatur e so far , relates to the decision whic h e xpert to deploy at test time . W e in- tr oduce a set of gating autoencoders that learn a repr esen- tation for the task at hand, and, at test time, automatically forwar d the test sample to the r elevant e xpert. This also brings memory efficiency as only one e xpert network has to be loaded into memory at any given time . Further , the au- toencoders inher ently captur e the r elatedness of one task to another , based on which the most r elevant prior model to be used for training a new expert, with fine-tuning or learning- without-for getting, can be selected. W e evaluate our method on image classification and video pr ediction pr oblems. 1. Introduction In the age of deep learning and big data, we face a sit- uation where we train e ver more complicated models with ev er increasing amounts of data. W e hav e different mod- els for dif ferent tasks trained on dif ferent datasets, each of which is an expert on its own domain, but not on others. In a typical setting, each new task comes with its own dataset. Learning a ne w task, say scene classification based on a pre- existing object recognition network trained on ImageNet, requires adapting the model to the ne w set of classes and fine-tuning it with the new data. The newly trained network performs well on the ne w task, but has a degraded perfor - mance on the old ones. This is called catastr ophic for get- ting [12], and is a major problem facing life long learning techniques [32, 33, 31], where ne w tasks and datasets are added in a sequential manner . Ideally , a system should be able to operate on different tasks and domains and gi ve the best performance on each of them. F or e xample, an image classification system that Features Extraction Input T1 T2 T k ... Soft max Expert k Expert 2 Expert 1 The Gate ... Figure 1. The architecture of our Expert Gate system. is able to operate on generic as well as fine-grained classes, and in addition performs action and scene classification. If all previous training data were a v ailable, a direct solution would be to jointly train a model on all the different tasks or domains. Each time a new task arri ves along with its own training data, ne w layers/neurons are added, if needed, and the model is retrained on all the tasks. Such a solu- tion has three main dra wbacks. The first is the risk of the negati ve inductiv e bias when the tasks are not related or simply adversarial. Second, a shared model might fail to capture specialist information for particular tasks as joint training will encourage a hidden representation beneficial for all tasks. Third, each time a ne w task is to be learned, the whole network needs to be re-trained. Apart from the abov e drawbacks, the biggest constraint with joint training is that of keeping all the data from the previous tasks. This is a difficult requirement to be met, especially in the era of big data. For example, ILSVRC [30] has 1000 classes, with ov er a million images, amounting to 200 GB of data. Y et the AlexNet model trained on the same dataset, is only 200 MB, a dif ference in size of three orders of magnitude. W ith increasing amounts of data collected, it becomes less and less feasible to store all the training data, and more practi- cal to just store the models learned from the data. W ithout storing the data, one can consider strate gies like using the pre vious model to generate virtual samples (i.e. 1 use the soft outputs of the old model on ne w task data to generate virtual labels) and use them in the retraining phase [5, 21, 32]. This works to some extent, but is unlikely to scale as repeating this scheme a number of times causes a bias towards the new tasks and an exponential buildup of errors on the older ones, as we show in our e xperiments. Moreov er , it suffers from the same dra wbacks as the joint training described above. Instead of ha ving a network that is jack of all trades and master of none, we stress the need for ha ving dif ferent specialist or expert models for dif ferent tasks, as also advocated in [13, 16, 31]. Therefore we build a Network of Experts, where a new expert model is added whenev er a ne w task arri ves and kno wledge is transferred from previous models. W ith an increasing number of task specializations, the number of expert models increases. Modern GPUs, used to speed up training and testing of neural nets, have limited memory (compared to CPUs), and can only load a relativ ely small number of models at a time. W e obviate the need for loading all the models by learning a gating mechanism that uses the test sample to decide which expert to activ ate ( see Figure 1 ). For this reason, we call our method Expert Gate . Unlike [17], who train one Uber network for performing vision tasks as di verse as semantic se gmentation, object de- tection and human body part detection, our work focuses on tasks with a similar objectiv e. For example, imagine a drone trained to fly through an en vironment using its frontal cam- era. For optimal performance, it needs to deploy different models for different en vironments such as indoor , outdoor or forest. Our gating mechanism then selects a model on the fly based on the input video. Another application could be a visual question answering system, that has multiple mod- els trained using images from dif ferent domains. Here too, our gating mechanism could use the data itself to select the associated task model. Even if we could deploy all the models simultaneously , selecting the right expert model is not straightforward. Just using the output of the highest scoring expert is no guaran- tee for success as neural networks can erroneously gi ve high confidence scores, as sho wn in [27]. W e also demonstrate this in our experiments. T raining a discriminativ e classifier to distinguish between tasks is also not an option since that would ag ain require storing all training data. What we need is a task recognizer that can tell the relev ance of its associ- ated task model for a gi ven test