Automatic Keyword Extraction for Text Summarization: A Survey
In recent times, data is growing rapidly in every domain such as news, social media, banking, education, etc. Due to the excessiveness of data, there is a need of automatic summarizer which will be capable to summarize the data especially textual data in original document without losing any critical purposes. Text summarization is emerged as an important research area in recent past. In this regard, review of existing work on text summarization process is useful for carrying out further research. In this paper, recent literature on automatic keyword extraction and text summarization are presented since text summarization process is highly depend on keyword extraction. This literature includes the discussion about different methodology used for keyword extraction and text summarization. It also discusses about different databases used for text summarization in several domains along with evaluation matrices. Finally, it discusses briefly about issues and research challenges faced by researchers along with future direction.
💡 Research Summary
The surveyed paper addresses the growing need for automatic summarization of massive textual data by focusing on the pivotal role of automatic keyword extraction. It begins by outlining the information overload problem across domains such as news, social media, banking, and education, and argues that effective summarization must preserve essential content without sacrificing meaning. The authors categorize keyword extraction techniques into four major families: statistical, linguistic, graph‑based, and machine‑learning/deep‑learning approaches. Statistical methods (e.g., TF‑IDF, χ², information gain) are praised for simplicity and speed but criticized for ignoring contextual relationships. Linguistic approaches leverage morphological analysis, part‑of‑speech tagging, noun‑phrase extraction, and dependency parsing, offering higher semantic precision at the cost of language‑specific resources and limited multilingual transferability. Graph‑based models such as TextRank, LexRank, and PositionRank treat words or sentences as nodes and exploit co‑occurrence or semantic similarity edges, applying PageRank‑style algorithms to rank importance; recent extensions incorporate hyper‑graphs, multi‑level structures, and dynamic updates to improve robustness. Machine‑learning and deep‑learning methods, especially those built on pretrained Transformers (BERT, RoBERTa, GPT, T5), enable contextual understanding and joint extraction‑generation pipelines, often enhanced by reinforcement learning, multi‑task training, or fine‑tuning on domain‑specific corpora.
The survey then reviews the principal datasets employed in summarization research, including DUC and TAC (news articles with human‑written abstracts), CNN/DailyMail (article–highlight pairs), XSum (single‑sentence summaries), Multi‑News (multi‑document summarization), as well as specialized corpora from scientific literature (ArXiv, PubMed), legal texts, and social media platforms. For each corpus, the authors discuss domain characteristics, summary length constraints, and whether the task is extractive, abstractive, or hybrid.
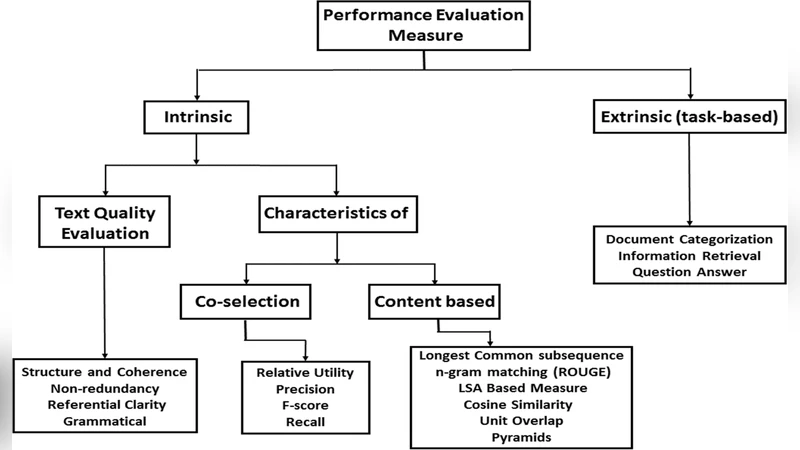
Evaluation metrics are examined in depth. Automatic measures such as ROUGE‑1/2/L, BLEU, METEOR, BERTScore, and MoverScore quantify n‑gram overlap or semantic similarity, while human assessments cover readability, informativeness, coherence, and compression ratio. The paper highlights a persistent gap between automatic scores and human judgments, urging the development of more reliable evaluation frameworks.
Key challenges identified include (1) difficulty in transferring models across domains due to vocabulary and style shifts, (2) limited multilingual generalization because many methods rely on language‑specific resources, (3) extractive summarizers often produce disjointed sentences that disrupt narrative flow, and (4) current metrics inadequately capture user satisfaction.
Future research directions proposed are: (a) multimodal summarization that integrates text with images or audio, (b) reinforcement‑learning‑driven policy optimization for better content selection, (c) explainable AI techniques to make keyword and summary decisions transparent to end‑users, (d) zero‑shot and few‑shot learning strategies for rapid domain adaptation, and (e) human‑in‑the‑loop interfaces that allow users to guide or correct summarization outcomes.
In conclusion, the paper affirms that automatic keyword extraction remains a cornerstone of effective text summarization, summarizing the state‑of‑the‑art methods, datasets, and evaluation practices while clearly delineating existing limitations and promising avenues for advancement. This comprehensive overview serves as a valuable roadmap for researchers aiming to develop more accurate, adaptable, and user‑friendly summarization systems.