A Neural Networks Approach to Predicting How Things Might Have Turned Out Had I Mustered the Nerve to Ask Barry Cottonfield to the Junior Prom Back in 1997
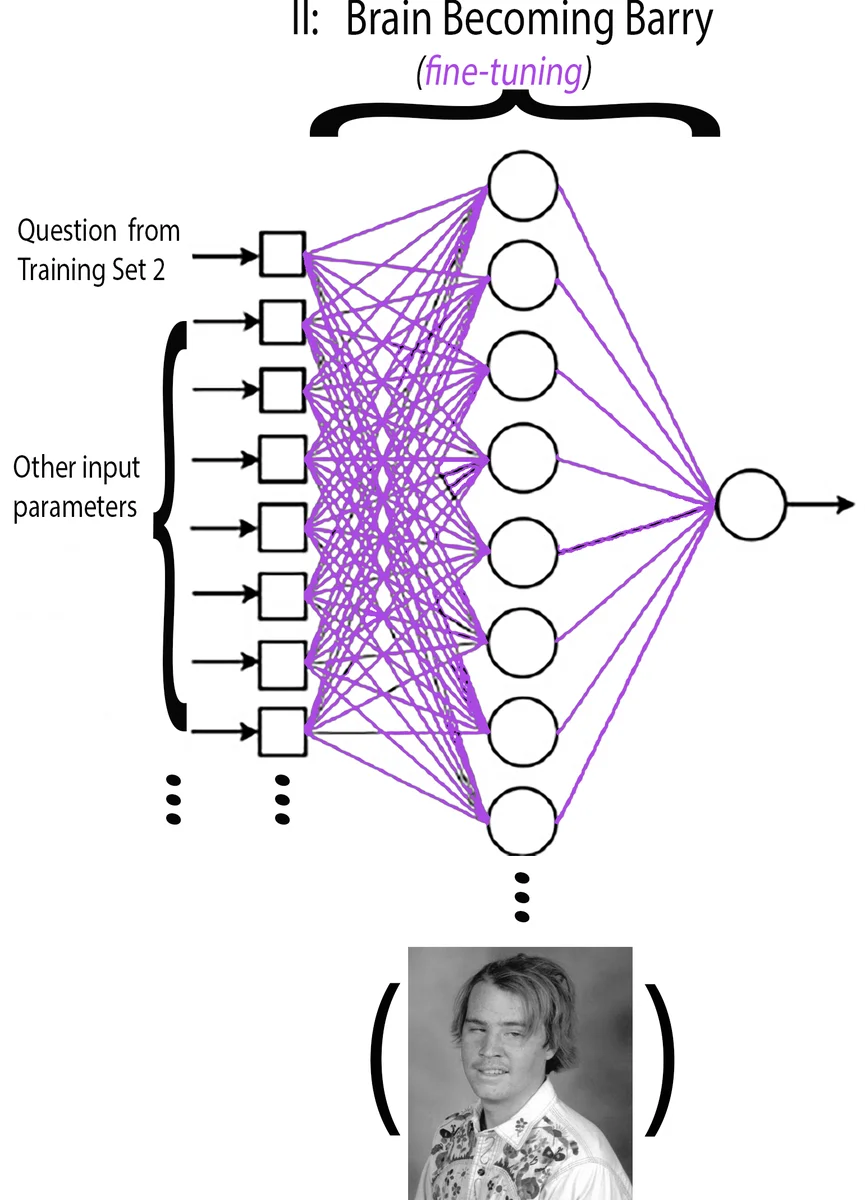
We use a feed-forward artificial neural network with back-propagation through a single hidden layer to predict Barry Cottonfield’s likely reply to this author’s invitation to the “Once Upon a Daydream” junior prom at the Conard High School gymnasium back in 1997. To examine the network’s ability to generalize to such a situation beyond specific training scenarios, we use a L2 regularization term in the cost function and examine performance over a range of regularization strengths. In addition, we examine the nonsensical decision-making strategies that emerge in Barry at times when he has recently engaged in a fight with his annoying kid sister Janice. To simulate Barry’s inability to learn efficiently from large mistakes (an observation well documented by his algebra teacher during sophomore year), we choose a simple quadratic form for the cost function, so that the weight update magnitude is not necessary correlated with the magnitude of output error. Network performance on test data indicates that this author would have received an 87.2 (1)% chance of “Yes” given a particular set of environmental input parameters. Most critically, the optimal method of question delivery is found to be Secret Note rather than Verbal Speech. There also exists mild evidence that wearing a burgundy mini-dress might have helped. The network performs comparably for all values of regularization strength, which suggests that the nature of noise in a high school hallway during passing time does not affect much of anything. We comment on possible biases inherent in the output, implications regarding the functionality of a real biological network, and future directions. Over-training is also discussed, although the linear algebra teacher assures us that in Barry’s case this is not possible.