sample. This is e xactly what our gating mechanism pro vides. In fact, also the prefrontal cortex of the primate brain is considered to have neural rep- resentations of task context that act as a gating in different brain functions [23]. W e propose to implement such task recognizer using an undercomplete autoencoder as a gating mechanism. W e learn for each new task or domain, a gating function that captures the shared characteristics among the training sam- ples and can recognize similar samples at test time. W e do so using a one layer under -complete autoencoder . Each autoencoder is trained along with the corresponding ex- pert model and maps the training data to its own lower di- mensional subspace. At test time, each task autoencoder projects the sample to its learned subspace and measures the reconstruction error due to the projection. The autoencoder with the lo west reconstruction error is used like a switch, selecting the corresponding expert model (see Figure 1). Interestingly , such autoencoders can also be used to ev al- uate task r elatedness at training time, which in turn can be used to determine which prior model is more relev ant to a new task. W e show how , based on this information, Expert Gate can decide which specialist model to transfer knowl- edge from when learning a new task and whether to use fine-tuning or learning-without-forgetting [21]. T o summarize, our contributions are the follo wing. W e dev elop Expert Gate, a lifelong learning system that can se- quentially deal with new tasks without storing all pre vious data. It automatically selects the most related prior task to aid learning of the ne w task. At test time, the appropriate model is loaded automatically to deal with the task at hand. W e e valuate our g ating network on image classification and video prediction problems. The rest of the paper is or ganized as follo ws. W e dis- cuss related work in Section 2. Expert Gate is detailed in Section 3, follo wed by experiments in Section 4. W e finish with concluding remarks and future work in Section 5. 2. Related W ork Multi-task learning Our end goal is to develop a system that can reach expert lev el performance on multiple tasks, with tasks learned sequentially . As such, it lies at the inter- section between multi-task learning and lifelong learning. Standard multi-task learning [5] aims at learning multiple tasks in a joint manner . The objective is to use knowledge from dif ferent tasks, the so called inducti ve bias [25], in or - der to improve performance on individual tasks. Often one shared model is used for all tasks. This has the benifit of relaxing the number of required samples per task but could lead to suboptimal performance on the indi vidual tasks. On the other hand, multiple models can be learned, that are each optimal for their own task, but utilize inductiv e bias / knowl- edge from other models [5]. T o determine which related tasks to utilize, [35] cluster the tasks based on the mutual information gain when using the information from one task while learning another . This is an exhausti ve process. As an alternati ve, [15, 38, 19] as- sume that the parameters of related task models lie close by in the original space or in a lower dimensional subspace and thus cluster the tasks’ parameters. They first learn task models independently , then use the tasks within the same cluster to help improving or relearning their models. This requires learning individual task models first. Alternativ ely , we use our tasks autoencoders, that are fast to train, to iden- tify related tasks. Multiple models for multiple tasks One of the first ex- amples of using multiple models, each one handling a sub- set of tasks, was by Jacobs et al. [16]. They trained an adap- tiv e mixture of experts (each a neural network) for multi- speaker v owel recognition and used a separate gating net- work to determine which network to use for each sample. They sho wed that this setup outperformed a single shared model. A downside, ho we ver , was that each training sam- ple needed to pass through each expert, for the g ating func- tion to be learned. T o av oid this issue, a mixture of one generalist model and man y specialist models has been pro- posed [1, 13]. At test time, the generalist model acts as a gate, forwarding the sample to the correct network. How- ev er , unlike our model, these approaches require all the data to be a vailable for learning the generalist model, which needs to be retrained each time a new task arri ves. Lifelong lear ning without catastrophic f orgetting In sequential lifelong learning, knowledge from pre vious tasks is le veraged to improve the training of ne w tasks, while tak- ing care not to forget old tasks, i.e. pre venting catastrophic forgetting [12]. Our system ob viates the need for storing all the training data collected during the lifetime of an agent, by learning task autoencoders that learn the distribution of the task data, and hence, also capture the meta-kno wledge of the task. This is one of the desired characteristics of a life- long learning system, as outlined by Silver et al. [33]. The constraint of not storing all previous training data has been looked at previously by Silver and Mercer [32]. They use the output of the previous task netw orks giv en new training data, called virtual samples, to re gularize the training of the networks for ne w tasks. This improves the ne w task perfor - mance by using the knowledge of the pre vious tasks. More recently , the Learning without For getting framework of [21] uses a similar regularization strategy , but learns a single net- work for all tasks: they finetune a pre viously trained net- work (with additional task outputs) for ne w tasks. The con- tribution of pre vious tasks/networks in the training of new networks is determined by task relatedness metrics in [32], while in [21], all pre vious knowledge is used, regardless of task relatedness. [21] demonstrates sequential training of a network for only two tasks. In our experiments, we sho w that the shared model gets worse when extended to more than two tasks, especially when task relatedness is lo w . Like us, two recent architectures, namely the progressi ve network [31] and the modular block network [34], also use multiple networks, a new one for each new task. They add new netw orks as additional columns with lateral connec- tions to the previous nets. These lateral connections mean that each layer in the ne w network is connected to not only its previous layer in the same column, b ut also to pre vious layers from all previous columns. This allows the networks to transfer knowledge from older to newer tasks. Ho wev er , in these works, choosing which column to use for a particu- lar task at test time is done manually , and the authors leave its automation as future work. Here, we propose to use an autoencoder to determine which model, and consequently column, is to be selected for a particular test sample. 3. Our Method W e consider the case of lifelong learning or sequential learning where tasks and their corresponding data come one after another . For each task, we learn a specialized model (expert) by transferring knowledge from pre vious tasks – in particular , we build on the most related pre vious task. Simultaneously we learn a gating function that captures the characteristics of each task. This g ate forwards the test data to the corresponding e xpert resulting in a high performance ov er all learned tasks. The question then is: how to learn such a gate function to differentiate between tasks, without having access to the training data of previous tasks? T o this end, we learn a lo w dimensional subspace for each task/domain. At test time we then select the representation (subspace) that best fits the test sample. W e do that using an undercomplete autoen- coder per task. Below , we first describe this autoencoder in more detail (Section 3.1). Next, we e xplain how to use them for selecting the most relev ant expert (Section 3.2) and for estimating task relatedness (Section 3.3). 3.1. The A utoencoder Gate An autoencoder [4] is a neural network that learns to produce an output similar to its input [11]. The network is composed of two parts, an encoder f = h ( x ) , which maps the input x to a code h ( x ) and a decoder r = g ( h ( x )) , that maps the code to a reconstruction of the input. The loss function L ( x, g ( h ( x ))) is simply the reconstruction er - ror . The encoder learns, through a hidden layer , a lower dimensional representation (undercomplete autoencoder) or a higher dimensional representation (overcomplete autoen- coder) of the input data, guided by regularization criteria to prev ent the autoencoder from copying its input. A linear autoencoder with a Euclidean loss function learns the same subspace as PCA. Howev er , autoencoders with non-linear functions yield better dimensionality reduction compared to PCA [14]. This moti vates our choice for this model. Autoencoders are usually used to learn feature represen- tations in an unsupervised manner or for dimensionality re- duction. Here, we use them for a dif ferent goal. The lower dimensional subspace learned by one of our undercomplete autoencoders will be maximally sensiti ve to variations ob- served in the task data but insensitiv e to changes orthogonal to the manifold. In other words, it represents only the vari- ations that are needed to reconstruct relev ant samples. Our Standardization Sigmoid Relu Sigmoid Preprocessing Step Decoding Encoding Loss:cross-entropy Figure 2. Our autoencoder gate structure. main hypothesis is that the autoencoder of one domain/task should thus be better at reconstructing the data of that task than the other autoencoders. Comparing the reconstruction errors of the different tasks’ autoencoders then allows to successfully forward a test sample to the most relev ant ex- pert network. It has been stated by [2] that in regularized (ov er-complete) autoencoders, the opposing forces between the risk and the re gularization term result in a score like be- havior for the reconstruction error . As a result, a zero recon- struction loss means a zero deriv ative which could be a local minimum or a local maximum. Howe ver , we use an unregu- larized one-layer under-complete autoencoder and for these, it has been shown [3, 24] that the mean squared error cri- terion we use as reconstruction loss estimates the neg ativ e log-likelihood. There is no need in such a one-layer autoen- coder to add a regularization term to pull up the energy on unseen data because the narro wness of the code already acts as an implicit regularizer . Prepr ocessing W e start from a rob ust image represen- tation x , namely the acti vations of the last con volutional layer of AlexNet pretrained on ImageNet. Before the en- coding layer, we pass this input through a preprocessing step, where the input data is standardized, followed by a sigmoid function. The standardization of the data, i.e. sub- tracting the mean and di viding the result by the standard deviation, is essential as it increases the rob ustness of the hidden representation to input v ariations. Normally , stan- dardization is done using the statistics of the data that a net- work is trained on, b ut in this case, this is not a good strat- egy . This is because, at test time, we compare the relati ve reconstruction errors of the dif ferent autoencoders. Differ - ent standardization regimes lead to non-comparable recon- struction errors. Instead, we use the statistics of Imagenet for the standardization of each autoencoder . Since this is a large dataset it gives a good approximation of the distrib u- tion of natural images. After standardization, we apply the sigmoid function to map the input to a range of [0 1] . Network architecture W e design a simple autoencoder that is no more complex than one layer in a deep model, with a one layer encoder/decoder (see Figure 2). The en- coding step consists of one fully connected layer followed by ReLU [39]. W e make use of ReLU activ ation units as they are fast and easy to optimize. ReLU also introduces sparsity in the hidden units which leads to better generaliza- tion. F or decoding, we use again one fully connected layer , but now followed by a sigmoid. The sigmoid yields values between [0 1] , which allo ws us to use cross entrop y as the loss function. At test time, we use the Euclidean distance to compute the reconstruction error . 