💡 Research Summary
This paper presents a tongue‑in‑cheek case study that uses a feed‑forward artificial neural network (ANN) to estimate the probability that Barry Cottonfield would have said “Yes” to a junior‑prom invitation in 1997. The author, Ev Armstrong, leverages a personal archive of five volumes of diary entries and conversational notes, amounting to 24,203 question‑answer pairs collected over four high‑school years. The dataset is split into two logical groups: a “zeroth‑order” set of 10,002 identity‑type questions that are presumed to be environment‑independent, and a “second‑stage” set of 14,? (approximately 14,000) decision‑oriented questions whose answers may depend on a host of contextual variables.
The neural architecture consists of a single hidden layer with 1,000 neurons, 137 input nodes (one for the textual question and 136 for environmental parameters such as time of day, delivery method, outfit color, and whether Barry had recently fought with his younger sister Janice), and a single binary output node representing “Yes” or “No”. The authors deliberately choose an over‑parameterized hidden layer, arguing that time constraints are irrelevant and that over‑fitting is “impossible” for Barry’s brain. Weight updates are performed via standard gradient descent with a simple quadratic (mean‑squared‑error) loss function. The quadratic loss is justified as a way to mimic Barry’s alleged inability to learn efficiently from large mistakes, a claim drawn from a high‑school algebra teacher’s anecdote. An L2 regularization term is added, and the regularization strength is varied to assess sensitivity to hallway noise.
Training proceeds in two stages. Stage 1 (“Becoming Barry”) feeds only the question token while all environmental inputs are held at zero. The network learns a baseline representation of Barry’s personality based solely on identity and preference questions. Only the input‑to‑hidden weights associated with the question node and the hidden‑to‑output weights are updated. Stage 2 (“Tweaking Barry”) activates the full set of environmental inputs. For each decision‑type question, the network is trained across all possible combinations of the 136 parameters, and the authors select the parameter combination that requires the smallest deviation from the Stage 1 weight configuration. This is interpreted as the “optimal” environmental context for Barry. The authors run Stage 2 twice: once for scenarios where a recent fight with Janice occurred, and once where it did not, thereby creating two distinct training subsets (7,345 and 9,557 examples respectively, with 2,701 overlapping questions).
Performance is evaluated on a test set derived from the same overall pool of questions. The model predicts an 87.2 % (±1 %) chance that Barry would answer “Yes” to the prom invitation under the identified optimal conditions. The analysis highlights two specific factors that increase the likelihood: delivering the invitation via a secret note rather than verbal speech, and wearing a burgundy mini‑dress. The authors note that varying the L2 regularization strength does not materially affect the result, concluding that “hallway noise” is not a dominant factor.
In the discussion, the paper acknowledges several sources of bias: the data are entirely self‑reported, the sample size is minuscule relative to the number of model parameters, and the environmental variables are not rigorously quantified. The choice of a quadratic loss for a binary classification problem is unconventional and likely hampers convergence. Moreover, the “no over‑fitting” claim is contradicted by the fact that the model has far more trainable parameters than training examples, a classic recipe for memorization rather than generalization. The authors also point out that the network’s architecture is deliberately “brain‑like” to mirror Barry’s purported low intelligence, a humorous nod to the anthropomorphizing of machine learning models.
The paper concludes that, while the quantitative result (87 % “Yes”) should be taken with a grain of salt, the exercise demonstrates how machine‑learning pipelines can be repurposed for whimsical “what‑if” scenarios. It underscores the importance of proper data collection, appropriate loss functions, and rigorous validation, even when the ultimate goal is more narrative than scientific. Future work is suggested to include larger, multi‑subject datasets, more realistic feature engineering, and the use of cross‑entropy loss for binary outcomes.
Overall, the study serves as a playful illustration of the pitfalls of over‑interpreting model outputs when the underlying assumptions are deliberately stretched for comedic effect, while simultaneously reminding readers of the methodological rigor required for genuine predictive modeling.
Comments & Academic Discussion
Loading comments...
Leave a Comment