3.2. Selecting the most rele vant expert At test time, and after learning the autoencoders for the different tasks, we add a softmax layer that takes as input the reconstruction errors er i from the different tasks autoen- coders giv en a test sample x . The reconstruction error er i of the i -th autoencoder is the output of the loss function gi ven the input sample x . The softmax layer gives a probability p i for each task autoencoder indicating its confidence: p i = exp ( − er i /t ) P j exp ( − er j /t ) (1) where t is the temperature. W e use a temperature v alue of 2 as in [13, 21] leading to soft probability values. Giv en these confidence v alues, we load the expert model associ- ated with the most confident autoencoder . For tasks that hav e some overlap, it may be con venient to acti vate more than one e xpert model instead of taking the max score only . This can be done by setting a threshold on the confidence values, see section 4.2. 3.3. Measuring task relatedness Giv en a new task T k associated with its data D k , we first learn an autoencoder for this task A k . Let T a be a previous task with associated autoencoder A a . W e w ant to measure the task relatedness between task T k and task T a . Since we do not have access to the data of task T a , we use the validation data from the current task T k . W e compute the av erage reconstruction error E r k on the current task data made by the current task autoencoder A k and, like wise, the av erage reconstruction error E r a made by the pre vious task autoencoder A a on the current task data. The relatedness between the two tasks is then computed: Rel ( T k , T a ) = 1 − ( E r a − E r k E r k ) (2) Note that the relatedness value is not symmetric. Applying this to e very previous task, we get a relatedness v alue to each previous task. W e exploit task relatedness in two ways. First, we use it to select the most related task to be used as prior model for learning the ne w task. Second, we exploit the lev el of task relatedness to determine which transfer method to use: fine- tuning or learning-without-forgetting (LwF) [21]. W e found in our e xperiments that LwF only outperforms fine-tuning Algorithm 1 Expert Gate T raining Phase input: expert-models ( E 1 , ., E j ) , tasks-autoencoders ( A 1 , ., A j ) , new task ( T k ), data ( D k ) ; output: E k 1: A k =train-task-autoencoder ( D k ) 2: ( rel,r el-val )=select-most-related-task( D k , A k , { A } ) 3: if rel-val > r el-th then 4: E k =LwF ( E rel , D k ) 5: else 6: E k =fine-tune ( E rel , D k ) 7: end if T est Phase input: x ; output: prediction 8: i =select-expert ( { A } , x ) 9: prediction = activ ate-expert ( E i , x ) when the two tasks are sufficiently related. When this is not the case, enforcing the new model to giv e similar outputs for the old task may actually hurt performance. Fine-tuning, on the other hand, only uses the previous task parameters as a starting point and is less sensiti ve to the level of task relatedness. Therefore, we apply a threshold on the task relatedness v alue to decide when to use LwF and when to fine-tune. Algorithm 1 shows the main steps of our Expert Gate in both training and test phase. 4. Experiments First, we compare our method against various baselines on a set of three image classification tasks (Section 4.1). Next, we analyze our g ate behavior in more detail on a big- ger set of tasks (Section 4.2), followed by an analysis of our task relatedness measure (Section 4.3). Finally , we test Expert Gate on a video prediction problem (Section 4.4). Implementation details W e use the activ ations of the last con volutional layer of an AlexNet pre-trained with Ima- geNet as image representation for our autoencoders. W e experimented with the size of the hidden layer in the au- toencoder , trying sizes of 10, 50, 100, 200 and 500, and found an optimal v alue of 100 neurons. This is a good com- promise between complexity and performance. If the task relatedness is higher than 0 . 85 , we use LwF; otherwise, we use fine-tuning. W e use the MatConvNet frame work [36] for all our experiments. 4.1. Comparison with baselines W e start with the sequential learning of three image clas- sification tasks: in order , we train on MIT Scenes [29] for scene classification, Caltech-UCSD Bir ds [37] for fine- grained bird classification and Oxford Flowers [28] for fine- grained flower classification. T o simulate a scenario in which an agent or robot has some prior knowledge, and is then e xposed to datasets in a sequential manner , we start of f T able 1. Classification accuracy for the sequential learning of 3 image classification tasks. Methods with * assume all pre vious training data is still a v ailable, while methods with ** use an oracle gate to select the proper model at test time. Method Scenes Birds Flowers avg Joint T raining* 63.1 58.5 85.3 68.9 Multiple fine-tuned models** 63.4 56.8 85.4 68.5 Multiple LwF models** 63.9 58.0 84.4 68.7 Single fine-tuned model 63.4 - - - 50.3 57.3 - - 46.0 43.9 84.9 58.2 Single LwF model 63.9 - - - 61.8 53.9 - - 61.2 53.5 83.8 66.1 Expert Gate (ours) 63.5 57.6 84.8 68.6 with an AlexNet model pre-trained on ImageNet. W e com- pare against the follo wing baselines: 1. A single jointly-trained model : Assuming all training data is alw ays av ailable, this model is jointly trained (by finetuning an AlexNet model pretrained on ImageNet) for all three tasks together . 2. Multiple fine-tuned models : Distinct AlexNet models (pretrained on ImageNet) are finetuned separately , one for each task. At test time, an oracle gate is used, i.e. a test sample is always e valuated by the correct model. 3. Multiple LwF models : Distinct models are learned with learning-without-forgetting [21], one model per ne w task, always using AlexNet pre-trained on ImageNet as previous task. This is again combined with an oracle gate. 4. A single fine-tuned model : one AlexNet model (pre- trained on ImageNet) sequentially fine-tuned on each task. 5. A single LwF model : LwF sequentially applied to mul- tiple tasks. Each new task is learned with all the outputs of the pre vious network as soft targets for the new train- ing samples. So, a network (pre-trained on ImageNet) is first trained for T ask 1 data without forgetting ImageNet (i.e. using the pretrained AlexNet predictions as soft tar - gets). Then, this network is trained with T ask 2 data, now using ImageNet and T ask 1 specific layers outputs as soft targets; and so on. For baselines with multiple models (2 and 3), we rely on an oracle gate to select the right model at test time. So re- ported numbers for these are upper bounds of what can be achiev ed in practice. The same holds for baseline 1, as it assumes all pre vious training data is stored and av ailable. T able 1 shows the classification accurac y achieved on the test sets of the different tasks. For our Expert Gate system and for each ne w task, we first select the most related previ- ous task (including ImageNet) and then learn the ne w task expert model by transferring knowledge from the most re- lated task model, using LwF or finetuning. For the Single fine-tuned model and Single LwF model , we also report intermediate results in the sequen- tial learning. When learning multiple models (one per new task), LwF improv es over vanilla fine-tuning for Scenes and Birds, as also reported by [21] 1 . How- ev er , for Flowers, performance degrades compared to fine-tuning. W e measure a lower degree of task re- latedness to ImageNet for Flowers than for Birds or Scenes (see Figure 3) which might explain this effect. I S F B F B S I 92.4% 86.5% 82.6% 81.4% 82.5% 78.8% Figure 3. T ask relatedness. First letters indicate tasks. Comparing the Single fine-tuned model (learned sequentially) with the Mul- tiple fine-tuned models , we observe an increasing drop in performance on older tasks: sequentially fine-tuning a single model for ne w tasks shows catas- trophic forgetting and is not a good strate gy for lifelong learning. The Single LwF model is less sensiti ve to for getting on pre vious tasks. Howe ver , it is still inferior to training exclusi ve models for those tasks ( Multiple fine-tuned / LwF models ), both for older as well as newer tasks. Lower performance on previous tasks is because of a buildup of errors and degradation of the soft tar gets of the older tasks. This results in LwF failing to compensate for for getting in a sequence in volving more than 2 tasks. This also adds noise in the learning process of the new task. Further , the previous tasks have varying de gree of task relatedness. On these datasets, we systematically observ ed the lar gest task relatedness values for ImageNet (see Figure 3). T reating all the tasks equally prev ents the new task from getting the same benefit of ImageNet as in the Multiple LwF models setting. Our Expert Gate always correctly identifies the most related task, i.e. ImageNet. Based on the relatedness degree, it used LwF for Birds and Scenes, while fine-tuning was used for Flowers. As a result, the best expert models were learned for each task. At test time, our gate mechanism succeeds to select the correct model for 99 . 2% of the test samples. This leads to superior results to those achie ved by the other two sequential learning strategies ( Single fine-tuned model and Single LwF model ). W e achieve comparable performance on average to the J oint T raining that has access to all the tasks data. Also, performance is on par with Multiple fine-tuned models or Multiple LwF models that both assume having the task label for acti vating the associated model. 4.2. Gate Analysis The goal of this experiment is to further ev aluate our Ex- pert Gate’ s ability in successfully selecting the rele vant net- work(s) for a gi ven test image. For this experiment, we add 3 more tasks: Stanford Cars dataset [18] for fine-grained car 1 Note these numbers are not identical to [21] but show similar trends. At the time of experimentation, the code for LwF was not av ailable, so we implemented this ourselves in consultation with the authors of [21], and used parameters provided by them. classification, FGVC- Air craft dataset [22] for fine-grained classification of aircraft, and V OC Actions , the human ac- tion classification subset of VOC challenge 2012 [9]. This last dataset has multi-label annotations. For sake of consis- tency , we only use the actions with single label. For these newly added datasets, we use the bounding boxes instead of the full images as the images might contain more than one object. So in total we deal with 6 different tasks: Scenes, Birds, Flo wers, Cars, Aircrafts, and Actions, along with Im- ageNet that is considered as a generalist model or initial pre-existing model. W e compare again with J oint T raining , where we fine- tune the ImageNet pre-trained Ale xNet jointly on the six tasks assuming all the data is av ailable. W e also compare with a setting with multiple fine-tuned models where the model with the maximum score is selected ( Most confident model ). For our Expert Gate, we follow the same regime as in the pre vious experiment. The most related task is always ImageNet. Based on our task relatedness threshold, LwF was selected for Actions, while Aircrafts and Cars were fine-tuned. T able 2 shows the results. Even though the jointly trained model has been trained on all the previous tasks data simultaneously , its av erage performance is inferior to our Expert Gate system. This can be explained by the negativ e inducti ve bias where some tasks neg ativ ely af fect others, as is the case for Scenes and Cars. As we explained in the Introduction, deploying all mod- els and taking the max score ( Most confident model ) is not an option: for many test samples the most confident model is not the correct one, resulting in poor performance. Ad- ditionally , with the size of each e xpert model around 220 MB and the size of each autoencoder around 28 MB, there is almost an order of magnitude dif ference in memory re- quirements. Comparison with a discriminative classifier Finally , we compare with a discriminati ve classifier trained to pre- dict the task. For this classifier, we first assume that all data from the pre vious tasks are stored, e ven though this is not in line with a lifelong learning setup. Thus, it serves as an up- per bound. For this classifier ( Discriminative T ask Classi- fier ) we use a neural net with one hidden layer composed of 100 neurons (same as our autoencoder code size). It takes as input the same data representation as our autoencoder gate and its output is the different tasks labels. T able 3 compares the performance of our gate on recognizing each task data to that of the discriminati ve classifier . Further, we test the sce- nario of a discriminativ e classifier with the number of stored samples per task v arying from 10-2000 (Figure 5). It ap- proaches the accuracy of our gate with 2000 samples. Note that this is 1 2 to 1 3 of the size of the used datasets. For larger datasets, an e ven higher number of samples would proba- bly be needed to match performance. In spite of not having T able 2. Classification accuracy for the sequential learning of 6 tasks. Method with * assumes all the training data is av ailable. Method Scenes Birds Flowers Cars Aircrafts Actions avg Joint T raining* 59.5 56.0 85.2 77.4 73.4 47.6 66.5 Most confident model 40.4 43.0 69.2 78.2 54.2 8.2 48.7 Expert Gate 60.4 57.0 84.4 80.3 72.2 49.5 67.3 T able 3. Results on discriminating between the 6 tasks (classification accuracy) Method Scenes Birds Flowers Cars Aircrafts Actions avg Discriminativ e T ask Classifier - using all the tasks data 97.0 98.6 97.9 99.3 98.8 95.5 97.8 Expert Gate (ours) - no access to the pr evious tasks data 94.6 97.9 98.6 99.3 97.6 98.1 97.6 access to any of the previous tasks data, our Expert Gate achiev es similar performance to the discriminati ve classi- fier . In fact, our Expert Gate can be seen as a sequential classifier with new classes arriving one after another . This is one of the most important results from this paper: with- out ever having simultaneous access to the data of differ ent tasks, our Expert Gate based on autoencoders manages to assign test samples to the r elevant tasks equally accurately as a discriminative classifier . Figure 4 shows some of the fe w confusion cases for our Expert Gate. For some test samples e ven humans hav e a hard time telling which expert should be activ ated. For ex- ample, Scenes images containing humans can also be clas- sified as Actions. T o deal with such cases, it may be prefer - able in some settings to allo w more than one expert to be activ ated. This can be done by setting a threshold on the probabilities for the different tasks. W e tested this scenario with a threshold of 0.1 and observed 3 . 7% of the test sam- ples being analyzed by multiple expert models. Note that in this case we can only e valuate the label gi ven by the cor - responding task as we are missing the ground truth for the other possible tasks appearing in the image. This leads to an av erage accuracy of 68 . 2% , i.e. a further increase of 0 . 9% . 4.3. T ask Relatedness Analysis In the previous cases, the most related task w as alw ays Imagenet. This is due to the similarity between the im- ages of these different tasks and those of Imagenet. Also, the wide di versity of Imagenet classes enables it to cov er a good range of these tasks. Does this mean that Ima- genet should be the only task to transfer knowledge from, regardless of the current task nature? T o answer this ques- tion, we add three more different tasks to our previous bas- ket: the Google Street V ie w House Numbers SVHN [26] for digit recognition, the Chars74K dataset [8] for charac- ter recognition in natural images ( Letters ), and the Mnist dataset [20] for handwritten digits. For Chars74K, we use the English set and exclude the digits, considering only the characters. From the pre vious set, we pick the two most related tasks, Actions and Scenes, and the two most unre- lated tasks, Cars and Flowers. W e focus on LwF [21] as a method for knowledge transfer . W e also consider ImageNet as a possible source. W e consider the following knowl- edge transfer cases: Scenes → Actions, ImageNet → Ac- tions, SVHN → Letters, ImageNet → Letters, SVHN → Mnist, ImageNet → Mnist, Flowers → Cars and Imagenet → Cars. Figure 6 sho ws the performance of LwF compared to fine-tuning the tasks with pre-trained AlexNet (indicated by ”Only X”) along with the de gree of task relatedness. The red line indicates the threshold of 0 . 85 task relatedness used in our previous e xperiments. In the case of a high score for task relatedness, the LwF uses the kno wledge from the pre vious task and improv es performance on the target task – see e.g. (SVHN → Letter , Scenes → Actions, ImageNet → Actions). When the tasks are less related, the method fails to improv e and starts to de- grade its performance, as in (Imagenet → Letters, SVHN → Mnist). When the tasks are highly unrelated, LwF can even fail to reach a good performance for the new task, as in the case of (Imagenet → Cars, Flowers → Cars). This can be explained by the f act that each task is pushing the shared parameters in a dif ferent direction and thus the model fails to reach a good local minimum. W e conclude that our gate autoencoder succeeds to pr edict when a task could help an- other in the LwF frame work and when it cannot . 4.4. V ideo Prediction Next, we ev aluate our Expert Gate for video prediction in the context of autonomous dri ving. W e use a state of the art system for video prediction, the Dynamic Filter Net- work (DFN) [7]. Gi ven a sequence of 3 images, the task for the network is to predict the ne xt 3 images. This is quite a structured task, where the task en vironment and training data affect the prediction results quite significantly . An au- tonomous vehicle that uses video prediction needs to be able to load the correct model for the current en vironment. It might not have all the data from the beginning, and so it becomes important to learn specialists for each type of en- vironment, without the need for storing all the training data. Even when all data is av ailable, joint training does not give the best results on each domain, as we show belo w . W e sho w experiments conducted on three domains/tasks: for Highway , we use the data from DFN [7], with the same train/test split; for Residential data, we use the two longest sequences from the KITTI dataset [10]; and for City data, we use the Stuttgart sequence from the CityScapes dataset Scenes as Flowers Birds as Scenes Flowers as Birds Cars as Aircrafts Aircrafts as Cars Actions as Birds Figure 4. Examples of confusion cases made by our Expert Gate. 100% 95% 90% 85% 80% 75% 70% 10 30 50 100 500 1000 2000 Number of samples Accuracy Discriminative classifier Our gate Figure 5. Comparison between our gate and the discriminati ve classifier with varying number of stored samples per task. Figure 6. Relatedness analysis. The relatedness values are normal- ized for the sake of better visualization. The red line indicates our relatedness threshold value. [6], i.e. the only sequence in that dataset with densely sam- pled frames. W e use a 90/10 train/test split on both residen- tial and city datasets. W e train the 3 tasks using 3 dif fer- ent regimes: sequential training using a Single F ine-tuned Model , J oint T raining and Expert Gate . For video predic- tion, LwF does not seem applicable. In this experiment, we use the autoencoders only as gating function. W e do not use task relatedness. V ideo prediction results are expressed as the av erage pixel-wise L1-distance between predicted and ground truth images (lower is better), and sho wn in table 4. Similar trends are observ ed as for the image classifica- tion problem: sequential fine-tuning results in catastrophic forgetting, where a model fine-tuned on a new dataset de- teriorates on the original dataset after fine-tuning. Joint training leads to better results on each domain, but requires all the data for training. Our Expert Gate system giv es better results compared to both sequential and joint train- ing. These numbers are supported by qualitativ e results as well (Figure 7). Please refer to the supplementary materi- als for more figures. These experiments show the potential of our Expert Gate system for video prediction tasks in au- tonomous driving applications. T able 4. V ideo prediction results (av erage pixel L1 distance). For methods with * all the previous data needs to be a v ailable. Method Highway Residential City avg Single Fine-tuned Model 13.4 - - - 25.7 45.2 - - 26.2 50.0 17.3 31.1 Joint T raining* 14.0 40.7 16.9 23.8 Expert Gate (ours) 13.4 40.3 16.5 23.4 Figure 7. Qualitativ e results for video prediction. From left to right: last ground truth image (in a sequence of 3); predicted image using sequential fine-tuning and using Expert Gate. Examining the lane markers, we see that Expert Gate is visually superior . 5. Conclusions and Future W ork In the context of lifelong learning, most work has fo- cused on how to exploit knowledge from pre vious tasks and transfer it to a new task. Little attention has gone to the related and equally important problem of how to select the proper (i.e. most relev ant) model at test time. This is the topic we tackle in this paper . T o the best of our knowl- edge, we are the first to propose a solution that does not re- quire storing data from pre vious tasks. Surprisingly , Expert Gate’ s autoencoders can distinguish different tasks equally well as a discriminati ve classifier trained on all data. More- ov er , they can be used to select the most related task and the most appropriate transfer method during training. Com- bined, this giv es us a po werful method for lifelong learning, that outperforms not only the state-of-the-art but also joint training of all tasks simultaneously . Our current system uses only the most related model for knowledge transfer . As future w ork, we will e xplore the possibility of leveraging multiple related models for the training of new tasks – for instance, by exploring ne w strate- gies for balancing the contribution of the dif ferent tasks by their relatedness degree rather than just v arying the learn- ing rates. Also a mechanism to decide when to merge tasks with high relatedness degree rather than adding a ne w ex- pert model, seems an interesting research direction. Acknowledgment: The first author’ s PhD is funded by an FWO scholarship. W e are grateful for support from KU Leuven GOA project CAMETRON. The authors would like to thank Matthew B. Blaschko and Amal Rannen T riki for v aluable discussions. References [1] K. Ahmed, M. H. Baig, and L. T orresani. Network of ex- perts for large-scale image categorization. arXiv pr eprint arXiv:1604.06119 , 2016. [2] G. Alain and Y . Bengio. What re gularized auto-encoders learn from the data-generating distribution. Journal of Ma- chine Learning Resear ch , 15(1):3563–3593, 2014. [3] Y . Bengio et al. Learning deep architectures for ai. F ounda- tions and tr ends R in Machine Learning , 2(1):1–127, 2009. [4] H. Bourlard and Y . Kamp. Auto-association by multilayer perceptrons and singular v alue decomposition. Biological cybernetics , 59(4-5):291–294, 1988. [5] R. Caruana. Multitask learning. In Learning to learn , pages 95–133. Springer , 1998. [6] M. Cordts, M. Omran, S. Ramos, T . Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele. The cityscapes dataset for semantic urban scene understanding. In Pr oc. of the IEEE Conference on Computer V ision and P attern Recognition (CVPR) , 2016. [7] B. De Brabandere, X. Jia, T . T uytelaars, and L. V an Gool. Dynamic filter networks. arXiv pr eprint arXiv:1605.09673 , 2016. [8] T . E. de Campos, B. R. Bab u, and M. V arma. Character recognition in natural images. In Pr oceedings of the Interna- tional Confer ence on Computer V ision Theory and Applica- tions, Lisbon, P ortugal , February 2009. [9] M. Everingham, L. V an Gool, C. K. I. W illiams, J. W inn, and A. Zisserman. The P ASCAL V isual Object Classes Challenge 2012 (VOC2012) Results. http://www .pascal- network.or g/challenges/V OC/voc2012/workshop/inde x.html. [10] A. Geiger, P . Lenz, C. Stiller, and R. Urtasun. V ision meets robotics: The kitti dataset. The International Journal of Robotics Resear ch , page 0278364913491297, 2013. [11] I. Goodfello w , Y . Bengio, and A. Courville. Deep learning. Book in preparation for MIT Press, 2016. [12] I. J. Goodfellow , M. Mirza, D. Xiao, A. Courville, and Y . Bengio. An empirical in vestigation of catastrophic for- getting in gradient-based neural netw orks. arXiv preprint arXiv:1312.6211 , 2013. [13] G. Hinton, O. V inyals, and J. Dean. Distilling the kno wledge in a neural network. arXiv pr eprint arXiv:1503.02531 , 2015. [14] G. E. Hinton and R. R. Salakhutdinov . Reducing the dimensionality of data with neural networks. Science , 313(5786):504–507, 2006. [15] L. Jacob, J.-p. V ert, and F . R. Bach. Clustered multi-task learning: A con vex formulation. In Advances in neural in- formation pr ocessing systems , pages 745–752, 2009. [16] R. A. Jacobs, M. I. Jordan, S. J. Nowlan, and G. E. Hin- ton. Adaptive mixtures of local experts. Neural computation , 3(1):79–87, 1991. [17] I. Kokkinos. Ubernet: Training auniv ersal’con volutional neural network for low-, mid-, and high-le vel vision us- ing div erse datasets and limited memory . arXiv preprint arXiv:1609.02132 , 2016. [18] J. Krause, M. Stark, J. Deng, and L. Fei-Fei. 3d object rep- resentations for fine-grained categorization. In Proceedings of the IEEE International Confer ence on Computer V ision W orkshops , pages 554–561, 2013. [19] A. Kumar and H. Daume III. Learning task group- ing and ov erlap in multi-task learning. arXiv preprint arXiv:1206.6417 , 2012. [20] Y . LeCun, L. Bottou, Y . Bengio, and P . Haffner . Gradient- based learning applied to document recognition. Pr oceed- ings of the IEEE , 86(11):2278–2324, 1998. [21] Z. Li and D. Hoiem. Learning without for getting. In Eu- r opean Conference on Computer V ision , pages 614–629. Springer , 2016. [22] S. Maji, J. Kannala, E. Rahtu, M. Blaschko, and A. V edaldi. Fine-grained visual classification of aircraft. T echnical re- port, 2013. [23] V . Mante, D. Sussillo, K. V . Shenoy , and W . T . Ne wsome. Context-dependent computation by recurrent dynamics in prefrontal cortex. Nature , 503(7474):78–84, 2013. [24] Y . MarcAurelio Ranzato and L. B. S. C. Y . LeCun. A unified energy-based framew ork for unsupervised learning. In Pr oc. Confer ence on AI and Statistics (AI-Stats) , v olume 24, 2007. [25] T . M. Mitchell. The need for biases in learning gener - alizations . Department of Computer Science, Laboratory for Computer Science Research, Rutgers Univ . New Jersey , 1980. [26] Y . Netzer , T . W ang, A. Coates, A. Bissacco, B. W u, and A. Y . Ng. Reading digits in natural images with unsupervised fea- ture learning. 2011. [27] A. Nguyen, J. Y osinski, and J. Clune. Deep neural networks are easily fooled: High confidence predictions for unrecog- nizable images. In 2015 IEEE Confer ence on Computer V i- sion and P attern Recognition (CVPR) , pages 427–436. IEEE, 2015. [28] M.-E. Nilsback and A. Zisserman. Automated flo wer classi- fication over a lar ge number of classes. In Pr oceedings of the Indian Confer ence on Computer V ision, Graphics and Image Pr ocessing , Dec 2008. [29] A. Quattoni and A. T orralba. Recognizing indoor scenes. In Computer V ision and P attern Reco gnition, 2009. CVPR 2009. IEEE Confer ence on , pages 413–420. IEEE, 2009. [30] O. Russakovsky , J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy , A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei. ImageNet Large Scale V isual Recognition Challenge. International Journal of Computer V ision (IJCV) , 115(3):211–252, 2015. [31] A. A. Rusu, N. C. Rabinowitz, G. Desjardins, H. Soyer , J. Kirkpatrick, K. Ka vukcuoglu, R. Pascanu, and R. Had- sell. Progressi ve neural networks. arXiv pr eprint arXiv:1606.04671 , 2016. [32] D. L. Silver and R. E. Mercer . The task rehearsal method of life-long learning: Overcoming impoverished data. In Con- fer ence of the Canadian Society for Computational Studies of Intelligence , pages 90–101. Springer , 2002. [33] D. L. Silver , Q. Y ang, and L. Li. Lifelong machine learning systems: Beyond learning algorithms. In AAAI Spring Sym- posium: Lifelong Machine Learning , pages 49–55. Citeseer , 2013. [34] A. V . T erekhov , G. Montone, and J. K. ORegan. Kno wledge transfer in deep block-modular neural networks. In Confer - ence on Biomimetic and Biohybrid Systems , pages 268–279. Springer , 2015. [35] S. Thrun and J. OSulliv an. Clustering learning tasks and the selectiv e cross-task transfer of knowledge. In Learning to learn , pages 235–257. Springer , 1998. [36] A. V edaldi and K. Lenc. Matcon vnet: Con volutional neural networks for matlab . In Proceedings of the 23r d ACM inter- national conference on Multimedia , pages 689–692. A CM, 2015. [37] P . W elinder, S. Branson, T . Mita, C. W ah, F . Schroff, S. Be- longie, and P . Perona. Caltech-UCSD Birds 200. T echnical Report CNS-TR-2010-001, California Institute of T echnol- ogy , 2010. [38] Y . Xue, X. Liao, L. Carin, and B. Krishnapuram. Multi- task learning for classification with dirichlet process priors. Journal of Mac hine Learning Resear ch , 8(Jan):35–63, 2007. [39] M. D. Zeiler , M. Ranzato, R. Monga, M. Mao, K. Y ang, Q. V . Le, P . Nguyen, A. Senior , V . V anhoucke, J. Dean, et al. On rectified linear units for speech processing. In 2013 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing , pages 3517–3521. IEEE, 2013.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment