A Survey of Available Corpora for Building Data-Driven Dialogue Systems
During the past decade, several areas of speech and language understanding have witnessed substantial breakthroughs from the use of data-driven models. In the area of dialogue systems, the trend is less obvious, and most practical systems are still b…
Authors: Iulian Vlad Serban, Ryan Lowe, Peter Henderson
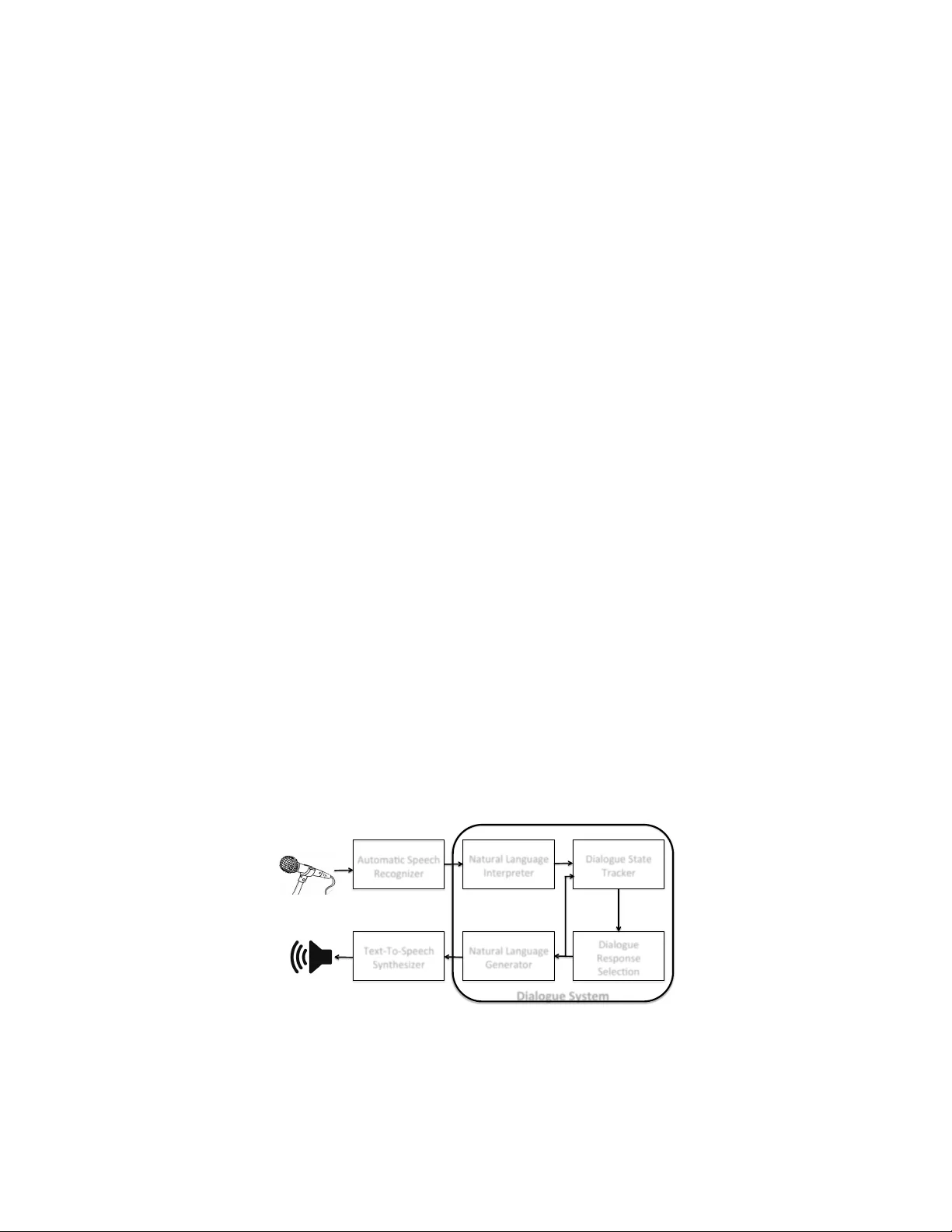
A Surv ey of A vailable Cor pora f or Building Data-Driv en Dialogue Systems Iulian Vlad Serban { I U LI A N . V L A D . S E R B A N } A T U M O N T R E A L D OT C A DIR O, Universit ´ e de Montr ´ eal 2920 chemin de la T our , Montr ´ eal, QC H3C 3J7, Canada Ryan Lowe { RY A N . L O W E } A T M A I L D OT M C G I L L D O T C A Department of Computer Science, McGill University 3480 University st, Montr ´ eal, QC H3A 0E9, Canada Peter Henderson { P E T E R . H E N D E R S O N } A T M A I L D O T M C G I L L D O T C A Department of Computer Science, McGill University 3480 University st, Montr ´ eal, QC H3A 0E9, Canada Laurent Charlin { L C H A R L I N } A T C S D OT M C G I L L D O T C A Department of Computer Science, McGill University 3480 University st, Montr ´ eal, QC H3A 0E9, Canada Joelle Pineau { J P I N E AU } A T C S D OT M C G I L L D O T C A Department of Computer Science, McGill University 3480 University st, Montr ´ eal, QC H3A 0E9, Canada Editor: David T raum Abstract During the past decade, several areas of speech and language understanding have witnessed sub- stantial breakthroughs from the use of data-driv en models. In the area of dialogue systems, the trend is less obvious, and most practical systems are still built through significant engineering and expert kno wledge. Nev ertheless, several recent results suggest that data-dri ven approaches are fea- sible and quite promising. T o facilitate research in this area, we have carried out a wide survey of publicly av ailable datasets suitable for data-dri ven learning of dialogue systems. W e discuss im- portant characteristics of these datasets, how they can be used to learn div erse dialogue strategies, and their other potential uses. W e also e xamine methods for transfer learning between datasets and the use of external knowledge. Finally , we discuss appropriate choice of ev aluation metrics for the learning objectiv e. 1. Introduction Dialogue systems, also known as interacti ve con versational agents, virtual agents or sometimes chatterbots, are useful in a wide range of applications ranging from technical support services to language learning tools and entertainment ( Y oung et al. , 2013 ; Shawar and Atwell , 2007b ). Lar ge- 1 scale data-driv en methods, which use recorded data to automatically infer knowledge and strategies, are becoming increasingly important in speech and language understanding and generation. Speech recognition performance has increased tremendously ov er the last decade due to innovations in deep learning architectures ( Hinton et al. , 2012 ; Goodfello w et al. , 2015 ). Similarly , a wide range of data- dri ven machine learning methods hav e been sho wn to be effecti ve for natural language processing, including tasks relev ant to dialogue, such as dialogue act classification ( Reithinger and Klesen , 1997 ; Stolcke et al. , 2000 ), dialogue state tracking ( Thomson and Y oung , 2010 ; W ang and Lemon , 2013 ; Ren et al. , 2013 ; Henderson et al. , 2013 ; Williams et al. , 2013 ; Henderson et al. , 2014c ; Kim et al. , 2015 ), natural language generation ( Langkilde and Knight , 1998 ; Oh and Rudnicky , 2000 ; W alker et al. , 2002 ; Ratnaparkhi , 2002 ; Stent et al. , 2004 ; Rieser and Lemon , 2010 ; Mairesse et al. , 2010 ; Mairesse and Y oung , 2014 ; W en et al. , 2015 ; Sharma et al. , 2016 ), and dialogue polic y learning ( Y oung et al. , 2013 ). W e hypothesize that, in general, much of the recent progress is due to the av ailability of lar ge public datasets, increased computing po wer , and ne w machine learning models, such as neural network architectures. T o facilitate further research on building data-driv en dialogue systems, this paper presents a broad surve y of a vailable dialogue corpora. Corpus-based learning is not the only approach to training dialogue systems. Researchers ha ve also proposed training dialogue systems online through li ve interaction with humans, and offline using user simulator models and reinforcement learning methods ( Le vin et al. , 1997 ; Georgila et al. , 2006 ; Paek , 2006 ; Schatzmann et al. , 2007 ; Jung et al. , 2009 ; Schatzmann and Y oung , 2009 ; Ga ˇ si ´ c et al. , 2010 , 2011 ; Daubigney et al. , 2012 ; Ga ˇ si ´ c et al. , 2012 ; Su et al. , 2013 ; Gasic et al. , 2013 ; Pietquin and Hastie , 2013 ; Y oung et al. , 2013 ; Mohan and Laird , 2014 ; Su et al. , 2015 ; Piot et al. , 2015 ; Cuay ´ ahuitl et al. , 2015 ; Hiraoka et al. , 2016 ; Fatemi et al. , 2016 ; Asri et al. , 2016 ; W illiams and Zweig , 2016 ; Su et al. , 2016 ). Howe ver , these approaches are beyond the scope of this surve y . This survey is structured as follo ws. In the ne xt section, we giv e a high-le vel overvie w of di- alogue systems. W e briefly discuss the purpose and goal of dialogue systems. Then we describe the indi vidual system components that are relev ant for data-driv en approaches as well as holistic end-to-end dialogue systems. In Section 3, we discuss types of dialogue interactions and aspects rele v ant to building data-driv en dialogue systems, from a corpus perspectiv e, as well as modalities recorded in each corpus (e.g. text, speech and video). W e further discuss corpora constructed from both human-human and human-machine interactions, corpora constructed using natural versus un- natural or constrained settings, and corpora constructed using works of fiction. In Section 4, we present our surv ey ov er dialogue corpora according to the cate gories laid out in Sections 2-3. In particular , we categorize the corpora based on whether dialogues are between humans or between a human and a machine, and whether the dialogues are in written or spoken language. W e discuss each corpus in turn while emphasizing ho w the dialogues were generated and collected, the topic of the dialogues, and the size of the entire corpus. In Section 5, we discuss issues related to: cor - pus size, transfer learning between corpora, incorporation of external kno wledge into the dialogue system, data-driven learning for contextualization and personalization, and automatic ev aluation metrics. W e conclude the surv ey in Section 6. 2. Characteristics of Data-Driven Dialogue Systems This section of fers a broad characterization of data-dri ven dialogue systems, which structures our presentation of the datasets. 2 2.1 An Overview of Dialogue Systems The standard architecture for dialogue systems, shown in Figure 1 , incorporates a Speech Rec- ognizer , Language Interpreter , State T racker , Response Generator , Natural Language Generator , and Speech Synthesizer . In the case of text-based (written) dialogues, the Speech Recognizer and Speech Synthesizer can be left out. While some of the literature on dialogue systems identifies only the State Track er and Response Selection components as belonging inside the dialogue man- ager ( Y oung , 2000 ), throughout this paper we adopt a broader view where language understanding and generation are incorporated within the dialogue system. This leaves space for the dev elopment and analysis of end-to-end dialogue systems ( Ritter et al. , 2011 ; V inyals and Le , 2015 ; Lowe et al. , 2015a ; Sordoni et al. , 2015b ; Shang et al. , 2015 ; Li et al. , 2015 ; Serban et al. , 2016 ; Serban et al. , 2017b , a ; Dodge et al. , 2015 ; W illiams and Zweig , 2016 ; W eston , 2016 ). W e focus on corpus-based data-dri ven dialogue systems. That is, systems composed of machine learning solutions using corpora constructed from real-world data. These system components ha ve v ariables or parameters that are optimized based on statistics observed in dialogue corpora. In particular , we focus on systems where the majority of variables and parameters are optimized. Such corpus-based data-driv en systems should be contrasted to systems where each component is hand- crafted by engineers — for e xample, components defined by an a priori fixed set of deterministic rules (e.g. W eizenbaum ( 1966 ); McGlashan et al. ( 1992 )). These systems should also be contrasted with systems learning online, such as when the free v ariables and parameters are optimized directly based on interactions with humans (e.g. Ga ˇ si ´ c et al. ( 2011 )). Still, it is w orth noting that it is possible to combine dif ferent types of learning within one system. For e xample, some parameters may be learned using statistics observed in a corpus, while other parameters may be learned through interactions with humans. While there are substantial opportunities to impro ve each of the components in Figure 1 through (corpus-based) data-driv en approaches, within this surv ey we focus primarily on datasets suitable to enhance the components inside the Dialogue System box. It is worth noting that the Natural Language Interpreter and Generator are core problems in Natural Language Processing with appli- cations well beyond dialogue systems. ! ! ! ! ! ! ! ! ! ! Dialogue!System! Automa'c)Speech) Recognizer) Natural)Language) Interpreter) Text:To:Speech) Synthesizer) Natural)Language) Generator) Dialogue)State) Tracker) Dialogue) Response) Selec'on) Figure 1: Dialogue System Diagram 3 2.2 T asks and objectives Dialogue systems hav e been built for a wide range of purposes. A useful distinction can be made between goal-dri ven dialogue systems, such as technical support services, and non-goal-driven dia- logue systems, such as language learning tools or computer game characters. Although both types of systems do in fact hav e objecti ves, typically the goal-dri ven dialogue systems have a well-defined measure of performance that is explicitly related to task completion. Non-goal-driven Dialogue Systems . Research on non-goal-dri ven dialogue systems goes back to the mid-60s. It began, perhaps, with W eizenbaum’ s f amous program ELIZA , a system based only on simple te xt parsing rules that managed to con vincingly mimic a Rogerian psychotherapist by persistently rephrasing statements or asking questions ( W eizenbaum , 1966 ). This line of research was continued by Colby ( 1981 ), who used simple text parsing rules to construct the dialogue system P ARRY , which managed to mimic the pathological behaviour of a paranoid patient to the extent that clinicians could not distinguish it from real patients. Howe ver , neither of these two systems used data-dri ven learning approaches. Later work, such as the Meg aHal system by Hutchens and Alder ( 1998 ), started to apply data-dri ven methods ( Sha war and Atwell , 2007b ). Hutchens and Alder ( 1998 ) proposed modelling dialogue as a stochastic sequence of discrete symbols (w ords) using 4 ’th order Markov chains. Gi ven a user utterance, their system generated a response by follo wing a two-step procedure: first, a sequence of topic keyw ords, used to create a seed reply , was ex- tracted from the user’ s utterance; second, starting from the seed reply , two separate Markov chains generated the words preceding and proceeding the seed ke ywords. This procedure produced many candidate responses, from which the highest entropy response was returned to the user . Under the assumption that the cov erage of dif ferent topics and general fluency is of primary importance, the 4 ’th order Markov chains were trained on a mixture of data sources ranging from real and fictiv e dialogues to arbitrary texts. Unfortunately , until very recently , such data-driv en dialogue systems were not applied widely in real-world applications ( Perez-Marin and Pascual-Nieto , 2011 ; Shawar and Atwell , 2007b ). P art of the reason for this might be due to their non-goal-driven nature, which made them hard to commercialize. Another barrier to commercialization might ha ve been the lack of theoretical and empirical understanding of such systems. Nevertheless, in a similar spirit o ver the past few years, neural network architectures trained on large-scale corpora hav e been in vestigated. These models ha ve demonstrated promising results for several non-goal-driven dialogue tasks ( Rit- ter et al. , 2011 ; V in yals and Le , 2015 ; Lo we et al. , 2015a ; Sordoni et al. , 2015b ; Shang et al. , 2015 ; Li et al. , 2015 ; Serban et al. , 2016 ; Serban et al. , 2017b , a ; Dodge et al. , 2015 ; Williams and Zweig , 2016 ; W eston , 2016 ). Howe ver , they require ha ving sufficiently lar ge corpora — in the hundreds of millions or e ven billions of w ords — in order to achiev e these results. Goal-driven Dialogue Systems . Initial work on goal-dri ven dialogue systems was primarily based on deterministic hand-crafted rules coupled with learned speech recognition models (e.g. of f- the-shelf speech recognition software). One example is the SUNDIAL project, which was capable of providing timetable information about trains and airplanes, as well as taking airplane reserv a- tions ( Aust et al. , 1995 ; McGlashan et al. , 1992 ; Simpson and Eraser , 1993 ). Later , machine learn- ing techniques were used to classify the intention (or need) of the user , as well as to bridge the gap between te xt and speech (e.g. by taking into account uncertainty related to the outputs of the speech recognition model) ( Gorin et al. , 1997 ). Research in this area started to take off during the mid 1990s, when researchers began to formulate dialogue as a sequential decision making problem based on Markov decision processes ( Singh et al. , 1999 ; Y oung et al. , 2013 ; Paek , 2006 ; Pieraccini 4 et al. , 2009 ). Unlike non-goal-dri ven systems, industry played a major role and enabled researchers to hav e access to (at the time) relativ ely large dialogue corpora for certain tasks, such as recordings from technical support call centres. Although research in the past decade has continued to push the field tow ards data-dri ven approaches, commercial systems are highly domain-specific and heavily based on hand-crafted rules and features ( Y oung et al. , 2013 ). In particular , many of the tasks and datasets av ailable are constrained to narrow domains. 2.3 Learning Dialogue System Components Modern dialogue systems consist of several components, as illustrated in Figure 1 . Se veral of the dialogue system components can be learned through so-called discriminativ e models, which aim to predict labels or annotations relev ant to other parts of the dialogue system. Discriminati ve models fall into the machine learning paradigm of supervised learning. When the labels of interest are discrete, the models are called classification models, which is the most common case. When the labels of interest are continuous, the models are called r e gression models. One popular approach for tackling the discriminati ve task is to learn a probabilistic model of the labels conditioned on the av ailable information P ( Y | X ) , where Y is the label of interest (e.g. a discrete v ariable representing the user intent) and X is the av ailable information (e.g. utterances in the con versation). Another popular approach is to use maximum margin classifiers, such as support vector machines ( Cristianini and Shawe-T aylor , 2000 ). Although it is beyond the scope of this paper to pro vide a survey over such system components, we now gi ve a brief example of each component. This will moti vate and facilitate the dataset analysis. Natural Language Interpr eter . An example of a discriminati ve model is the user intent clas- sification model, which acts as the Natural Language Interpreter . This model is trained to predict the intent of a user conditioned on the utterances of that user . In this case, the intent is called the label (or tar get or output ), and the conditioned utterances are called the conditioning variables (or inputs ). T raining this model requires examples of pairs of user utterances and intentions. One way to obtain these example pairs would be to first record written dialogues between humans carrying out a task, and then to ha ve humans annotate each utterance with its intention label. Depending on the complexity of the domain, this may require training the human annotators to reach a certain le vel of agreement between annotators. Dialogue State T racker . A Dialogue State T racker might similarly be implemented as a classi- fication model ( W illiams et al. , 2013 ). At an y gi ven point in the dialogue, such a model will tak e as input all the user utterances and user intention labels estimated by a Natural Language Interpreter model so far and output a distribution ov er possible dialogue states. One common way to represent dialogue states are through slot-value pairs. For example, a dialogue system providing timetable information for trains might ha ve three dif ferent slots: departur e city , arrival city , and departure time . Each slot may take one of sev eral discrete values (e.g. departur e city could take values from a list of city names). The task of the Dialogue State T racker is then to output a distribution o ver e very possible combination of slot-value pairs. This distrib ution — or alternati vely , the K dialogue states with the highest probability — may then be used by other parts of the dialogue system. The Dialogue State T racker model can be trained on e xamples of dialogue utterances and dialogue states labelled by humans. 5 Dialogue Response Selection . Giv en the dialogue state distribution provided by the Dialogue State T racker , the Dialogue Response Selection component must select the correct system response (or action). This component may also be implemented as a classification model that maps dialogue states to a probability over a discrete set of responses. For example, in a dialogue system provid- ing timetable information for trains, the set of responses might include pr oviding information (e.g. providing the departure time of the next train with a specific departure and arriv al city) and clarifi- cation questions (e.g. asking the user to re-state their departure city). The model may be trained on example pairs of dialogue states and responses. Natural Language Generator . Giv en a dialogue system response (e.g. a response providing the departure time of a train), the Natural Language Generator must output the natural language utterance of the system. This has often been implemented in commercial goal-driv en dialogue systems using hand-crafted rules. Another option is to learn a discriminative model to select a natural language response. In this case, the output space may be defined as a set of so-called surface form sentences (e.g. ”The r equested train leaves city X at time Y” , where X and Y are placeholder values). Gi ven the system response, the classification model must choose an appropriate surface form. Afterwards, the chosen surface form will have the placeholder values substituted in appropriately (e.g. X will be replaced by the appropriate city name through a database look up). As with other classification models, this model may be trained on example pairs of system responses and surface forms. Discriminati ve models hav e allowed goal-dri ven dialogue systems to make significant progress ( W illiams et al. , 2013 ). W ith proper annotations, discriminativ e models can be ev aluated automat- ically and accurately . Furthermore, once trained on a given dataset, these models may be plugged into a fully-deployed dialogue system (e.g. a classification model for user intents may be used as input to a dialogue state tracker). 2.4 End-to-end Dialogue Systems Not all dialogue systems conform to the architecture sho wn in Figure 1 . In particular , so-called end-to-end dialogue system architectures based on neural networks have sho wn promising results on se veral dialogue tasks ( Ritter et al. , 2011 ; V inyals and Le , 2015 ; Lo we et al. , 2015a ; Sordoni et al. , 2015b ; Shang et al. , 2015 ; Li et al. , 2015 ; Serban et al. , 2016 ; Serban et al. , 2017b , a ; Dodge et al. , 2015 ). In their purest form, these models take as input a dialogue in te xt form and output a response (or a distribution ov er responses). W e call these systems end-to-end dialogue systems because the y possess two important properties. First, the y do not contain or require learning an y sub-components (such as Natural Language Interpreters or Dialogue State T rackers). Consequently , there is no need to collect intermediate labels (e.g. user intention or dialogue state labels). Second, all model parameters are optimized w .r .t. a single objective function. Often the objectiv e function chosen is maximum log-likelihood (or cross-entropy) on a fixed corpus of dialogues. Although in the original formulation these models depended only on the dialogue context, the y may be extended to also depend on outputs from other components (e.g. outputs from the speech recognition tracker), and on external kno wledge (e.g. external databases). End-to-end dialogue systems can be divided into two categories: those that select deterministi- cally from a fix ed set of possible responses, and those that attempt to generate responses by keeping a posterior distrib ution over possible utterances. Systems in the first category map the dialogue his- tory , tracker outputs and external knowledge (e.g. a database, which can be queried by the system) 6 to a response action: f θ : { dialogue history , tracker outputs , external kno wledge } → action a t , (1) where a t is the dialogue system response action at time t , and θ is the set of parameters that defines f . Information retriev al and ranking-based systems — systems that search through a database of dialogues and pick responses with the most similar context, such as the model proposed by Banchs and Li ( 2012 ) — belong to this category . In this case, the mapping function f θ projects the dialogue history into a Euclidean space (e.g. using TF-IDF bag-of-words representations). The response is then found by projecting all potential responses into the same Euclidean space, and the response closest to the desirable response region is selected. The neural network proposed by Lo we et al. ( 2015a ) also belongs to this category . In this case, the dialogue history is projected into a Euclidean space using a recurrent neural network encoding the dialogue w ord-by-word. Similarly , a set of can- didate responses are mapped into the same Euclidean space using another recurrent neural network encoding the response word-by-word. Finally , a relev ance score is computed between the dialogue context and each candidate response, and the response with the highest score is returned. Hybrid or combined models, such as the model b uilt on both a phrase-based statistical machine translation system and a recurrent neural network proposed by Sordoni et al. ( 2015b ), also belong to this cate- gory . In this case, a response is generated by deterministically creating a fix ed number of answers using the machine translation system and then picking the response according to the score giv en by a a neural network. Although both of its sub-components are based on probabilistic models, the final model does not construct a probability distribution o ver all possible responses. 1 In contrast to a deterministic system, a generativ e system explicitly computes a full posterior probability distribution o ver possible system response actions at ev ery turn: P θ ( action a t | dialogue history , tracker outputs , external kno wledge ) . (2) Systems based on generativ e recurrent neural networks belong to this cate gory ( V inyals and Le , 2015 ). By breaking down eq. ( 2 ) into a product of probabilities over words, responses can be generated by sampling word-by-word from their probability distribution. Unlike the deterministic response models, these systems are also able to generate entirely nov el responses (e.g. by sampling word-by-word). Highly probable responses, i.e. the response with the highest probability , can fur - ther be generated by using a method known as beam-search ( Graves , 2012 ). These systems project each word into a Euclidean space (known as a word embedding) ( Bengio et al. , 2003 ); they also project the dialogue history and external kno wledge into a Euclidean space ( W en et al. , 2015 ; Lo we et al. , 2015b ). Similarly , the system proposed by Ritter et al. ( 2011 ) belongs to this category . Their model uses a statistical machine translation model to map a dialogue history to its response. When trained solely on text, these generative models can be vie wed as unsupervised learning models, because they aim to reproduce data distributions. In other w ords, the models learn to assign a prob- ability to every possible con versation, and since they generate responses word by word, they must learn to simulate the behaviour of the agents in the training corpus. Early reinforcement learning dialogue systems with stochastic policies also belong to this cat- egory (the NJFun system ( Singh et al. , 2002 ) is an example of this). In contrast to the neural network and statistical machine translation systems, these reinforcement learning systems typically 1. Although the model does not require intermediate labels, it consists of sub-components whose parameters are trained with different objecti ve functions. Therefore, strictly speaking, this is not an end-to-end model. 7 hav e very small sets of possible hand-crafted system states (e.g. hand-crafted features describing the dialogue state). The action space is also limited to a small set of pre-defined responses. This makes it possible to apply established reinforcement learning algorithms to train them either online or offline, howe ver it also sev erely limits their application area. As Singh et al. ( Singh et al. , 2002 , p.5) remark: “W e vie w the design of an appropriate state space as application-dependent, and a task for a skilled system designer . ” 3. Dialogue Interaction T ypes & Aspects This section provides a high-lev el discussion of dif ferent types of dialogue interactions and their salient aspects. The categorization of dialogues is useful for understanding the utility of v arious datasets for particular applications, as well as for grouping these datasets together to demonstrate av ailable corpora in a giv en area. 3.1 Written, Spoken & Multi-modal Corpora An important distinction between dialogue corpora is whether participants (interlocutors) interact through written language, spoken language, or in a multi-modal setting (e.g. using both speech and visual modalities). Written and spoken language dif fer substantially w .r .t. their linguistic properties. .Spoken language tends to be less formal, containing lower information content and man y more pronouns than written language ( Carter and McCarthy , 2006 ; Biber and Finegan , 2001 , 1986 ). In particular , the dif ferences are magnified when written language is compared to spoken face-to- face con versations, which are multi-modal and highly socially situated. As Biber and Finegan ( 1986 ) observ ed, pronouns, questions, and contradictions, as well as that-clauses and if-clauses, appear with a high frequency in face-to-f ace con versations. Forchini ( 2012 ) summarized these dif ferences: “... studies show that face-to-face con versation is interpersonal, situation-dependent has no narrative concern or as Biber and F ine gan (1986) put it, is a highly inter active, situated and immediate text type... ” Due to these differences between spoken and written language, we will emphasize the distinction between dialogue corpora in written and spok en language in the follo wing sections. Similarly , dialogues in volving visual and other modalities dif fer from dialogues without these modalities ( Card et al. , 1983 ; Goodwin , 1981 ). When a visual modality is av ailable — for example, when two human interlucators con verse face-to-face — body language and eye gaze has a significant impact on what is said and ho w it is said ( Gibson and Pick , 1963 ; Lord and Haith , 1974 ; Cooper , 1974 ; Chartrand and Bargh , 1999 ; de Kok et al. , 2013 ). Aside from the visual modality , dialogue systems may also incorporate other situational modalities, including aspects of virtual en vironments ( Rickel and Johnson , 1999 ; T raum and Rickel , 2002 ) and user profiles ( Li et al. , 2016 ). 3.2 Human-Human Vs. Human-Machine Corpora Another important distinction between dialogue datasets resides in the types of interlocutors — notably , whether it in volv es interactions between two humans, or between a human and a computer 2 . The distinction is important because current artificial dialogue systems are significantly constrained. 2. Machine-machine dialogue corpora are not of interest to us, because they typically differ significantly from natural human language. Furthermore, user simulation models are outside the scope of this survey . 8 These systems do not produce nearly the same distribution of possible responses as humans do under equi v alent circumstances. As stated by Williams and Y oung ( 2007 ): (Human-human con versation) does not contain the same distribution of understanding errors, and human–human turn-taking is much richer than human-machine dialog. As a result, human-machine dialogue exhibits v ery dif ferent traits than human-human dia- logue (Doran et al., 2001; Moore and Bro wning, 1992). The expectation a human interlucator begins with, and the interface through which they interact, also af fect the nature of the con versation ( J. and D. , 1988 ). For goal-driv en settings, W illiams and Y oung ( 2007 ) hav e pre viously ar gued against building data-dri ven dialogue systems using human-human dialogues: “... using human-human con versation data is not appr opriate because it does not contain the same distribution of understanding err ors, and because human-human turn-taking is much richer than human-machine dialog . ” This line of reasoning seems particularly applicable to spoken dialogue systems, where speech recognition errors can hav e a critical impact on performance and therefore must be taken into account when learning the dialogue model. The ar gument is also relev ant to goal-dri ven dialogue systems, where an effecti ve dialogue model can often be learned using reinforcement learning techniques. W illiams and Y oung ( 2007 ) also argue against learning from corpora generated between humans and existing dialogue systems: “While it would be possible to use a corpus collected fr om an existing spoken dialogue system, supervised learning would simply learn to appr oximate the policy used by that spoken dialogue system and an o verall performance impr ovement would ther efor e be unlikely . ” Thus, it appears, for goal-driven spoken dialogue systems in particular , that the most effecti ve strategy is learning online through interaction with real users. Nonetheless, there e xists useful human-machine corpora where the interacting machine uses a stochastic policy that can generate suf ficient coverage of the task (e.g. enough good and enough bad dialogue e xamples) to allo w an ef fecti ve dialogue model to be learned. In this case, the goal is to learn a policy that is eventually better than the original stochastic policy used to generate the corpus through a process known as bootstrapping. In this surve y we focus on data-driv en learning from human-human and human-machine di- alogue corpora. Despite the adv antages of learning online through interactions with real users, learning based on human-human dialogue corpora may be more suitable for open domain dialogue systems because they reflect natural dialogue interactions. By natural dialogues, we mean con ver - sations that are unconstrained and unscripted, e.g. between interlocutors who are not instructed to carry out a particular task, to follo w a series of instructions, or to act out a scripted dialogue. In this setting, the dialogue process is relati vely unaf fected by researchers, e.g. the interlocutors are not in- terrupted by question prompts in the middle of a dialogue. As can be expected, such con versations include a significant amount of turn-taking, pauses and common grounding phenomena ( Clark and Brennan , 1991 ). Additionally , the y are more di verse, and open up the possibility for the model to learn to understand natural language. 3.3 Natural Vs. Unnatural Corpora The way in which a dialogue corpus is generated and collected can have a significant influence on the trained data-dri ven dialogue system. In the case of human-human dialogues, an ideal corpus should closely resemble natural dialogues between humans. Arguably , this is the case when con versations 9 between humans are recorded and transcribed, and when the humans in the dialogue represent the true population of users with whom the dialogue system is intended to interact. It is ev en better if they are una ware of the fact that they are being recorded, b ut this is not al ways possible due to ethical considerations and resource constraints. Due to ethical considerations and resource constraints, researchers may be forced to inform the human interlocutors that they are being recorded or to setup artificial experiments in which they hire humans and instruct them to carry out a particular task by interacting with a dialogue system. In these cases, there is no guarantee that the interactions in the corpus will reflect true interactions, since the hired humans may behav e differently from the true user population. One factor that may cause behavioural differences is the fact that the hired humans may not share the same intentions and motiv ations as the true user population ( Y oung et al. , 2013 ). The unnaturalness may be further exacerbated by the hiring process, as well as the platform through which they interact. Such factors are becoming more prev alent as researchers increasingly rely on cro wdsourcing platforms, such as Amazon Mechanical T urk, to collect and ev aluate dialogue data ( Jurcıcek et al. , 2011 ). In the case of W izar d-of-Oz e xperiments ( Bohus and Rudnicky , 2008 ; Petrik , 2004 ), a human thinks (s)he is speaking to a machine, but a human operator is in fact controlling the dialogue system. This enables the generation of datasets that are closer in nature to the dialogues humans may wish to have with a good AI dialogue system. Unfortunately , such experiments are expensi ve and time- consuming to carry out. Ultimately the impact of any unnaturalness in the dialogues depends on the task and context in which the dialogue system is deplo yed. 3.4 Corpora from Fiction It is also possible to use artificial dialogue corpora for data-driven learning. This includes cor - pora based on works of fiction such as nov els, movie manuscripts and audio subtitles. Howe ver , unlike transcribed human-human con versations, nov els, movie manuscripts, and audio subtitles de- pend upon e vents outside the current con versation, which are not observed. This makes data-dri ven learning more dif ficult because the dialogue system has to account for unknown factors. The same problem is also observed in certain other media, such as microblogging websites (e.g. T witter and W eibo), where conv ersations also may depend on external unobserved e vents. Ne vertheless, recent studies ha ve found that spoken language in mo vies resembles spontaneous human spoken language ( F orchini , 2009 ). Although movie dialogues are explicitly written to be spoken and contain certain artificial elements, many of the linguistic and paralinguistic features contained within the dialogues are similar to natural spoken language, including dialogue acts such as turn-taking and reciprocity (e.g. returning a greeting when greeted). The artificial differences that exist may ev en be helpful for data-dri ven dialogue learning since movie dialogues are more compact, follo w a steady rhythm, and contain less garbling and repetition, all while still presenting a clear e vent or message to the vie wer ( Dose , 2013 ; Forchini , 2009 , 2012 ). Unlike dialogues extracted from W izar d-of-Oz human e xperiments, movie dialogues span many dif ferent topics and occur in many dif ferent en vironments ( W ebb , 2010 ). They contain dif ferent actors with different intentions and relationships to one another , which could potentially allow a data-dri ven dialogue system to learn to personalize itself to dif ferent users by making use of dif ferent interaction patterns ( Li et al. , 2016 ). 10 3.5 Corpus Size As in other machine learning applications such as machine translation ( Al-Onaizan et al. , 2000 ; G ¨ ulc ¸ ehre et al. , 2015 ) and speech recognition ( Deng and Li , 2013 ; Bengio et al. , 2014 ), the size of the dialogue corpus is important for building an effecti ve data-driv en dialogue ( Lowe et al. , 2015a ; Serban et al. , 2016 ). There are two primary perspectiv es on the importance of dataset size for building data-driv en dialogue systems. The first perspective comes from the machine learning literature: larger datasets place constraints on the dialogue model trained from that data. Datasets with fe w examples may require strong structural priors placed on the model, such as using a modular system, while large datasets can be used to train end-to-end dialogue systems with less a priori structure. The second comes from a statistical natural language processing perspectiv e: since the statistical complexity of a corpus grows with the linguistic div ersity and number of topics, the number of examples required by a machine learning algorithm to model the patterns in it will also grow with the linguistic di versity and number of topics. Consider two small datasets with the same number of dialogues in the domain of bus schedule information: in one dataset the con versations between the users and operator is natural, and the operator can improvise and chitchat; in the other dataset, the operator reads from a script to provide the bus information. Despite having the same size, the second dataset will have less linguistic di versity and not include chitchat topics. Therefore, it will be easier to train a data-dri ven dialogue system mimcking the behaviour of the operator in the second dataset, howe ver it will also exhibit a highly pedantic style and not be able to chitchat. In addition to this, to have an effecti ve discussion between any two agents, their common kno wledge must be represented and understood by both parties. The process of establishing this common knowledge, also known as gr ounding , is especially critical to repair misunderstandings between humans and dialogue systems ( Cahn and Brennan , 1999 ). Since the number of misunderstandings can gro w with the lexical di versity and number of topics (e.g. misunderstanding the paraphrase of an existing word, or misunderstanding a rarely seen k eyword), the number of examples required to repair these grow with linguistic diversity and topics. In particular , the effect of linguistic diversity has been observed in practice: V inyals and Le ( 2015 ) train a simple encoder-decoder neural network on a proprietary dataset of technical support dialogues. Although it has a similar size and purpose as the Ub untu Dialogue Corpus ( Lowe et al. , 2015a ), the qualitati ve e xamples shown by V inyals and Le ( 2015 ) are significantly superior to those obtained by more complex models on the Ubuntu Corpus ( Serban et al. , 2017a ). This result may likely be explained in part due to the fact that technical support operators often follow a comprehensi ve script for solving problems. As such, the script would reduce the linguistic di versity of their responses. Furthermore, since the majority of human-human dialogues are multi-modal and highly am- biguous in nature ( Chartrand and Bar gh , 1999 ; de K ok et al. , 2013 ), the size of the corpus may compensate for some of the ambiguity and missing modalities. If the corpus is sufficiently large, then the resolv ed ambiguities and missing modalities may , for example, be approximated using latent stochastic v ariables ( Serban et al. , 2017b ). Thus, we include corpus size as a dimension of analysis. W e also discuss the benefits and dra wbacks of se veral popular lar ge-scale datasets in Section 5.1 . 11 4. A vailable Dialogue Datasets There is a vast amount of data a v ailable documenting human communication. Much of this data could be used — perhaps after some pre-processing — to train a dialogue system. Howe ver , cov- ering all such sources of data w ould be infeasible. Thus, we restrict the scope of this surv ey to datasets that ha ve already been used to study dialogue or build dialogue systems, and to very large corpora of interactions—that may or may not be strictly considered dialogue datasets—which could be le veraged in the near future to b uild more sophisticated data-driv en dialogue models. W e restrict the selection further to contain only corpora generated from spoken or written English, and to cor- pora which, to the best of our knowledge, either are publicly av ailable or will be made av ailable in the near future. W e first giv e a brief ov ervie w of each of the considered corpora, and later high- light some of the more promising examples, explaining how they could be used to further dialogue research. 3 The dialogue datasets analyzed in this paper are listed in T ables 1 - 5 . Column features indicate properties of the datasets, including the number of dialogues, a verage dialogue length, number of words, whether the interactions are between humans or with an automated system, and whether the dialogues are written or spoken. Below , we discuss qualitati ve features of the datasets, while statistics can be found in the aforementioned table. 4.1 Human-Machine Corpora As discussed in Subsection 3.2 , an important distinction between dialogue datasets is whether they consist of dialogues between two humans or between a human and a machine. Thus, we begin by outlining some of the existing human-machine corpora in several categories based on the types of systems the humans interact with: Restaurant and T ravel Information, Open-Domain Knowledge Retrie v al, and Other Specialized systems. Note, we also include human-human corpora here where one human plays the role of the machine in a W izard-of-Oz fashion. 4 . 1 . 1 R E S TAU R A N T A N D T R A V E L I N F O R M A T I O N One common theme in human-machine language datasets is interaction with systems which provide restaurant or tra vel information. Here we’ll briefly describe some human-machine dialogue datasets in this domain. One of the most popular recent sources of such data has come from the datasets for structured dialogue prediction released in conjunction with the Dialog State T racking Challenge (DSTC) ( W illiams et al. , 2013 ). As the name implies, these datasets are used to learn a strategy for the Di- alogue State T racker (sometimes called ‘belief tracking’), which in volv es estimating the intentions of a user throughout a dialog. State tracking is useful as it can increase the robustness of speech recognition systems, and can pro vide an implementable framework for real-world dialogue sys- tems. Particularly in the context of goal-oriented dialogue systems (such as those providing tra vel and restaurant information), state tracking is necessary for creating coherent con versational inter- faces. As such, the first three datasets in the DSTC—referred to as DSTC1, DSTC2, and DSTC3 respecti vely—are medium-sized spoken datasets obtained from human-machine interactions with 3. W e form a live list of the corpora discussed in this work, along with links to downloads, at: http://breakend. github.io/DialogDatasets . Pull requests can be made to the Github repository ( https://github. com/Breakend/DialogDatasets ) hosting the website for continuing updates to the list of corpora. 12 restaurant and travel information systems. All datasets provide labels specifying the current goal and desired action of the system. DSTC1 ( W illiams et al. , 2013 ) features con versations with an automated b us information in- terface, where users request b us routes from the system and the system responds with clarifying queries or the desired information. DSTC2 introduces changing user goals in a restaurant booking system, while trying to pro vide a desired reserv ation( Henderson et al. , 2014b ). DSTC3 introduces a small amount of labelled data in the domain of tourist information. It is intended to be used in conjunction with the DSTC2 dataset as a domain adaptation problem ( Henderson et al. , 2014a ). The Car negie Mellon Communicator Corpus ( Bennett and Rudnick y , 2002 ) also contains human-machine interactions with a trav el booking system. It is a medium-sized dataset of interac- tions with a system providing up-to-the-minute flight information, hotel information, and car rentals. Con versations with the system were transcribed, along with the user’ s comments at the end of the interaction. The A TIS (Air T ravel Information System) Pilot Cor pus ( Hemphill et al. , 1990 ) is one of the first human-machine corpora. It consists of interactions, lasting about 40 minutes each, between human participants and a travel-type booking system, secretly operated by humans. Unlike the Carnegie Mellon Communicator Cor pus , it only contains 1041 utterances. In the Maluuba Frames Cor pus ( El Asri et al. , 2017 ), one user plays the role of a con versa- tional agent in a W izard-of-Oz fashion, while the other user is tasked with finding av ailable tra vel or v acation accommodations according to a pre-specified task. The W izard is provided with a kno wl- edge database which recorded their actions. Semantic frames are annotated in addition to actions which the W izard performed on the database to accompany a line of dialogue. In this way , the Frames corpus aims to track decision-making processes in tra vel- and hotel-booking through natu- ral dialog. 4 . 1 . 2 O P E N - D O M A I N K N OW L E D G E R E T R I E V A L Kno wledge retrie v al and Question & Answer (QA) corpora are a broad distinction of corpora that we will not extensiv ely re vie w here. Instead, we include only those QA corpora which explicitly record interactions of humans with existing systems. The Ritel corpus ( Rosset and Petel , 2006 ) is a small dataset of 528 dialogs with the Wizard-of-Oz Ritel platform. The project’ s purpose was to integrate spoken language dialogue systems with open-domain information retriev al systems, with the end goal of allowing humans to ask general questions and iterativ ely refine their search. The questions in the corpus mostly rev olve around politics and the economy , such as “Who is currently presiding the Senate?”, along with some con versations about arts and science-related topics. Other similar open-domain corpora in this area include W ikiQA Y ang et al. ( 2015 ) and MS MARCO Nguyen et al. ( 2016 ), which compile responses from automated Bing searches and hu- man annotators. Howe ver , these do not record dialogs, but rather simply gather possible responses to queries. As such, we won’ t discuss these datasets further , but rather mention them briefly as examples of other Open-Domain corpora in the field. 13 Name T ype T opics A vg. # T otal # T otal # Description of turns of dialogues of words DSTC1 ( W illiams et al. , 2013 ) Spoken Bus schedules 13.56 15,000 3.7M Bus ride information system DSTC2 ( Henderson et al. , 2014b ) Spoken Restaurants 7.88 3,000 432K Restaurant booking system DSTC3 ( Henderson et al. , 2014a ) Spoken T ourist information 8.27 2,265 403K Information for tourists CMU Communicator Corpus Spoken T rav el 11.67 15,481 2M* T rav el planning and booking system ( Bennett and Rudnicky , 2002 ) A TIS Pilot Corpus † Spoken T rav el 25.4 41 11.4K* T rav el planning and booking system ( Hemphill et al. , 1990 ) Ritel Corpus † Spoken Unrestricted/ Div erse T opics 9.3* 582 60k An annotated open-domain question ( Rosset and Petel , 2006 ) answering spoken dialogue system DIALOG Mathematical Spoken Mathematics 12 66 8.7K* Humans interact with computer system Proofs ( W olska et al. , 2004 ) to do mathematical theorem proving MA TCH Corpus † Spoken Appointment Scheduling 14.0 447 69K* A system for scheduling appointments. ( Georgila et al. , 2010 ) Includes dialogue act annotations Maluuba Frames † Chat, QA & T rav el & V acation 15 1369 – For goal-dri ven dialogue systems. ( El Asri et al. , 2017 ) Recommendation Booking Semantic frames labeled and actions taken on a kno wledge-base annotated. T able 1: Human-machine dialogue datasets. Starred (*) numbers are approximated based on the average number of words per utterance. Datasets marked with ( † ) indicate W izard-of-Oz dialogues, where the machine is secretly operated by a human. 14 Name T opics T otal # T otal # T otal Description of dialogues of words length HCRC Map T ask Corpus Map-Reproducing 128 147k 18hrs Dialogues from HLAP T ask in which speak ers must collaborate verbally ( Anderson et al. , 1991 ) T ask to reproduce on one participants map a route printed on the others. The W alking Around Corpus Location 36 300k* 33hrs People collaborating ov er telephone to find certain locations. ( Brennan et al. , 2013 ) Finding T ask Green Persuasiv e Database Lifestyle 8 35k* 4hrs A persuader with (genuinely) strong pro-green feelings tries to con vince ( Douglas-Cowie et al. , 2007 ) persuadees to consider adopting more green lifestyles. Intelligence Squared Debates Debates 108 1.8M 200hrs* V arious topics in Oxford-style debates, each constrained ( Zhang et al. , 2016 ) to one subject. Audience opinions provided pre- and post-debates. The Corpus of Professional Spoken Politics, Education 200 2M 220hrs* Interactions from faculty meetings and White House American English ( Barlow , 2000 ) press conferences. MAHNOB Mimicry Database Politics, Games 54 100k* 11hrs T wo experiments: a discussion on a political topic, and a ( Sun et al. , 2011 ) role-playing game. The IDIAP W olf Corpus Role-Playing Game 15 60k* 7hrs A recording of W ere wolf role-playing game with annotations ( Hung and Chittaranjan , 2010 ) related to game progress. SEMAINE corpus Emotional 100 450k* 50hrs Users were recorded while holding con versations with an operator ( McKeo wn et al. , 2010 ) Con versations who adopts roles designed to ev oke emotional reactions. DSTC4/DSTC5 Corpora T ourist 35 273k 21hrs T ourist information exchange o ver Sk ype. ( Kim et al. , 2015 , 2016 ) Loqui Dialogue Corpus Library Inquiries 82 21K 140* T elephone interactions between librarians and patrons. ( Passonneau and Sachar , 2014 ) Annotated dialogue acts, discussion topics, frames (discourse units), question-answer pairs. MRD A Corpus ICSI Meetings 75 11K* 72hrs Recordings of ICSI meetings. T opics include: the corpus project itself, ( Shriberg et al. , 2004 ) automatic speech recognition, natural language processing and theories of language. Dialogue acts, question-answer pairs, and hot spots. TRAINS 93 Dialogues Corpus Railroad Freight 98 55K 6.5hrs Collaborative planning of railroad freight routes. ( Heeman and Allen , 1995 ) Route Planning V erbmobil Corpus Appointment 726 270K 38Hrs Spontaneous speech data collected for the V erbmobil project. ( Burger et al. , 2000 ) Scheduling Full corpus is in English, German, and Japanese. W e only sho w English statistics. T able 2: Human-human constrained spoken dialogue datasets. Starred (*) numbers are estimates based on the average rate of English speech from the National Center for V oice and Speech ( www.ncvs.org/ncvs/tutorials/voiceprod/tutorial/quality.html ). 15 Name T opics T otal # T otal # T otal Description of dialogues of words length Switchboard ( Godfrey et al. , 1992 ) Casual T opics 2,400 3M 300hrs* T elephone con versations on pre-specified topics British National Corpus (BNC) Casual T opics 854 10M 1,000hrs* British dialogues many conte xts, from formal business or go vernment ( Leech , 1992 ) meetings to radio shows and phone-ins. CALLHOME American English Casual T opics 120 540k* 60hrs T elephone con versations between family members or close friends. Speech ( Canav an et al. , 1997 ) CALLFRIEND American English Casual T opics 60 180k* 20hrs T elephone conv ersations between Americans with a Southern accent. Non-Southern Dialect ( Canav an and Zipperlen , 1996 ) The Bergen Corpus of London Unrestricted 100 500k 55hrs Spontaneous teenage talk recorded in 1993. T eenage Language Con versations were recorded secretly . ( Haslerud and Stenstr ¨ om , 1995 ) The Cambridge and Nottingham Casual T opics – 5M 550hrs* British dialogues from wide v ariety of informal contexts, such as Corpus of Discourse in English hair salons, restaurants, etc. ( McCarthy , 1998 ) D64 Multimodal Con versation Corpus Unrestricted 2 70k* 8hrs Sev eral hours of natural interaction between a group of people ( Oertel et al. , 2013 ) AMI Meeting Corpus Meetings 175 900k* 100hrs Face-to-f ace meeting recordings. ( Renals et al. , 2007 ) Cardiff Con versation Database Unrestricted 30 20k* 150min Audio-visual database with unscripted natural con versations, (CCDb) ( Aubrey et al. , 2013 ) including visual annotations. 4D Cardiff Con versation Database Unrestricted 17 2.5k* 17min A version of the CCDb with 3D video (4D CCDb) ( V andev enter et al. , 2015 ) The Diachronic Corpus of Casual T opics 280 800k 80hrs* Selection of face-to-face, telephone, and public Present-Day Spoken English discussion dialogue from Britain. ( Aarts and W allis , 2006 ) The Spoken Corpus of the Casual T opics 314 800k 60hrs Dialogue of people aged 60 or abo ve talking about their memories, Surve y of English Dialects families, work and the folklore of the countryside from a century ago. ( Beare and Scott , 1999 ) The Child Language Data Unrestricted 11K 10M 1,000hrs* International database organized for the Exchange System study of first and second language acquisition. ( MacWhinney and Sno w , 1985 ) The Charlotte Narrativ e and Casual T opics 95 20K 2hrs* Narrati ves, con versations and intervie ws representativ e Con versation Collection (CNCC) of the residents of Mecklenbur g County , North Carolina. ( Reppen and Ide , 2004 ) T able 3: Human-human spontaneous spoken dialogue datasets. Starred (*) numbers are estimates based on the average rate of English speech from the National Center for V oice and Speech ( www.ncvs.org/ncvs/tutorials/voiceprod/tutorial/quality.html ) 16 Name T opics T otal # T otal # T otal # T otal # Description of utterances of dialogues of works of words Movie-DiC Movie 764k 132K 753 6M Movie scripts of American films. ( Banchs , 2012 ) dialogues Movie-T riples Movie 736k 245K 614 13M T riples of utterances which are filtered to come ( Serban et al. , 2016 ) dialogues from X-Y -X triples. Film Scripts Online Series Movie 1M* 263K † 1,500 16M* T wo subsets of scripts scripts (1000 American films and 500 mixed British/American films). Cornell Movie-Dialogue Corpus Movie 305K 220K 617 9M* Short con versations from film scripts, annotated ( Danescu-Niculescu-Mizil and Lee , 2011 ) dialogues with character metadata. Filtered Movie Script Corpus Mo vie 173k 87K 1,786 2M* Triples of utterances which are filtered to come ( Nio et al. , 2014b ) dialogues from X-Y -X triples. American Soap Opera TV show 10M* 1.2M † 22,000 100M T ranscripts of American soap operas. Corpus ( Davies , 2012b ) scripts TVD Corpus TV show 60k* 10K † 191 600k* TV scripts from a comedy (Big Bang Theory) and ( Roy et al. , 2014 ) scripts drama (Game of Thrones) show . Character Style from Film Movie 664k 151K 862 9.6M Scripts from IMSDb, annotated for linguistic Corpus ( W alker et al. , 2012a ) scripts structures and character archetypes. SubTle Corpus Movie 6.7M 3.35M 6,184 20M Aligned interaction-response pairs from ( Ameixa and Coheur , 2013 ) subtitles movie subtitles. OpenSubtitles Movie 140M* 36M † 207,907 1B Movie subtitles which are not speaker -aligned. ( T iedemann , 2012 ) subtitles CED (1560–1760) Corpus Written W orks – – 177 1.2M V arious scripted fictional works from (1560–1760) ( Kyt ¨ o and W alker , 2006 ) & T rial Proceedings as well as court trial proceedings. T able 4: Human-human scripted dialogue datasets. Quantities denoted with ( † ) indicate estimates based on a verage number of dialogues per movie ( Banchs , 2012 ) and the number of scripts or w orks in the corpus. Dialogues may not be explicitly separated in these datasets. TV show datasets were adjusted based on the ratio of average film runtime (112 minutes) to average TV sho w runtime (36 minutes). This data w as scraped from the IMBD database ( http://www.imdb.com/interfaces ). ( Starred (*) quantities are estimated based on the average number of words and utterances per film, and the av erage lengths of films and TV sho ws. Estimates deriv ed from the T ameri Guide for Writers ( http://www.tameri.com/format/wordcounts.html ). 17 Name T ype T opics A vg. # T otal # T otal # Description of turns of dialogues of words NPS Chat Corpus Chat Unrestricted 704 15 † 100M Posts from age-specific online chat rooms. ( Forsyth and Martell , 2007 ) T witter Corpus Microblog Unrestricted 2 1.3M 125M ‡ T weets and replies extracted from T witter ( Ritter et al. , 2010 ) T witter T riple Corpus Microblog Unrestricted 3 4,232 65K ‡ A-B-A triples extracted from T witter ( Sordoni et al. , 2015b ) UseNet Corpus Microblog Unrestricted 687 47860 † 7B UseNet forum postings ( Shaoul and W estb ury , 2009 ) NUS SMS Corpus SMS messages Unrestricted 18 3K 580,668* 2 SMS messages collected between two ( Chen and Kan , 2013 ) users, with timing analysis. Reddit ◦ Forum Unrestricted – – – 1.7B comments across Reddit. Reddit Domestic Abuse Corpus Forum Abuse help 17.53 21,133 19M-103M 4 Reddit posts from either domestic abuse ( Schrading et al. , 2015 ) subreddits, or general chat. Settlers of Catan Chat Game terms 95 21 – Con versations between players ( Afantenos et al. , 2012 ) in the game ‘Settlers of Catan. ’ Cards Corpus Chat Game terms 38.1 1,266 282K Con versations between players ( Djalali et al. , 2012 ) playing ‘Cards world. ’ Agreement in W ikipedia T alk Pages Forum Unrestricted 2 822 110K LiveJournal and W ikipedia Discussions forum threads. ( Andreas et al. , 2012 ) Agreement type and lev el annotated. Agreement by Create Debaters Forum Unrestricted 2 10K 1.4M Create Debate forum conv ersations. Annotated what type ( Rosenthal and McKeo wn , 2015 ) of agreement (e.g. paraphrase) or disagreement. Internet Argument Corpus F orum Politics 35.45 11K 73M Debates about specific ( W alker et al. , 2012b ) political or moral positions. MPC Corpus Chat Social tasks 520 14 58K Conv ersations about general, ( Shaikh et al. , 2010 ) political, and interview topics. Ubuntu Dialogue Corpus Chat Ubuntu Operating 7.71 930K 100M Dialogues extracted from ( Lowe et al. , 2015a ) System Ubuntu chat stream on IRC. Ubuntu Chat Corpus Chat Ub untu Operating 3381.6 10665 † 2B* 2 Chat stream scraped from ( Uthus and Aha , 2013 ) System IRC logs (no dialogues extracted). Movie Dialog Dataset Chat, QA & Movies 3.3 3.1M H 185M For goal-dri ven dialogue systems. Includes ( Dodge et al. , 2015 ) Recommendation movie metadata as knowledge triples. T able 5: Human-human written dialogue datasets. Starred (*) quantities are computed using word counts based on spaces (i.e. a word must be a sequence of characters preceded and followed by a space), but for certain corpora, such as IRC and SMS corpora, proper English words are sometimes concatenated together due to slang usage. Triangle ( 4 ) indicates lower and upper bounds computed using a verage words per utterance estimated on a similar Reddit corpus Schrading ( 2015 ). Square ( 2 ) indicates estimates based only on the English part of the corpus. Note that 2.1M dialogues from the Movie Dialog dataset ( H ) are in the form of simulated QA pairs. Dialogs indicated by ( † ) are contiguous blocks of recorded con versation in a multi-participant chat. In the case of UseNet, we note the total number of ne wsgroups and calculate the average turns as the av erage number of posts collected per newsgroup. ( ‡ ) indicates an estimate based on a T witter dataset of similar size and refers to tokens as well as words. ( ◦ ) refers to: https://www.reddit.com/r/datasets/comments/3bxlg7/i_have_every_publicly_available_reddit_ comment/ 18 4 . 1 . 3 O T H E R The DIALOG mathematical proof dataset ( W olska et al. , 2004 ) is a W izard-of-Oz dataset in- volving an automated tutoring system that attempts to advise students on proving mathematical theorems. This is done using a hinting algorithm that provides clues when students come up with an incorrect answer . At only 66 dialogues, the dataset is v ery small, and consists of a conglomeration of text-based interactions with the system, as well as think-aloud audio and video footage recorded by the users as they interacted with the system. The latter was transcribed and annotated with simple speech acts such as ‘signaling emotions’ or ‘self-addressing’. The MA TCH cor pus ( Geor gila et al. , 2010 ) is a small corpus of 447 dialogues based on a W izar d-of-Oz e xperiment, which collected 50 young and old adults interacting with spok en dialogue systems. These con versations were annotated semi-automatically with dialogue acts and “Informa- tion State Update” (ISU) representations of dialogue conte xt. The corpus also contains information about the users’ cogniti ve abilities, with the moti vation of modeling how the elderly interact with dialogue systems. 4.2 Human-Human Spoken Corpora Naturally , there is much more data av ailable for con versations between humans than conv ersations between humans and machines. Thus, we break do wn this category further , into spoken dialogues (this section) and written dialogues (Section 4.3 ). The distinction between spoken and written dia- logues is important, since the distrib ution of utterances changes dramatically according to the nature of the interaction. As discussed in Subsection 3.1 , spoken dialogues tend to be more colloquial and generally well-formed as the user speaks in train-of-thought manner; they also tend to use shorter words and phrases. Con versely , in written communication, users hav e the ability to reflect on what they are writing before they send a message. Written dialogues can also contain spelling errors or abbre viations, though, which are generally not transcribed in spoken dialogues. 4 . 2 . 1 S P O N T A N E O U S S P O K E N C O R P O R A W e first introduce datasets in which the topics of con versation are either casual, or not pre-specified in any w ay . W e refer to these corpora as spontaneous , as we believ e they most closely mimic spontaneous and unplanned spoken interactions between humans. Perhaps one of the most influential spoken corpora is the Switchboard dataset ( Godfrey et al. , 1992 ). This dataset consists of approximately 2,500 dialogues from phone calls, along with word- by-word transcriptions with about 500 total speakers. A computer -driven robot operator system introduced a topic for discussion between two participants, and recorded the resulting con versation. About 70 casual topics were provided, of which about 50 were frequently used. The corpus w as originally designed for training and testing v arious speech processing algorithms; ho we ver , it has since been used for a wide variety of other tasks, including the modeling of dialogue acts such as ‘statement’, ‘question’, and ‘agreement’ ( Stolcke et al. , 2000 ). Another important dataset is the British National Corpus (BNC) ( Leech , 1992 ), which contains approximately 10 million words of dialogue. These were collected in a variety of contexts ranging from formal business or go vernment meetings, to radio shows and phone-ins. Although most of the conv ersations are spoken in nature, some of them are also written. BNC cov ers a large number of sources, and was designed to represent a wide cross-section of British English from the late twentieth century . The corpus also includes part-of-speech (POS) tagging for ev ery word. The v ast 19 array of settings and topics covered by this corpus renders it very useful as a general-purpose spok en dialogue dataset. Other datasets hav e been collected for the analysis of spoken English over the telephone. The CALLHOME American English Speech Corpus ( Canav an et al. , 1997 ) consists of 120 such con versations totalling about 60 hours, mostly between family members or close friends. Similarly , the CALLFRIEND American English-Non-Souther n Dialect Corpus ( Cana v an and Zipperlen , 1996 ) consists of 60 telephone con versations lasting 5-30 minutes each between English speakers in North America without a Southern accent. It is annotated with speaker information such as sex, age, and education. The goal of the project was to support the dev elopment of language identification technologies, yet, there are no distinguishing features in either of these corpora in terms of the topics of con versation. An attempt to capture e xclusi vely teenage spoken language was made in the Bergen Corpus of London T eenager Language (COL T) ( Haslerud and Stenstr ¨ om , 1995 ). Con versations were recorded surreptitiously by student ‘recruits’, with a Sony W alkman and a lapel microphone, in order to obtain a better representation of teenager interactions ‘in-the-wild’. This dataset has been used to identify trends in language e volution in teenagers ( Stenstr ¨ om et al. , 2002 ). The Cambridge and Nottingham Corpus of Discourse in English (CANCODE) ( McCarthy , 1998 ) is a subset of the Cambridge International Corpus, containing about 5 million w ords collected from recordings made throughout the islands of Britain and Ireland. It was constructed by Cam- bridge University Press and the Uni versity of Nottingham using dialogue data on general topics between 1995 and 2000. It focuses on interpersonal communication in a range of social contexts, v arying from hair salons, to post offices, to restaurants. This has been used, for example, to study language awareness in relation to spoken texts and their cultural contexts ( Carter , 1998 ). In the dataset, the relationships between speak ers (e.g. roommates, strangers) is labeled and the interac- tion type is provided (e.g. professional, intimate). Other works hav e attempted to record the physical elements of conv ersations between humans. T o this end, a small corpus entitled d64 Multimodal Con versational Corpus ( Oertel et al. , 2013 ) was collected, incorporating data from 7 video cameras, and the registration of 3-D head, torso, and arm motion using an Optitrack system. Significant ef fort was made to make the data collection process as non-intrusi ve—and thus, naturalistic—as possible. Annotations were made to attempt to quantify ov erall group excitement and pairwise social distance between participants. A similar attempt to incorporate computer vision features was made in the AMI Meeting Cor- pus ( Renals et al. , 2007 ), where cameras, a VGA data projector capture, whiteboard capture, and digital pen capture, were all used in addition to speech recordings for v arious meeting scenarios. As with the d64 corpus, the AMI Meeting Corpus is a small dataset of multi-participant chats, that has not been disentangled into strict dialogue. The dataset has often been used for analysis of the dynamics of v arious corporate and academic meeting scenarios. In a similar vein, the Cardiff Con versation Database (CCDb) ( Aubrey et al. , 2013 ) is an audio- visual database containing unscripted natural conv ersations between pairs of people. The original dataset consisted of 30 fi ve minute con versations, 7 of which were fully annotated with transcrip- tions and behavioural annotations such as speaker activity , facial expressions, head motions, and smiles. The content of the con versation is an unconstrained discussion on topics such as movies. While the original dataset featured 2D visual feeds, an updated version with 3D video has also been deri ved, called the 4D Cardiff Con versation Database (4D CCDb) ( V andev enter et al. , 2015 ). 20 This version contains 17 one-minute con versations from 4 participants on similarly un-constrained topics. The Diachronic Corpus of Present-Day Spoken English (DCPSE) ( Aarts and W allis , 2006 ) is a parsed corpus of spoken English made up of two separate datasets. It contains more than 400,000 words from the ICE-GB corpus (collected in the early 1990s) and 400,000 words from the London- Lund Corpus (collected in the late 1960s-early 1980s). ICE-GB refers to the British component of the International Corpus of English ( Greenbaum and Nelson , 1996 ; Greenbaum , 1996 ) and contains both spoken and written dialogues from English adults who have completed secondary education. The dataset was selected to provide a representati ve sample of British English. The London-Lund Corpus ( Sv artvik , 1990 ) consists exclusi vely of spoken British con versations, both dialogues and monologues. It contains a selection of face-to-f ace, telephone, and public discussion dialogues; the latter refers to dialogues that are heard by an audience that does not participate in the dialogue, in- cluding interviews and panel discussions that hav e been broadcast. The orthographic transcriptions of the datasets are normalised and annotated according to the same criteria; ICE-GB was used as a gold standard for the parsing of DCPSE. The Spoken Corpus of the Survey of English Dialects ( Beare and Scott , 1999 ) consists of 1000 recordings, with about 0.8 million total words, collected from 1948-1961 in order to document v arious existing English dialects. People aged 60 and over were recruited, being most likely to speak the traditional ‘uncontaminated’ dialects of their area and encouraged to talk about their memories, families, work, and their countryside folklore. The Child Language Data Exchange System (CHILDES) ( MacWhinne y and Snow , 1985 ) is a database or ganized for the study of first and second language acquisition. The database contains 10 million English words and approximately the same number of non-English words. It also contains transcripts, with occasional audio and video recordings of data collected from children and adults learning both first and second languages, although the English transcripts are mostly from children. This corpus could be le veraged in order to b uild automated teaching assistants. The expanded Charlotte Narrati ve and Con versation Collection (CNCC), a subset of the first release of the American National Corpus ( Reppen and Ide , 2004 ), contains 95 narrativ es, con ver - sations and interviews representative of the residents of Mecklenburg County , North Carolina and its surrounding communities. The purpose of the CNCC w as to create a corpus of con versation and con versational narration in a ’New South’ city at the be ginning of the 21st century , that could be used as a resource for linguistic analysis. It was originally released as one of se veral collections in the Ne w South V oices corpus, which otherwise contained mostly oral histories. Information on speaker age and gender in the CNCC is included in the header for each transcript. 4 . 2 . 2 C O N S T R A I N E D S P O K E N C O R P O R A Next, we discuss domains in which con versations only occur about a particular topic, or intend to solve a specific task. Not only is the topic of the con versation specified beforehand, but participants are discouraged from de viating of f-topic. As a result, these corpora are slightly less general than their spontaneous counterparts; ho we ver , they may be useful for building goal-oriented dialogue systems. As discussed in Subsection 3.3 , this may also make the con versations less natural. W e can further subdivide this category into the types of topics they cov er: path-finding or planning tasks, persuasion tasks or debates, Q&A or information retrie v al tasks, and miscellaneous topics. 21 Collaborative P ath-Finding or Planning T asks Se veral corpora focus on task planning or path- finding through the collaboration of two interlocutors. In these corpora typically one person acts as the decision maker and the other acts as the observ er . A well-known e xample of such a dataset is the HCRC Map T ask Corpus ( Anderson et al. , 1991 ), that consists of unscripted, task-oriented dialogues that have been digitally recorded and transcribed. The corpus uses the Map T ask ( Bro wn et al. , 1984 ), where participants must collab- orate v erbally to reproduce a route on one of the participant’ s map on the map of another partic- ipant. The corpus is fairly small, but it controls for the familiarity between speakers, e ye contact between speak ers, matching between landmarks on the participants’ maps, opportunities for con- trasti ve stress, and phonological characteristics of landmark names. By adding these controls, the dataset attempts to focus on solely the dialogue and human speech in volved in the planning process. The W alking Ar ound Corpus ( Brennan et al. , 2013 ) consists of 36 dialogues between people communicating over mobile telephone. The dialogues hav e two parts: first, a ‘stationary partner’ is asked to direct a ‘mobile partner’ to find 18 destinations on a medium-sized univ ersity campus. The stationary partner is equipped with a map marked with the target destinations accompanied by photos of the locations, while the mobile partner is given a GPS na vigation system and a camera to take photos. In the second part, the participants are asked to interact in-person in order to duplicate the photos tak en by the mobile partner . The goal of the dataset is to provide a testbed for natural lexical entrainment, and to be used as a resource for pedestrian na vigation applications. The TRAINS 93 Dialogues Corpus ( Heeman and Allen , 1995 ) consists of recordings of two interlocutors interacting to solve v arious planning tasks for scheduling train routes and arranging railroad freight. One user acts the role of a planning assistant system and the other user acts as the coordinator . This was not done in a W izard-of-Oz f ashion, and as such is not considered a Human-Machine corpus. 34 different interlocutors were asked to complete 20 different tasks such as: “Determine the maximum number of boxcars of oranges that you could get to Bath by 7 AM tomorro w morning. It is now 12 midnight. ” The person playing the role of the planning assistant was provided with access to information that is needed to solve the task. Also included in the dataset is the information a vailable to both users, the length of dialogue, and the speaker and “system” interlocutor identities. The V erbmobil Cor pus ( Burger et al. , 2000 ) is a multilingual corpus consisting of English, German, and Japanese dialogues collected for the purposes of training and testing the V erbmobil project system. The system was a designed for speech-to-speech machine translation tasks. Dia- logues were recorded in a variety of conditions and settings with room microphones, telephones, or close microphones, and were subsequently transcribed. Users were task ed with planning and scheduling an appointment throughout the course of the dialogue. Note that while there ha ve been se veral versions of the V erbmobil corpora released, we refer to the entire collection here as described in ( Burger et al. , 2000 ). Dialogue acts were annotated in a subset of the corpus (1,505 mixed dia- logues in German, English and Japanese). 76,210 acts were annotated with 32 possible categories of dialogue acts Alexandersson et al. ( 2000 ) 4 . Persuasion and Debates Another theme recurring among constrained spoken corpora is the ap- pearance of persuasion or debate tasks. These can in volv e general debates on a topic or tasking a specific interlocutor to try to convince another interlocutor of some opinion or topic. Generally , 4. Note, this information and further facts about the V erbmobil project and corpus can be found here: http: //verbmobil.dfki.de/facts.html 22 these datasets record the outcome of ho w con vinced the audience is of the argument at the end of the dialogue or debate. The Green Persuasive Dataset ( Douglas-Co wie et al. , 2007 ) was recorded in 2007 to provide data for the HUMAINE project, whose goal is to develop interfaces that can register and respond to emotion. In the dataset, a persuader with strong pro-environmental (‘pro-green’) feelings tries to con vince persuadees to consider adopting more green lifestyles; these interactions are in the form of dialogues. It contains 8 long dialogues, totalling about 30 minutes each. Since the persuadees often either disagree or agree strongly with the persuaders points, this w ould be good corpus for studying social signs of (dis)-agreement between two people. The MAHNOB Mimicry Database ( Sun et al. , 2011 ) contains 11 hours of recordings, split ov er 54 sessions between 60 people engaged either in a socio-political discussion or negotiating a tenancy agreement. This dataset consists of a set of fully synchronised audio-visual recordings of natural dyadic (one-on-one) interactions. It is one of se veral dialogue corpora that provide multi- modal data for analyzing human beha viour during con versations. Such corpora often consist of auditory , visual, and written transcriptions of the dialogues. Here, only audio-visual recordings are provided. The purpose of the dataset was to analyze mimicry (i.e. when one participant mimics the verbal and non verbal expressions of their counterpart). The authors provide some benchmark video classification models to this ef fect. The Intelligence Squared Debate Dataset ( Zhang et al. , 2016 ) cov ers the “Intelligence Squared” Oxford-style debates taking place between 2006 and 2015. The topics of the debates vary across the dataset, but are constrained within the conte xt of each debate. Speakers are labeled and the full transcript of the debate is provided. Furthermore, the outcome of the debate is pro vided (how many of the audience members were for the gi ven proposal or against, before and after the debate). QA or Inf ormation Retriev al There are se veral corpora which feature direct question and an- swering sessions. These may in v olve general QA, such as in a press conference, or more task- specific lines of questioning, as to retrie ve a specific set of information. The Corpus of Professional Spok en American English (CPSAE) ( Barlow , 2000 ) was con- structed using a selection of transcripts of interactions occurring in professional settings. The corpus contains two million words in volving over 400 speak ers, recorded between 1994-1998. The CP ASE has two main components. The first is a collection of transcripts (0.9 million words) of White House press conferences, which contains almost exclusi vely question and answer sessions, with some pol- icy statements by politicians. The second component consists of transcripts (1.1 million words) of faculty meetings and committee meetings related to national tests that in volve statements, discus- sions, and questions. The creation of the corpus was moti vated by the desire to understand and model more formal uses of the English language. As previously mentioned, the Dialog State Tracking Challenge (DSTC) consists of a series of datasets ev aluated using a ‘state tracking’ or ‘slot filling’ metric. While the first 3 installments of this challenge had con versations between a human participant and a computer , DSTC4 ( Kim et al. , 2015 ) contains dialogues between humans. In particular, this dataset has 35 con versations with 21 hours of interactions between tourists and tour guides o ver Sk ype, discussing information on hotels, flights, and car rentals. Due to the small size of the dataset, researchers were encouraged to use transfer learning from other datasets in the DSTC in order to impro ve state tracking performance. This same training set is used for DSTC5 ( Kim et al. , 2016 ) as well. Ho we ver , the goal of DSTC5 23 is to study multi-lingual speech-act prediction, and therefore it combines the DSTC4 dialogues plus a set of equi v alent Chinese dialogs; ev aluation is done on a holdout set of Chinese dialogues. Miscellaneous Lastly , there are se veral corpora which do not fall into any of the aforementioned categories, in volving a range of tasks and situations. The IDIAP W olf Corpus ( Hung and Chittaranjan , 2010 ) is an audio-visual corpus containing natural con versational data of v olunteers who took part in an adversarial role-playing game called ‘W erewolf ’. Four groups of 8-12 people were recorded using headset microphones and synchro- nised video cameras, resulting in over 7 hours of con versational data. The nov elty of this dataset is that the roles of other players are unknown to game participants, and some of the roles are decep- ti ve in nature. Thus, there is a significant amount of lying that occurs during the g ame. Although specific instances of lying are not annotated, each speaker is labeled with their role in the game. In a dialogue setting, this could be useful for analyzing the dif ferences in language when deception is being used. The SEMAINE Corpus ( McK eown et al. , 2010 ) consists of 100 ‘emotionally coloured’ con- versations. Participants held conv ersations with an operator who adopted various roles designed to e vok e emotional reactions. These conv ersations were recorded with synchronous video and audio de vices. Importantly , the operators’ responses were stock phrases that were independent of the con- tent of the user’ s utterances, and only dependent on the user’ s emotional state. This corpus motiv ates building dialogue systems with af fective and emotional intelligence abilities, since the corpus does not exhibit the natural language understanding that normally occurs between human interlocutors. The Loqui Human-Human Dialogue Corpus ( Passonneau and Sachar , 2014 ) consists of an- notated transcriptions of telephone interactions between patrons and librarians at Ne w Y ork City’ s Andre w Heiskell Braille & T alking Book Library in 2006. It stands out as it has annotated dis- cussion topics, question-answer pair links (adjacency pairs), dialogue acts, and frames (discourse units). Similarly , the The ICSI Meeting Recorder Dialog Act (MRDA) Corpus ( Shriberg et al. , 2004 ) has annotated dialogue acts, question-answer pair links (adjacency pairs), and dialogue hot spots 5 . It consists of transcribed recordings of 75 ICSI meetings on sev eral classes of topics including: the ICSI meeting recorder project itself, automatic speech recognition, natural language processing and neural theories of language, and discussions with the annotators for the project. 4 . 2 . 3 S C R I P T E D C O R P O R A A final category of spok en dialogue consists of con versations that ha ve been pre-scripted for the purpose of being spoken later . W e refer to datasets containing such conv ersations as ‘scripted cor- pora’. As discussed in Subsection 3.4 , these datasets are distinct from spontaneous human-human con versations, as they inevitably contain fe wer ‘filler’ words and expressions that are common in spoken dialogue. Ho wev er , the y should not be confused with human-human written dialogues, as they are intended to sound like natural spoken con versations when read aloud by the participants. Furthermore, these scripted dialogues are required to be dramatic, as they are generally sourced from movies or TV sho ws. There e xist multiple scripted corpora based on mo vies and TV series. These can be sub-divided into two categories: corpora that provide the actual scripts (i.e. the mo vie script or TV series script) where each utterance is tagged with the appropriate speaker , and those that only contain subtitles 5. For more information on dialogue hot spots and how the y relate to dialogue acts, see ( Wrede and Shriberg , 2003 ). 24 and consecuti ve utterances are not divided or labeled in any way . It is al ways preferable to have the speaker labels, but there is significantly more unlabeled subtitle data av ailable, and both sources of information can be le veraged to b uild a dialogue system. The Mo vie DiC Corpus ( Banchs , 2012 ) is an example of the former case—it contains about 130,000 dialogues and 6 million words from mo vie scripts extracted from the Internet Movie Script Data Collection 6 , carefully selected to co ver a wide range of genres. These dialogues also come with context descriptions, as written in the script. One deriv ation based on this corpus is the Movie T riples Dataset ( Serban et al. , 2016 ). There is also the American Film Scripts Corpus and Film Scripts Online Corpus which form the Film Scripts Online Series Corpus , which can be pur- chased 7 . The latter consists of a mix of British and American film scripts, while the former consists of solely American films. The majority of these datasets consist mostly of ra w scripts, which are not guaranteed to portray con versations between only two people. The dataset collected by Nio et al. ( 2014b ), which we refer to as the Filtered Movie Script Corpus , takes over 1 million utterance-response pairs from web- based script resources and filters them down to 86,000 such pairs. The filtering method limits the extracted utterances to X-Y -X triples, where X is spoken by the same actor and each of the utterance share some semantic similarity . These triples are then decomposed into X-Y and Y -X pairs. Such filtering lar gely remov es con versations with more than two speakers, which could be useful in some applications. Particularly , the filtering method helps to retain semantic conte xt in the dialogue and keeps a back-and-forth con versational flo w that is desired in training many dialogue systems. The Cor nell Movie-Dialogue Corpus ( Danescu-Niculescu-Mizil and Lee , 2011 ) also has short con versations extracted from movie scripts. The distinguishing feature of this dataset is the amount of metadata a v ailable for each conv ersation: this includes mo vie metadata such as genre, release year , and IMDB rating, as well as character metadata such as gender and position on mo vie credits. Although this corpus contains 220,000 dialogue excerpts, it only contains 300,000 utterances; thus, many of the e xcerpts consist of single utterances. The Corpus of American Soap Operas ( Davies , 2012b ) contains 100 million w ords in more than 22,000 transcripts of ten American TV -series soap operas from 2001 and 2012. Because it is based on soap operas it is qualitatively different from the Movie Dic Corpus, which contains mo vies in the action and horror genres. The corpus was collected to provide insights into colloquial Amer- ican speech, as the vocab ulary usage is quite dif ferent from the British National Corpus ( Davies , 2012a ). Unfortunately , this corpus does not come with speaker labels. Another corpus consisting of dialogues from TV sho ws is the TVD Corpus ( Roy et al. , 2014 ). This dataset consists of 191 movie transcripts from the comedy show The Big Bang Theory , and the drama show Game of Thr ones , along with crowd-sourced text descriptions (brief episode sum- maries, longer episode outlines) and v arious types of metadata (speak ers, shots, scenes). T ext align- ment algorithms are used to link descriptions and metadata to the appropriate sections of each script. For e xample, one might align an e vent description with all the utterances as sociated with that e vent in order to de velop algorithms for locating specific ev ents from raw dialogue, such as ’person X tries to con vince person Y’. Some work has been done in order to analyze character style from movie scripts. This is aided by a dataset collected by W alker et al. ( 2012a ) that we refer to as the Character Style from Film Cor - pus . This corpus was collected from the IMSDb archi ve, and is annotated for linguistic structures 6. http://www.imsdb.com 7. http://alexanderstreet.com/products/film- scripts- online- series 25 and character archetypes. Features, such as the sentiment behind the utterances, are automatically extracted and used to deri ve models of the characters in order to generate ne w utterances similar in style to those spoken by the character . Thus, this dataset could be useful for b uilding dialogue personalization models. There are two primary mo vie subtitle datasets: the OpenSubtitles ( Tiedemann , 2012 ) and the SubTle Corpus ( Ameixa and Coheur , 2013 ). Both corpora are based on the OpenSubtitles web- site. 8 The OpenSubtitles dataset is a giant collection of mo vie subtitles, containing o ver 1 billion words, whereas SubTle Corpus has been pre-processed in order to extract interaction-response pairs that can help dialogue systems deal with out-of-domain (OOD) interactions. The Corpus of English Dialogues 1560-1760 (CED) ( Kyt ¨ o and W alk er , 2006 ) compiles di- alogues from the mid-16th century until the mid-18th century . The sources vary from real trial transcripts to fiction dialogues. Due to the scripted nature of fictional dialogues and the f act that the majority of the corpus consists of fictional dialogue, we classify it here as such. The corpus is com- posed as follows: trial proceedings (285,660 words), witness depositions (172,940 words), drama comedy works (238,590 words), didactic works (236,640 words), prose fiction (223,890 w ords), and miscellaneous (25,970 words). 4.3 Human-Human Written Corpora W e proceed to surv ey corpora of con versations between humans in written form. As before, we sub-di vide this section into spontaneous and constrained corpora, depending on whether there are restrictions on the topic of con versation. Ho wev er, we make a further distinction between forum , micr o-blogging , and c hat corpora. Forum corpora consist of con versations on forum-based websites such as Reddit 9 where users can make posts, and other users can make comments or replies to said post. In some cases, com- ments can be nested indefinitely , as users make replies to pre vious replies. Utterances in forum corpora tend to be longer, and there is no restriction on the number of participants in a discussion. On the other hand, con versations on micro-blogging websites such as T witter 10 tend to ha ve very short utterances as there is an upper bound on the number of characters permitted in each message. As a result, these tend to exhibit highly colloquial language with many abbreviations. The identi- fying feature of chat corpora is that the conv ersations take place in real-time between users. Thus, these con versations share more similarities with spoken dialogue between humans, such as common grounding phenomena. 4 . 3 . 1 S P O N T A N E O U S W R I T T E N C O R P O R A W e begin with written corpora where the topic of con versation is not pre-specified. Such is the case for the NPS Internet Chatroom Con versations Corpus ( Forsyth and Martell , 2007 ), which con- sists of 10,567 English utterances gathered from age-specific chat rooms of v arious online chat ser- vices from October and November of 2006. Each utterance was annotated with part-of-speech and dialogue act information; the correctness of this was verified manually . The NPS Internet Chatroom Con versations Corpus was one of the first corpora of computer -mediated communication (CMC), 8. http://www.opensubtitles.org 9. http://www.reddit.com 10. http://www.twitter.com 26 and it was intended for v arious NLP applications such as con versation thread topic detection, author profiling, entity identification, and social network analysis. Se veral corpora of spontaneous micro-blogging con versations hav e been collected, such as the T witter Corpus from Ritter et al. ( 2010 ), which contains 1.3 million post-reply pairs e xtracted from T witter . The corpus was originally constructed to aid in the production of unsupervised approaches to modeling dialogue acts. Larger T witter corpora have been collected. The T witter T riples Cor- pus ( Sordoni et al. , 2015b ) is one such example, with a described original dataset of 127 million context-message-response triples, but only a small labeled subset of this corpus has been released. Specifically , the released labeled subset contains 4,232 pairs that scored an average of greater than 4 on the Lik ert scale by cro wdsourced e valuators for quality of the response to the context-message pair . Similarly , lar ge micro-blogging corpora such as the Sina W eibo Corpus ( Shang et al. , 2015 ), which contains 4.5 million post-reply pairs, have been collected; howe ver , the authors have not yet been made publicly av ailable. W e do not include the Sina W eibo Corpus (and its deri v ati ves) in the tables in this section, as they are not primarily in English. The Usenet Cor pus ( Shaoul and W estbury , 2009 ) is a gigantic collection of public Usenet postings 11 containing over 7 billion words from October 2005 to January 2011. Usenet w as a distributed discussion system established in 1980 where participants could post articles to one of 47,860 ‘ne wsgroup’ cate gories. It is seen as the precursor to many current Internet forums. The corpus deri ved from these posts has been used for research in collaborative filtering ( Konstan et al. , 1997 ) and role detection ( Fisher et al. , 2006 ). The NUS SMS Corpus ( Chen and Kan , 2013 ) consists of con versations carried out ov er mobile phone SMS messages between two users. While the original purpose of the dataset was to impro ve predicti ve text entry when mobile phones still mapped multiple letters to a single number, aided by video and timing analysis of users entering their messages it could equally be used for analysis of informal dialogue. Unfortunately , the corpus does not consist of dialogues, b ut rather single SMS messages. SMS messages are similar in style to T witter , in that they use many abbreviations and acronyms. Currently , one of the most popular forum-based websites is Reddit 12 where users can create discussions and post comments in v arious sub-forums called ‘subreddits’. Each subreddit addresses its o wn particular topic. Over 1.7 billion of these comments ha ve been collected in the Reddit Cor - pus . 13 Each comment is labeled with the author , score (rating from other users), and position in the comment tree; the position is important as it determines which comment is being replied to. Al- though researchers ha ve not yet in vestigated dialogue problems using this Reddit discussion corpus, the sheer size of the dataset renders it an interesting candidate for transfer learning. Additionally , researchers have used smaller collections of Reddit discussions for broad discourse classification. ( Schrading et al. , 2015 ). Some more curated versions of the Reddit dataset have been collected. The Reddit Domestic Abuse Corpus ( Schrading et al. , 2015 ) consists of Reddit posts and comments taken from either subreddits specific to domestic abuse, or from subreddits representing casual con versations, advice, and general anxiety or anger . The moti vation is to build classifiers that can detect occurrences of domestic ab use in other areas, which could provide insights into the prev alence and consequences 11. http://www.usenet.net 12. http://www.reddit.com 13. https://www.reddit.com/r/datasets/comments/3bxlg7/i_have_every_publicly_ available_reddit_comment/ 27 of these situations. These con versations have been pre-processed with lower-casing, lemmatizing, and remov al of stopwords, and semantic role labels are provided. 4 . 3 . 2 C O N S T R A I N E D W R I T T E N C O R P O R A There are also se veral written corpora where users are limited in terms of topics of conv ersation. For example, the Settlers of Catan Corpus ( Afantenos et al. , 2012 ) contains logs of 40 games of ‘Settlers of Catan’, with about 80,000 total labeled utterances. The game is played with up to 4 players, and is predicated on trading certain goods between players. The goal of the game is to be the first player to achiev e a pre-specified number of points. Therefore, the game is adversarial in nature, and can be used to analyze situations of strategic con versation where the agents have di ver ging moti ves. Another corpus that deals with game playing is the Cards Corpus ( Djalali et al. , 2012 ), which consists of 1,266 transcripts of con versations between players playing a game in the ‘Cards world’. This world is a simple 2-D environment where players collaborate to collect cards. The goal of the game is to collect six cards of a particular suit (cards in the environment are only visible to a player when they are near the location of that player), or to determine that this goal is impossible in the en vironment. The catch is that each player can only hold 3 cards, thus players must collaborate in order to achie ve the goal. Further , each player’ s location is hidden to the other player, and there are a fix ed number of non-chatting mov es. Thus, players must use the chat to formulate a plan, rather than exhausti vely e xploring the en vironment themselves. The dataset has been further annotated by Potts ( 2012 ) to collect all locati ve question-answer pairs (i.e. all questions of the form ‘Where are you?’). The Agr eement by Create Debaters Corpus ( Rosenthal and McKeo wn , 2015 ), the Agr ee- ment in W ikipedia T alk Pages Corpus ( Andreas et al. , 2012 ) and the Inter net Argument Corpus ( Abbott et al. , 2016 ) all cover dialogs with annotations measuring le vels of agreement or disagree- ment in responses to posts in various media. The Agr eement by Create Debaters Corpus and the Agreement in W ikipedia T alk Pages Corpus both are formatted in the same way . Post-reply pairs are annotated with whether they are in agreement or disagreement, as well as the type of agreement they are in if applicable (e.g. paraphrasing). The difference between the two corpora is the source: the former is collected from Create Debate forums and the latter from a mix of Wikipedia Discus- sion pages and LiveJournal postings. The Inter net Argument Corpus (IAC) ( W alker et al. , 2012b ) is a forum-based corpus with 390,000 posts on 11,000 discussion topics. Each topic is controv ersial in nature, including subjects such as ev olution, gay marriage and climate change; users participate by sharing their opinions on one of these topics. Posts-reply pairs ha ve been labeled as being either in agreement or disagreement, and sarcasm ratings are gi ven to each post. Another source of constrained text-based corpora are chat-room en vironments. Such a set-up forms the basis of the MPC Corpus ( Shaikh et al. , 2010 ), which consists of 14 multi-party dialogue sessions of approximately 90 minutes each. In some cases, discussion topics were constrained to be about certain political stances, or mock committees for choosing job candidates. An interest- ing feature is that dif ferent participants are gi ven dif ferent roles—leader, disruptor , and consensus builder —with only a general outline of their goals in the con versation. Thus, this dataset could be used to model social phenomena such as agenda control, influence, and leadership in on-line interactions. 28 The largest written corpus with a constrained topic is the recently released Ubuntu Dialogue Corpus ( Lo we et al. , 2015a ), which has almost 1 million dialogues of 3 turns or more, and 100 million words. It is related to the former Ub untu Chat Corpus ( Uthus and Aha , 2013 ). Both corpora were scraped from the Ub untu IRC channel logs. 14 On this channel, users can log in and ask a question about a problem they are having with Ub untu; these questions are answered by other users. Although the chat room allo ws e veryone to chat with each other in a multi-party setting, the Ub untu Dialogue Corpus uses a series of heuristics to disentangle it into dyadic dialogue. The technical nature and size of this corpus lends itself particularly well to applications in technical support. Other corpora have been e xtracted from IRC chat logs. The IRC Corpus ( Elsner and Charniak , 2008 ) contains approximately 50 hours of chat, with an estimated 20,000 utterances from the Linux channel on IRC, complete with the posting times. Therefore, this dataset consists of similarly technical con versations to the Ubuntu Corpus, with the occasional social chat. The purpose of this dataset was to inv estigate approaches for con versation disentanglement; giv en a multi-party chat room, one attempts to reco ver the indi vidual con versations of which it is composed. For this purpose, there are approximately 1,500 utterances with annotated ground-truth con versations. More recent efforts have combined traditional con versational corpora with question answering and recommendation datasets in order to f acilitate the construction of goal-dri ven dialogue systems. Such is the case for the Movie Dialog Dataset ( Dodge et al. , 2015 ). There are four tasks that the authors propose as a prerequisite for a w orking dialogue system: question answering, recommenda- tion, question answering with recommendation, and casual con versation. The Mo vie Dialog dataset consists of four sub-datasets used for training models to complete these tasks: a QA dataset from the Open Movie Database (OMDb) 15 of 116k examples with accompan ying movie and actor metadata in the form of knowledge triples; a recommendation dataset from MovieLens 16 with 110k users and 1M questions; a combined recommendation and QA dataset with 1M con versations of 6 turns each; and a discussion dataset from Reddit’ s movie subreddit. The former is ev aluated using recall metrics in a manner similar to Lo we et al. ( 2015a ). It should be noted that, other than the Reddit dataset, the dialogues in the sub-datasets are simulated QA pairs, where each response corresponds to a list of entities from the kno wledge base. 5. Discussion W e conclude by discussing a number of general issues related to the de velopment and ev aluation of data-dri ven dialogue systems. W e also discuss alternative sources of information, user personaliza- tion, and automatic e v aluation methods. 5.1 Challenges of Learning fr om Large Datasets Recently , se veral large-scale dialogue datasets have been proposed in order to train data-dri ven dialogue systems; the T witter Corpus ( Ritter et al. , 2010 ) and the Ubuntu Dialogue corpus ( Lo we et al. , 2015a ) are tw o examples. In this section, we discuss the benefits and drawbacks of these datasets based on our experience using them for b uilding data-driven models. Unlike the previous 14. http://irclogs.ubuntu.com 15. http://en.omdb.org 16. http://movielens.org 29 section, we now focus e xplicitly on aspects of high relev ance for using these datasets for learning dialogue strategies. 5 . 1 . 1 T H E T W I T T E R C O R P U S The T witter Corpus consists of a series of con versations extracted from tweets. While the dataset is large and general-purpose, the micro-blogging nature of the source material leads to se veral draw- backs for b uilding con versational dialogue agents. Ho we ver , some of these dra wbacks do not apply if the end goal is to build an agent that interacts with users on the T witter platform. The T witter Corpus has an enormous amount of typos, slang, and abbre viations. Due to the 140-character limit, tweets are often v ery short and compressed. In addition, users frequently use T witter-specific devices such as hashtags. Unless one is b uilding a dialogue agent specifically for T witter, it is often not desirable to ha ve a chatbot use hashtags and excessi ve abbre viations as it is not reflectiv e of how humans con verse in other en vironments. This also results in a significant increase in the word vocab ulary required for dialogue systems trained at the w ord lev el. As such, it is not surprising that character -level models hav e sho wn promising results on T witter ( Dhingra et al. , 2016 ). T witter con versations often contain various kinds of verbal role-playing and imaginative actions similar to stage directions in theater plays (e.g. instead of writing “goodbye” , a user might write “*wa ves goodbye and leav es*”). These con versations are very dif ferent from the majority of text- based chats. Therefore, dialogue models trained on this dataset are often able to provide interesting and accurate responses to conte xts in v olving role-playing and imaginati ve actions ( Serban et al. , 2017b ). Another challenge posed by T witter is that T witter con versations often refer to recent public e vents outside the con versation. In order to learn ef fectiv e responses for such con versations, a dialogue agent must infer the ne ws ev ent under discussion by referencing some form of external kno wledge base. This would appear to be a particularly difficult task. 5 . 1 . 2 T H E U B U N T U D I A L O G U E C O R P U S The Ubuntu Dialogue Corpus is one of the largest, publicly av ailable datasets containing technical support dialogues. Due to the commercial importance of such systems, the dataset has attracted significant attention. 17 Thus, the Ubuntu Dialogue Corpus presents the opportunity for anyone to train large-scale data-dri ven technical support dialogue systems. Despite this, there are se veral problems when training data-driven dialogue models on the Ubuntu Dialogue Corpus due to the nature of the data. First, since the corpus comes from a multi- party IRC channel, it needs to be disentangled into separate dialogues. This disentanglement process is noisy , and errors ine vitably arise. The most frequent error is when a missing utterance in the di- alogue is not picked up by the extraction procedure (e.g. an utterance from the original multi-party chat was not added to the disentangled dialogue). As a result, for a substantial amount of conv er- sations, it is difficult to follow the topic. In particular , this means that some of the Ne xt Utterance Classification (NUC) examples, where models must select the correct next response from a list of candidates, are either dif ficult or impossible for models to predict. 17. Most of the largest technical support datasets are based on commercial technical support channels, which are propri- etary and nev er released to the public for privac y reasons. 30 Another problem arises from the lack of annotations and labels. Since users try to solve their technical problems, it is perhaps best to build models under a goal-dri ven dialogue frame work, where a dialogue system has to maximize the probability that it will solve the user’ s problem at the end of the con versation. Ho we ver , there are no reward labels av ailable. Thus, it is difficult to model the dataset in a goal-dri ven dialogue frame work. Future work may alle viate this by constructing automatic methods of determining whether a user in a particular con versation solv ed their problem. A particular challenge of the Ubuntu Dialogue Corpus is the lar ge number of out-of-v ocabulary words, including many technical w ords related to the Ubuntu operating system, such as commands, software packages, websites, etc. Since these words occur rarely in the dataset, it is dif ficult to learn their meaning directly from the dataset — for example, it is difficult to obtain meaningful distributed, real-v alued vector representations for neural network-based dialogue models. This is further e xacerbated by the lar ge number of users who use dif ferent nomenclature, acron yms, and speaking styles, and the many typos in the dataset. Thus, the linguistic di versity of the corpus is large. A final challenge of the dataset is the necessity for additional knowledge related to Ub untu in order to accurately generate or predict the next response in a con versation. W e h ypothesize that this knowledge is crucial for a system trained on the Ubuntu Dialogue Corpus to be ef fective in practice, as often solutions to technical problems change over time as ne w v ersions of the operating system become av ailable. Thus, an ef fecti ve dialogue system must learn to combine up-to-date technical information with an understanding of natural language dialogue in order to solve the users’ problems. W e will discuss the use of e xternal knowledge in more detail in Section 5.5 . While these challenges make it dif ficult to build data-dri ven dialogue systems, it also presents an important research opportunity . Current data-driv en dialogue systems perform rather poorly in terms of generating utterances that are coherent and on-topic ( Serban et al. , 2017a ). As such, there is significant room for improv ement on these models. 5.2 T ransfer Lear ning Between Datasets While it is not alw ays feasible to obtain lar ge corpora for e very ne w application, the use of other related datasets can effecti vely bootstrap the learning process. In se veral branches of machine learn- ing, and in particular in deep learning, the use of related datasets in pre-training the model is an ef fecti ve method of scaling up to comple x en vironments ( Erhan et al. , 2010 ; Kumar et al. , 2015 ). T o build open-domain dialogue systems, it is arguably necessary to mov e beyond domain- specific datasets. Instead, like humans, dialogue systems may hav e to be trained on multiple data sources for solving multiple tasks. T o lev erage statistical efficienc y , it may be necessary to first use unsupervised learning—as opposed to supervised learning or offline reinforcement learning, which typically only provide a sparse scalar feedback signal for each phrase or sequence of phrases—and then fine-tune models based on human feedback. Researchers have already proposed v arious ways of applying transfer learning to build data-driv en dialogue systems, ranging from learning separate sub-components of the dialogue system (e.g. intent and dialogue act classification) to learning the entire dialogue system (e.g. in an unsupervised or reinforcement learning frame work) using transfer learning ( Fabbrizio et al. , 2004 ; For gues et al. , 2014 ; Serban and Pineau , 2015 ; Serban et al. , 2016 ; Lo we et al. , 2015a ; V andyke et al. , 2015 ; W en et al. , 2016 ; Ga ˇ si ´ c et al. , 2016 ; Mo et al. , 2016 ; Gene v ay and Laroche , 2016 ; Chen et al. , 2016 ) 31 5.3 T opic-oriented & Goal-driven Datasets T ables 1 – 5 list the topics of av ailable datasets. Se veral of the human-human datasets are denoted as having casual or unrestricted topics. In contrast, most human-machine datasets focus on specific, narro w topics. It is useful to k eep this distinction between r estricted and unrestricted topics in mind, as goal-driv en dialogue systems — which typically hav e a well-defined measure of performance related to task completion — are usually developed in the former setting. In some cases, the line between these two types of datasets blurs. For e xample, in the case of con versations occurring between players of an online g ame ( Afantenos et al. , 2012 ), the outcome of the game is determined by ho w participants play in the game environment, not by their con versation. In this case, some con versations may hav e a direct impact on a player’ s performance in the game, some con versations may be related to the game b ut irrele vant to the goal (e.g. commentary on past ev ents) and some con versations may be completly unrelated to the game. 5.4 Incorporating longer memories Recently , significant progress has been made to wards incorporating a form of external memory into various neural-network architectures for sequence modeling. Models such as Memory Net- works ( W eston et al. , 2015 ; Sukhbaatar et al. , 2015 ) and Neural T uring Machines (NTM) ( Grav es et al. , 2014 ) store some part of their input in a memory , which is then reasoned over in order to perform a variety of sequence to sequence tasks. These vary from simple problems, such as se- quence copying, to more complex problems, such as question answering and machine translation. Although none of these models are explicitly designed to address dialogue problems, the extension by Kumar et al. ( 2015 ) to Dynamic Memory Networks specifically differentiates between episodic and semantic memory . In this case, the episodic memory is the same as the memory used in the traditional Memory Netw orks paper that is extracted from the input, while the semantic memory refers to kno wledge sources that are fixed for all inputs. The model is shown to work for a v ariety of NLP tasks, and it is not dif ficult to envision an application to dialogue utterance generation where the semantic memory is the desired external kno wledge source. 5.5 Incorporating External Kno wledge Another interesting research direction is the incorporation of external kno wledge sources in order to inform the response to be generated. Using external information is of great importance to dialogues systems, particularly in the goal-driv en setting. Even non-goal-driv en dialogue systems designed to simply entertain the user could benefit from lev eraging external information, such as current ne ws articles or movie revie ws, in order to better con verse about real-world e vents. This may be particularly useful in data-sparse domains, where there is not enough dialogue training data to reliably learn a response that is appropriate for each input utterance, or in domains that ev olve quickly ov er time. 5 . 5 . 1 S T R U C T U R E D E X T E R NA L K N O W L E D G E In traditional goal-dri ven dialogue systems ( Levin and Pieraccini , 1997 ), where the goal is to provide information to the user , there is already extensi ve use of external knowledge sources. F or example, in the Let’ s Go! dialogue system ( Raux et al. , 2005 ), the user requests information about various bus arri v al and departure times. Thus, a critical input to the model is the actual bus schedule, which is 32 used in order to generate the system’ s utterances. Another e xample is the dialogue system described by N ¨ oth et al. ( 2004 ), which helps users find movie information by utilizing movie sho wtimes from dif ferent cinemas. Such e xamples are abundant both in the literature and in practice. Although these models mak e use of external knowledge, the kno wledge sources in these cases are highly structured and are only used to place hard constraints on the possible states of an utterance to be generated. They are essentially contained in relational databases or structured ontologies, and are only used to provide a deterministic mapping from the dialogue states extracted from an input user utterance to the dialogue system state or the generated response. Complementary to domain-specific databases and ontologies are the general natural language processing databases and tools. These include lexical databases such as W ordNet ( Miller , 1995 ), which contains lexical relationships between words for o ver a hundred thousand words, V erbNet ( Schuler , 2005 ) which contains lexical relations between verbs, and FrameNet ( Ruppenhofer et al. , 2006 ), which contains ’w ord senses’ for o ver ten thousand w ords along with e xamples of each word sense. In addition, there e xist several natural language processing tools such as part of speech taggers, word category classifiers, w ord embedding models, named entity recognition models, co- reference resolution models, semantic role labeling models, semantic similarity models and sen- timent analysis models ( Manning and Sch ¨ utze , 1999 ; Jurafsky and Martin , 2008 ; Mikolo v et al. , 2013 ; Gurevych and Strube , 2004 ; Lin and W alker , 2011b ) that may be used by the Natural Lan- guage Interpreter to e xtract meaning from human utterances. Since these tools are typically b uilt upon texts and annotations created by humans, using them inside a dialogue system can be inter - preted as a form of structured transfer learning, where the relationships or labels learned from the original natural language processing corpus provide additional information to the dialogue system and improv e generalization of the system. 5 . 5 . 2 U N S T RU C T U R E D E X T E R N A L K N O W L E D G E Complementary sources of information can be found in unstructured kno wledge sources, such as online encyclopedias (W ikipedia ( Denoyer and Gallinari , 2007 )) as well as domain-specific sources ( Lowe et al. , 2015b ). It is be yond the scope of this paper to re vie w all possible w ays that these unstructured knowledge sources have or could be used in conjunction with a data-dri ven dialogue system. Howe ver , we note that this is likely to be a fruitful research area. 5.6 Personalized dialogue agents When con versing, humans often adapt to their interlocutor to facilitate understanding, and thus improv e con versational ef ficiency and satisfaction. Attaining human-le vel performance with dia- logue agents may well require personalization, i.e. models that are aware and capable of adapting to their intelocutor . Such capabilities could increase the effecti veness and naturalness of generated dialogues ( Lucas et al. , 2009 ; Su et al. , 2013 ). W e see personalization of dialogue systems as an important task, which so far has not recei ved much attention. There has been initial ef forts on user- specific models which could be adapted to work in combination with the dialogue models presented in this surv ey ( Lucas et al. , 2009 ; Lin and W alker , 2011a ; Pargellis et al. , 2004 ). There has also been interesting work on character modeling in movies ( W alker et al. , 2011 ; Li et al. , 2016 ; Mo et al. , 2016 ). There is significant potential to learn user models as part of dialogue models. The large datasets presented in this paper , some of which provide multiple dialogues per user , may enable the de velopment of such models. 33 5.7 Evaluation metrics One of the most challenging aspects of constructing dialogue systems lies in their e valuation. While the end goal is to deploy the dialogue system in an application setting and receive real human feed- back, getting to this stage is time consuming and expensi ve. Often it is also necessary to optimize performance on a pseudo-performance metric prior to release. This is particularly true if a dialogue model has many hyper-parameters to be optimized—it is infeasible to run user experiments for every parameter setting in a grid search. Although crowdsourcing platforms, such as Amazon Mechanical T urk, can be used for some user testing ( Jurcıcek et al. , 2011 ), e v aluations using paid subjects can also lead to biased results ( Y oung et al. , 2013 ). Ideally , we would hav e some automated metrics for calculating a score for each model, and only in volve human ev aluators once the best model has been chosen with reasonable confidence. The e valuation problem also arises for non-goal-driven dialogue systems. Here, researchers hav e focused mainly on the output of the response generation module. Ev aluation of such non-goal- dri ven dialogue systems can be traced back to the T uring test ( T uring , 1950 ), where human judges communicate with both computer programs and other humans o ver a chat terminal without kno wing each other’ s true identity . The goal of the judges w as to identify the humans and computer programs under the assumption that a program indistinguishable from a real human being must be intelligent. Ho we ver , this setup has been criticized e xtensi vely with numerous researchers proposing alterna- ti ve ev aluation procedures ( Cohen , 2005 ). More recently , researchers ha ve turned to analyzing the collected dialogues produced after the y are finished ( Galle y et al. , 2015 ; P ietquin and Hastie , 2013 ; Shaw ar and Atwell , 2007a ; Schatzmann et al. , 2005 ). Even when human ev aluators are av ailable, it is often dif ficult to choose a set of informative and consistent criteria that can be used to judge an utterance generated by a dialogue system. F or example, one might ask the ev aluator to rate the utterance on vague notions such as ‘appropriateness’ and ‘naturalness’, or to try to differentiate between utterances generated by the system and those generated by actual humans ( V in yals and Le , 2015 ). Schatzmann et al. ( 2005 ) suggest two aspects that need to be e valuated for all response generation systems (as well as user simulation models): 1) if the model can generate human-like output, and 2) if the model can reproduce the v ariety of user behaviour found in corpus. But we lack a definiti ve frame work for such ev aluations. W e complete this discussion by summarizing different approaches to the automatic ev aluation problem as they relate to these objecti ves. 5 . 7 . 1 A U T O M A T I C E V A L UAT I O N M E T R I C S F O R G OA L - D R I V E N D I A L O G U E S Y S T E M S User ev aluation of goal-driven dialogue systems typically focuses on goal-related performance cri- teria, such as goal completion rate, dialogue length, and user satisfaction ( W alker et al. , 1997 ; Schatzmann et al. , 2005 ). These were originally ev aluated by human users interacting with the dialogue system, b ut more recently researchers have also be gun to use third-party annotators for e v aluating recorded dialogues ( Y ang et al. , 2010 ). Due to their simplicity , the vast majority of hand- crafted task-oriented dialogue systems have been solely ev aluated in this w ay . Ho wever , when using machine learning algorithms to train on large-scale corpora, automatic optimization criteria are re- quired. The challenge with e v aluating goal-driv en dialogue systems without human intervention is that the process necessarily requires multiple steps—it is difficult to determine if a task has been solved from a single utterance-response pair from a con versation. Thus, simulated data is often gen- erated by a user simulator ( Eckert et al. , 1997 ; Schatzmann et al. , 2007 ; Jung et al. , 2009 ; Georgila 34 et al. , 2006 ; Pietquin and Hastie , 2013 ). Given a sufficiently accurate user simulation model, an interaction between the dialogue system and the user can be simulated from which it is possible to deduce the desired metrics, such as goal completion rate. Significant effort has been made to render the simulated data as realistic as possible, by modeling user intentions. Ev aluation of such simulation methods has already been conducted ( Schatzmann et al. , 2005 ). Howe ver , generating realistic user simulation models remains an open problem. 5 . 7 . 2 A U T O M A T I C E V A L UAT I O N M E T R I C S F O R N O N - G O A L - D R I V E N D I A L O G U E S Y S T E M S Ev aluation of non-goal-driv en dialogue systems, whether by automatic means or user studies, re- mains a dif ficult challenge. W ord Ov erlap Metrics . One approach is to borro w ev aluation metrics from other NLP tasks such as machine translation, which uses BLEU ( Papineni et al. , 2002 ) and METEOR ( Banerjee and Lavie , 2005 ) scores. These metrics hav e been used to compare responses generated by a learned dialogue strategy to the actual next utterance in the con versation, conditioned on a dialogue context ( Sordoni et al. , 2015b ). While BLEU scores ha ve been shown to correlate with human judgements for machine translation ( P apineni et al. , 2002 ), their effecti veness for automatically assessing di- alogue response generation is unclear . There are se veral issues to consider: giv en the conte xt of a con versation, there often e xists a large number of possible responses that ‘fit’ into the dialogue. Thus, the response generated by a dialogue system could be entirely reasonable, yet it may ha ve no words in common with the actual next utterance. In this case, the BLEU score would be very low , but would not accurately reflect the strength of the model. Indeed, e ven humans who are task ed with predicting the next utterance of a conv ersation achiev e relati vely low BLEU scores ( Sordoni et al. , 2015b ). Although the METEOR metric takes into account synon yms and morphological v ariants of words in the candidate response, it still suffers from the aforementioned problems. In a sense, these measurements only satisfy one direction of Schatzmann’ s criteria: high BLEU and METEOR scores imply that the model is generating human-like output, but the model may still not reproduce the variety of user beha viour found in corpus. Furthermore, such metrics will only accurately re- flect the performance of the dialogue system if giv en a large number of candidate responses for each gi ven conte xt. Next Utterance Classification . Alternati vely , one can narro w the number of possible responses to a small, pre-defined list, and ask the model to select the most appropriate response from this list. The list includes the actual next response of the con versation (the desired prediction), and the other entries (false positiv es) are sampled from elsewhere in the corpus ( Lowe et al. , 2016 , 2015a ). This ne xt utterance classification (NUC) task is deri ved from the recall and precision metrics for information-retrie v al-based approaches. There are sev eral attracti ve properties of this metric: it is easy to interpret, and the difficulty can be adjusted by changing the number of false responses. Ho we ver , there are dra wbacks. In particular , since the other candidate answers are sampled from else where in the corpus, there is a chance that these also represent reasonable responses giv en the context. This can be alle viated to some e xtent by reporting Recall@k measures, i.e. whether the correct response is found in the k responses with the highest rankings according to the model. Although current models ev aluated using NUC are trained explicitly to maximize the performance on this metric by minimizing the cross-entropy between context-response pairs ( Lo we et al. , 2015a ; Kadlec et al. , 2015 ), the metric could also be used to e valuate a probabilistic generati ve model trained to output full utterances. 35 W ord P erplexity . Another metric proposed to ev aluate probabilistic language models ( Bengio et al. , 2003 ; Mikolo v et al. , 2010 ) that has seen significant recent use for ev aluating end-to-end dialogue systems is wor d perple xity ( Pietquin and Hastie , 2013 ; Serban et al. , 2016 ). Perplexity e x- plicitly measures the probability that the model will generate the ground truth ne xt utterance gi ven some context of the con versation. This is particularly appealing for dialogue, as the distribution over words in the next utterance can be highly multi-modal (i.e. many possible responses). A re-weighted perplexity metric has also been proposed where stop-words, punctuation, and end-of-utterance to- kens are remo ved before ev aluating to focus on the semantic content of the phrase ( Serban et al. , 2016 ). Both word perplexity , as well as utterance-le vel recall and precision outlined above, satisfy Schatzmann’ s ev aluation criteria, since scoring high on these would require the model to produce human-like output and to reproduce most types of con versations in the corpus. Response Diversity . Recent non-goal-driven dialogue systems based on neural networks ha ve had problems generating di verse responses ( Serban et al. , 2016 ). ( Li et al. , 2015 ) recently intro- duced tw o ne w metrics, distinct-1 and distinct-2 , which respecti vely measure the number of distinct unigrams and bigrams of the generated responses. Although these fail to satisfy either of Schatz- mann’ s criteria, they may still be useful in combination with other metrics, such as BLEU, NUC or word perple xity . 6. Conclusion There is strong evidence that over the next few years, dialogue research will quickly mov e tow ards large-scale data-dri ven model approaches. In particular , as is the case for other language-related applications such as speech recognition, machine translation and information retriev al, these ap- proaches will likely come in the form of end-to-end trainable systems. This paper provides an extensi ve surve y of currently av ailable datasets suitable for research, de velopment, and ev aluation of such data-dri ven dialogue systems. In addition to presenting the datasets, we pro vide a detailed discussion of sev eral of the is- sues related to the use of datasets in dialogue system research. Several potential directions are highlighted, such as transfer learning and incorporation of external knowledge, which may lead to scalable solutions for end-to-end training of con versational agents. Acknowledgements The authors gratefully acknowledge financial support by the Samsung Adv anced Institute of T ech- nology (SAIT), the Natural Sciences and Engineering Research Council of Canada (NSERC), the Canada Research Chairs, the Canadian Institute for Advanced Research (CIF AR) and Compute Canada. Early versions of the manuscript benefited greatly from the proofreading of Melanie L yman-Abramovitch, and later versions were extensiv ely revised by Gene vie ve Fried and Nico- las Angelard-Gontier . The authors also thank Nissan Pow , Michael Noseworthy , Chia-W ei Liu, Gabriel F orgues, Alessandro Sordoni, Y oshua Bengio and Aaron Courville for helpful discussions. References B. Aarts and S. A. W allis. The diachronic corpus of present-day spoken english (DCPSE), 2006. R. Abbott, B. Ecker , P . Anand, and M. W alker . Internet argument corpus 2.0: An sql schema for dialogic social media and the corpora to go with it. In Language Resour ces and Evaluation Conference , LREC2016 , 2016. 36 S. Afantenos, N. Asher , F . Benamara, A. Cadilhac, C ´ edric D ´ egremont, P . Denis, M. Guhe, S. Keizer , A. Lascarides, O. Lemon, et al. Developing a corpus of strategic con versation in the settlers of catan. In SeineDial 2012-The 16th workshop on the semantics and pragmatics of dialo gue , 2012. Y . Al-Onaizan, U. Germann, U. Hermjakob, K. Knight, P . K oehn, D. M., and K. Y amada. T ranslating with scarce resources. In AAAI , 2000. J. Alexandersson, R. Engel, M. Kipp, S. K och, U. K ¨ ussner , N. Reithinger, and M. Stede. Modeling negotiation dialogs. In V erbmobil: F oundations of Speech-to-Speech T ranslation , pages 441–451. Springer , 2000. D. Ameixa and L. Coheur . From subtitles to human interactions: introducing the subtle corpus. T echnical report, T ech. rep., 2013. D. Ameixa, Luisa Coheur , P . Fialho, and P . Quaresma. Luke, I am your father: dealing with out-of-domain requests by using movies subtitles. In Intelligent V irtual Agents , pages 13–21, 2014. A. H. Anderson, M. Bader , E. G. Bard, E. Bo yle, G. Doherty , S. Garrod, S. Isard, J. K owtko, J. McAllister , J. Miller , et al. The HCRC map task corpus. Language and speec h , 34(4):351–366, 1991. J. Andreas, S. Rosenthal, and K. McKeo wn. Annotating agreement and disagreement in threaded discussion. In LREC , pages 818–822. Citeseer , 2012. L. E. Asri, J. He, and K. Suleman. A sequence-to-sequence model for user simulation in spoken dialogue systems. arXiv pr eprint arXiv:1607.00070 , 2016. A. J. Aubrey , D. Marshall, P . L. Rosin, J. V ande venter, D. W . Cunningham, and C. W allra ven. Cardiff conv ersation database (CCDb): A database of natural dyadic conv ersations. In Computer V ision and P attern Recognition W orkshops (CVPRW), IEEE Confer ence on , pages 277–282, 2013. H. Aust, M. Oerder , F . Seide, and V . Steinbiss. The philips automatic train timetable information system. Speech Communication , 17(3):249–262, 1995. A. A w , M. Zhang, J. Xiao, and J. Su. A phrase-based statistical model for sms text normalization. In Pr oceedings of the COLING , pages 33–40, 2006. R. E. Banchs. Movie-DiC: a movie dialogue corpus for research and development. In Pr oceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Short P apers , 2012. R. E. Banchs and H. Li. IRIS: a chat-oriented dialogue system based on the vector space model. In Proceedings of the A CL 2012 System Demonstrations , 2012. S. Banerjee and A. La vie. METEOR: An automatic metric for mt e v aluation with improv ed correlation with human judgments. In Pr oceedings of the ACL workshop on intrinsic and extrinsic evaluation measur es for machine translation and/or summarization , 2005. M. Barlow . Corpus of spoken, professional american-english, 2000. J. Beare and B. Scott. The spok en corpus of the survey of english dialects: language v ariation and oral history . In Pr oceedings of ALLC/ACH , 1999. Y . Bengio, R. Ducharme, P . V incent, and C. Jan vin. A neural probabilistic language model. The J ournal of Machine Learning Resear ch , 3:1137–1155, 2003. Y . Bengio, I. Goodfellow , and A. Courville. Deep learning. An MIT Pr ess book in prepar ation. Draft chapter s available at http://www . ir o. umontreal. ca/ bengioy/dlbook , 2014. C. Bennett and A. I Rudnicky . The carnegie mellon communicator corpus, 2002. D. Biber and E. Fineg an. An initial typology of english text types. Corpus linguistics II: New studies in the analysis and exploitation of computer corpor a , pages 19–46, 1986. D. Biber and E. Fine gan. Diachronic relations among speech-based and written registers in english. V ariation in English: multi-dimensional studies , pages 66–83, 2001. S. Bird, S. Bro wning, R. Moore, and M. Russell. Dialogue mov e recognition using topic spotting techniques. In Spoken Dialogue Systems-Theories and Applications , 1995. A. W . Black, S. Burger , A. Conkie, H. Hastie, S. Keizer , O. Lemon, N. Merigaud, G. Parent, G. Schubiner , B. Thomson, et al. Spoken dialog challenge 2010: Comparison of liv e and control test results. In Special Interest Gr oup on Discourse and Dialogue (SIGDIAL) , 2011. D. Bohus and A. I Rudnicky . Sorry , I didnt catch that! In Recent T r ends in Discourse and Dialogue , pages 123–154. Springer , 2008. S. E. Brennan, K. S. Schuhmann, and K. M. Batres. Entrainment on the move and in the lab: The walking around corpus. In Pr oceedings of the 35th Annual Conference of the Cognitive Science Society , 2013. G. Brown, A. Anderson, R. Shillcock, and G. Y ule. T eaching talk. Cambridge: CUP , 1984. S. Burger , K. W eilhammer , F . Schiel, and H. G. T illmann. V erbmobil data collection and annotation. In V erbmobil: F oundations of speech-to-speech tr anslation , pages 537–549. Springer , 2000. 37 J. E. Cahn and S. E. Brennan. A psychological model of grounding and repair in dialog. In AAAI Symposium on Psychological Models of Communication in Collabor ative Systems , 1999. A. Canavan and G. Zipperlen. Callfriend american english-non-southern dialect. Linguistic Data Consortium , 10:1, 1996. A. Canav an, D. Graff, and G. Zipperlen. Callhome american english speech. Linguistic Data Consortium , 1997. S. K. Card, T . P . Moran, and A. Newell. The Psychology of Human-Computer Interaction . L. Erlbaum Associates Inc., Hillsdale, NJ, USA, 1983. ISBN 0898592437. R. Carter . Orders of reality: Cancode, communication, and culture. ELT journal , 52(1):43–56, 1998. R. Carter and M. McCarthy . Cambridge grammar of English: a compr ehensive guide; spoken and written English grammar and usag e . Ernst Klett Sprachen, 2006. T anya L. Chartrand and J. A. Bargh. The chameleon effect: the perception–behavior link and social interaction. J ournal of personality and social psycholo gy , 76(6):893, 1999. T . Chen and M. Kan. Creating a live, public short message service corpus: the nus sms corpus. Languag e Resour ces and Evaluation , 47(2):299–335, 2013. Y .-N. Chen, D. Hakkani-T ¨ ur , and X. He. Zero-shot learning of intent embeddings for expansion by conv olutional deep structured semantic models. In Acoustics, Speech and Signal Processing (ICASSP), 2016 IEEE International Confer - ence on , pages 6045–6049. IEEE, 2016. A. Clark. Pre-processing very noisy text. In Pr oc. of W orkshop on Shallow Processing of Large Corpora , pages 12–22, 2003. H. H. Clark and S. E. Brennan. Grounding in communication. P erspectives on socially shared cognition , 13:127–149, 1991. P . R. Cohen. If not turing’ s test, then what? AI ma gazine , 26(4):61, 2005. K. M. Colby . Modeling a paranoid mind. Behavioral and Brain Sciences , 4:515–534, 1981. R. M. Cooper . The control of eye fixation by the meaning of spoken language: A new methodology for the real-time in vestigation of speech perception, memory , and language processing. Cognitive Psychology , 6(1):84–107, 1974. N. Cristianini and J. Shawe-T aylor . An Intr oduction to Support V ector Machines: And Other Kernel-based Learning Methods . Cambridge Univ ersity Press, 2000. H. Cuay ´ ahuitl, S. Renals, O. Lemon, and H. Shimodaira. Human-computer dialogue simulation using hidden markov models. In Automatic Speec h Recognition and Understanding , 2005 IEEE W orkshop on , pages 290–295, 2005. H. Cuay ´ ahuitl, S. K eizer , and O. Lemon. Strategic dialogue management via deep reinforcement learning. arXiv pr eprint arXiv:1511.08099 , 2015. C. Danescu-Niculescu-Mizil and L. Lee. Chameleons in imagined con versations: A new approach to understanding coordination of linguistic style in dialogs. In Pr oceedings of the W orkshop on Cognitive Modeling and Computational Linguistics, A CL , 2011. L. Daubigney , M. Geist, S. Chandramohan, and O. Pietquin. A comprehensive reinforcement learning framew ork for dialogue management optimization. IEEE Journal of Selected T opics in Signal Pr ocessing , 6(8):891–902, 2012. M. Davies. Comparing the corpus of american soap operas, COCA, and the BNC, 2012a. M. Davies. Corpus of american soap operas, 2012b. I. de Kok, D. He ylen, and L. Morency . Speaker-adapti ve multimodal prediction model for listener responses. In Pr oceed- ings of the 15th A CM on International confer ence on multimodal interaction , 2013. L. Deng and X. Li. Machine learning paradigms for speech recognition: An overvie w . Audio, Speech, and Language Pr ocessing, IEEE T ransactions on , 21(5):1060–1089, 2013. L. Denoyer and P . Gallinari. The wikipedia xml corpus. In Compar ative Evaluation of XML Information Retrieval Systems , pages 12–19. Springer , 2007. B. Dhingra, Z. Zhou, D. Fitzpatrick, M. Muehl, and W . Cohen. T weet2vec: Character-based distributed representations for social media. arXiv pr eprint arXiv:1605.03481 , 2016. A. Djalali, S. Lauer , and C. Potts. Corpus e vidence for preference-driven interpretation. In Logic, Language and Meaning , pages 150–159. Springer , 2012. J. Dodge, A. Gane, X. Zhang, A. Bordes, S. Chopra, A. Miller, A. Szlam, and J. W eston. Evaluating prerequisite qualities for learning end-to-end dialog systems. arXiv pr eprint arXiv:1511.06931 , 2015. S. Dose. Flipping the script: A corpus of american tele vision series (cats) for corpus-based language learning and teaching. Corpus Linguistics and V ariation in English: F ocus on Non-native Englishes , 2013. E. Douglas-Co wie, R. Co wie, I. Sneddon, C. Cox, O. Lowry , M. Mcrorie, J. Martin, L. Devillers, S. Abrilian, A. Batliner, et al. The humaine database: addressing the collection and annotation of naturalistic and induced emotional data. In Affective computing and intellig ent interaction , pages 488–500. Springer , 2007. 38 W . Eckert, E. Levin, and R. Pieraccini. User modeling for spoken dialogue system ev aluation. In Automatic Speech Recognition and Understanding , 1997. Pr oceedings., 1997 IEEE W orkshop on , pages 80–87, 1997. L. El Asri, H. Schulz, S. Sharma, J. Zumer, J. Harris, E. Fine, R. Mehrotra, and K. Suleman. Frames: Acorpus for adding memory to goal-oriented dialogue systems. preprint on webpage at http://www.maluuba.com/ publications/ , 2017. M. Elsner and E. Charniak. Y ou talking to me? a corpus and algorithm for con versation disentanglement. In Association for Computational Linguistics (A CL) , 2008. D. Erhan, Y . Bengio, A. Courville, Pierre-A. Manzagol, and P . V incent. Why does unsupervised pre-training help deep learning? Journal of Mac hine Learning Resear ch , 11, 2010. G. Di Fabbrizio, G. Tur , and D. Hakkani-Tr . Bootstrapping spoken dialog systems with data reuse. In Special Inter est Gr oup on Discourse and Dialogue (SIGDIAL) , 2004. M. Fatemi, L. E. Asri, H. Schulz, J. He, and K. Suleman. Policy networks with two-stage training for dialogue systems. In Special Inter est Gr oup on Discourse and Dialogue (SIGDIAL) , 2016. D. Fisher , M. Smith, and H. T W elser . Y ou are who you talk to: Detecting roles in usenet ne wsgroups. In Pr oceedings of the 39th Annual Hawaii International Confer ence on System Sciences (HICSS’06) , volume 3, pages 59b–59b, 2006. P . Forchini. Spontaneity reloaded: American face-to-face and movie con versation compared. In Corpus Linguistics , 2009. P . Forchini. Movie languag e r evisited. Evidence fr om multi-dimensional analysis and corpora . Peter Lang, 2012. G. For gues, J. Pineau, J. Larchev ˆ eque, and R. T remblay . Bootstrapping dialog systems with word embeddings. In W ork- shop on Modern Machine Learning and Natural Language Processing , Advances in neural information pr ocessing systems (NIPS) , 2014. E. N. Forsyth and C. H. Martell. Lexical and discourse analysis of online chat dialog. In International Confer ence on Semantic Computing (ICSC). , pages 19–26, 2007. M. Frampton and O. Lemon. Recent research advances in reinforcement learning in spoken dialogue systems. The Knowledge Engineering Revie w , 24(04):375–408, 2009. M. Galley , C. Brockett, A. Sordoni, Y . Ji, M. Auli, C. Quirk, M. Mitchell, J. Gao, and B. Dolan. deltaBLEU: A dis- criminativ e metric for generation tasks with intrinsically div erse targets. In Proceedings of the 53r d Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Confer ence on Natural Languag e Pr ocessing of the Asian F ederation of Natural Languag e Pr ocessing, ACL , pages 445–450, 2015. M. Ga ˇ si ´ c, F . Jur ˇ c ´ ı ˇ cek, S. K eizer , F . Mairesse, B. Thomson, K. Y u, and S. Y oung. Gaussian processes for fast policy optimisation of pomdp-based dialogue managers. In Proceedings of the 11th Annual Meeting of the Special Interest Gr oup on Discourse and Dialogue , pages 201–204. Association for Computational Linguistics, 2010. M. Ga ˇ si ´ c, F . Jur ˇ c ´ ı ˇ cek, B. Thomson, K. Y u, and S. Y oung. On-line policy optimisation of spoken dialogue systems via li ve interaction with human subjects. In IEEE W orkshop on Automatic Speech Recognition and Understanding (ASRU) , pages 312–317. IEEE, 2011. M. Ga ˇ si ´ c, M. Henderson, B. Thomson, P . Tsiakoulis, and S. Y oung. Policy optimisation of pomdp-based dialogue systems without state space compression. In Spoken Language T echnology W orkshop (SLT), 2012 IEEE , pages 31–36. IEEE, 2012. M. Gasic, C. Breslin, M. Henderson, D. Kim, M. Szummer , B. Thomson, P . Tsiakoulis, and S. Y oung. On-line pol- icy optimisation of Bayesian spoken dialogue systems via human interaction. In IEEE International Conference on Acoustics, Speech and Signal Pr ocessing , pages 8367–8371, 2013. M. Ga ˇ si ´ c, N. Mrk ˇ si ´ c, L. M. Rojas-Barahona, P .-H. Su, S. Ultes, D. V andyke, T .-H. W en, and S. Y oung. Dialogue manager domain adaptation using gaussian process reinforcement learning. Computer Speech & Langua ge , 2016. A. Gene vay and R. Laroche. Transfer learning for user adaptation in spoken dialogue systems. In Pr oceedings of the 2016 International Confer ence on Autonomous Ag ents & Multiagent Systems , pages 975–983. International Foundation for Autonomous Agents and Multiagent Systems, 2016. K. Georgila, J. Henderson, and O. Lemon. User simulation for spoken dialogue systems: learning and ev aluation. In Pr oceedings of INTERSPEECH , 2006. K. Geor gila, M. W olters, J. D. Moore, and R. H. Logie. The MA TCH corpus: A corpus of older and younger users interactions with spoken dialogue systems. Languag e Resour ces and Evaluation , 44(3):221–261, 2010. J. Gibson and A. D. Pick. Perception of another person’ s looking behavior . The American journal of psychology , 76(3): 386–394, 1963. J. J Godfrey , E. C Holliman, and J McDaniel. SWITCHBOARD: T elephone speech corpus for research and development. In International Confer ence on Acoustics, Speech, and Signal Pr ocessing (ICASSP-92) , 1992. 39 I. Goodfellow , A. Courville, and Y . Bengio. Deep learning. Book in preparation for MIT Press, 2015. URL http: //goodfeli.github.io/dlbook/ . J. T . Goodman. A bit of progress in language modeling extended version. Machine Learning and Applied Statistics Gr oup Microsoft Resear ch. T echnical Report, MSR-TR-2001-72 , 2001. C. Goodwin. Conversational Organization: Interaction Between Speakers and Hear ers . New Y ork: Academic Press, 1981. A. L. Gorin, G. Riccardi, and J. H. Wright. How may I help you? Speec h Communication , 23(1):113–127, 1997. A. Graves. Sequence transduction with recurrent neural networks. In Pr oceedings of the 29th International Conference on Machine Learning (ICML), Repr esentation Learning W orkshop , 2012. A. Grav es, G. W ayne, and I. Danihelka. Neural turing machines. arXiv pr eprint arXiv:1410.5401 , 2014. S. Greenbaum. Comparing English worldwide: The international corpus of English . Clarendon Press, 1996. S. Greenbaum and G Nelson. The international corpus of english (ICE) project. W orld Englishes , 15(1):3–15, 1996. C. G ¨ ulc ¸ ehre, O. Firat, K. Xu, K. Cho, L. Barrault, H. Lin, F . Bougares, H. Schwenk, and Y . Bengio. On using monolingual corpora in neural machine translation. CoRR , abs/1503.03535, 2015. I. Gurevych and M. Strube. Semantic similarity applied to spoken dialogue summarization. In Pr oceedings of the 20th international confer ence on Computational Linguistics , 2004. V . Haslerud and A. Stenstr ¨ om. The bergen corpus of london teenager language (COL T). Spoken English on Computer . T ranscription, Mark-up and Application. London: Longman , pages 235–242, 1995. P . A. Heeman and J. F . Allen. The TRAINS 93 Dialogues. T echnical report, DTIC Document, 1995. C. T . Hemphill, J. J. Godfrey , and G. R. Doddington. The atis spoken language systems pilot corpus. In Pr oceedings of the D ARP A speech and natural language workshop , pages 96–101, 1990. M. Henderson, B. Thomson, and S. Y oung. Deep neural network approach for the dialog state tracking challenge. In Special Inter est Gr oup on Discourse and Dialogue (SIGDIAL) , 2013. M. Henderson, B. Thomson, and J. W illiams. Dialog state tracking challenge 2 & 3, 2014a. M. Henderson, B. Thomson, and J. W illiams. The second dialog state tracking challenge. In Special Inter est Group on Discourse and Dialogue (SIGDIAL) , 2014b. M. Henderson, B. Thomson, and S. Y oung. W ord-based dialog state tracking with recurrent neural networks. In 15th Special Inter est Gr oup on Discourse and Dialogue (SIGDIAL) , page 292, 2014c. G. Hinton, L. Deng, D. Y u, G. E. Dahl, A. Mohamed, N. Jaitly , A. Senior , V . V anhoucke, P . Nguyen, T .a N. Sainath, et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. Signal Pr ocessing Magazine, IEEE , 29(6):82–97, 2012. T . Hiraoka, G. Neubig, K. Y oshino, T . T oda, and S. Nakamura. Activ e learning for example-based dialog systems. In Pr oc Intl W orkshop on Spoken Dialog Systems, Saariselka, F inland , 2016. H. Hung and G. Chittaranjan. The IDIAP w olf corpus: exploring group beha viour in a competiti ve role-playing g ame. In Pr oceedings of the international conference on Multimedia , pages 879–882, 2010. J. L. Hutchens and M. D. Alder . Introducing MegaHAL. In Proceedings of the Joint Confer ences on New Methods in Language Pr ocessing and Computational Natural Languag e Learning , 1998. Arne J. and Nils D. T alking to a computer is not like talking to your best friend. In Pr oceedings of The first Scandinivian Confer ence on Artificial Intelligence , 1988. S. Jung, C. Lee, K. Kim, M. Jeong, and G. G. Lee. Data-driven user simulation for automated e valuation of spoken dialog systems. Computer Speech & Languag e , 23(4):479–509, 2009. D. Jurafsky and J. H. Martin. Speec h and language pr ocessing, 2nd Edition . Prentice Hall, 2008. F . Jurcıcek, S. K eizer , M. Ga ˇ sic, F . Mairesse, B. Thomson, K. Y u, and S. Y oung. Real user e valuation of spoken dialogue systems using amazon mechanical turk. In Pr oceedings of INTERSPEECH , volume 11, 2011. F . Jur ˇ c ´ ı ˇ cek, B. Thomson, and S. Y oung. Reinforcement learning for parameter estimation in statistical spoken dialogue systems. Computer Speech & Languag e , 26(3):168–192, 2012. R. Kadlec, M. Schmid, and J. Kleindienst. Improved deep learning baselines for ubuntu corpus dialogs. Neural Informa- tion Pr ocessing Systems W orkshop on Machine Learning for Spoken Langua ge Understanding , 2015. M. Kaufmann and J. Kalita. Syntactic normalization of twitter messages. In International confer ence on natural language pr ocessing, Kharagpur , India , 2010. S. Kim, L. F . DHaro, R. E. Banchs, J. W illiams, and M. Henderson. Dialog state tracking challenge 4, 2015. S. Kim, L. F . DHaro, R. E. Banchs, J. D. W illiams, M. Henderson, and K. Y oshino. The fifth dialog state tracking challenge. In IEEE Spoken Languag e T ec hnology W orkshop (SLT) , 2016. D. K oller and N. Friedman. Pr obabilistic graphical models: principles and techniques . MIT press, 2009. 40 J. A Konstan, B. N. Miller , D. Maltz, J. L. Herlocker , L. R. Gordon, and J. Riedl. Grouplens: applying collaborativ e filtering to usenet news. Communications of the ACM , 40(3):77–87, 1997. A. Kumar , O. Irsoy , J. Su, J. Bradbury , R. English, B. Pierce, P . Ondruska, I. Gulrajani, and R. Socher . Ask me anything: Dynamic memory networks for natural language processing. Neural Information Pr ocessing Systems (NIPS) , 2015. M. Kyt ¨ o and T . W alk er . Guide to A corpus of English dialogues 1560-1760 . Acta Univ ersitatis Upsaliensis, 2006. I. Langkilde and K. Knight. Generation that exploits corpus-based statistical knowledge. In Pr oceedings of the 36th An- nual Meeting of the Association for Computational Linguistics and 17th International Conference on Computational Linguistics-V olume 1 , pages 704–710. Association for Computational Linguistics, 1998. G. Leech. 100 million words of english: the british national corpus (BNC). Language Resear ch , 28(1):1–13, 1992. E. Levin and R. Pieraccini. A stochastic model of computer-human interaction for learning dialogue strategies. In Eur ospeech , volume 97, pages 1883–1886, 1997. E. Le vin, R. Pieraccini, and W . Eckert. Learning dialogue strategies within the markov decision process framework. In Automatic Speech Recognition and Understanding, 1997. Pr oceedings., 1997 IEEE W orkshop on , pages 72–79. IEEE, 1997. J. Li, M. Galley , C. Brockett, J. Gao, and B. Dolan. A diversity-promoting objective function for neural conversation models. arXiv pr eprint arXiv:1510.03055 , 2015. J. Li, M. Galley , C. Brockett, J. Gao, and Bill D. A persona-based neural conv ersation model. In A CL , pages 994–1003, 2016. G. Lin and M. W alker . All the world’ s a stage: Learning character models from film. In AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment , 2011a. G. I. Lin and M. A. W alker . All the world’ s a stage: Learning character models from film. In AIIDE , 2011b. C. Lord and M. Haith. The perception of eye contact. Attention, P erception, & Psychophysics , 16(3):413–416, 1974. R. Lowe, N. Po w , I. Serban, and J. Pineau. The ubuntu dialogue corpus: A large dataset for research in unstructured multi-turn dialogue systems. In Special Inter est Gr oup on Discourse and Dialogue (SIGDIAL) , 2015a. R. Lowe, N. Po w , I. V . Serban, L. Charlin, and J. Pineau. Incorporating unstructured textual knowledge sources into neural dialogue systems. Neural Information Pr ocessing Systems W orkshop on Mac hine Learning for Spoken Language Understanding , 2015b. R. Lowe, I. V . Serban, M. Noseworthy , L. Charlin, and J. Pineau. On the e v aluation of dialogue systems with next utterance classification. In Special Inter est Gr oup on Discourse and Dialogue (SIGDIAL) , 2016. J. M. Lucas, F . Fernndez, J. Salazar, J. Ferreiros, and R. San Segundo. Managing speaker identity and user profiles in a spoken dialogue system. In Pr ocesamiento del Lenguaje Natural , number 43 in 1, pages 77–84, 2009. B. MacWhinney and C. Snow . The child language data exchange system. Journal of child language , 12(02):271–295, 1985. F . Mairesse and S. Y oung. Stochastic language generation in dialogue using factored language models. Computational Linguistics , 2014. F . Mairesse, M. Ga ˇ si ´ c, F . Jur ˇ c ´ ı ˇ cek, S. Keizer , B. Thomson, K. Y u, and S. Y oung. Phrase-based statistical language generation using graphical models and activ e learning. In Pr oceedings of the 48th Annual Meeting of the Association for Computational Linguistics , pages 1552–1561. Association for Computational Linguistics, 2010. C. D. Manning and H. Sch ¨ utze. F oundations of statistical natural language pr ocessing . MIT press, 1999. M. McCarthy . Spoken languag e and applied linguistics . Ernst Klett Sprachen, 1998. S. McGlashan, N. Fraser , N. Gilbert, E. Bilange, P . Heisterkamp, and N. Y oud. Dialogue management for telephone information systems. In Pr oceedings of the thir d confer ence on Applied natur al language pr ocessing , pages 245–246. Association for Computational Linguistics, 1992. G. McKeo wn, M. F V alstar , R. Cowie, and M. Pantic. The SEMAINE corpus of emotionally coloured character interac- tions. In Multimedia and Expo (ICME), 2010 IEEE International Confer ence on , pages 1079–1084, 2010. T . Mikolo v , M. Karafi ´ at, L. Burget, J. Cernock ` y, and Sanjeev Khudanpur . Recurrent neural network based language model. In 11th Pr oceedings of INTERSPEECH , pages 1045–1048, 2010. T . Mik olov , I. Sutske ver , K. Chen, G. S. Corrado, and J. Dean. Distributed representations of w ords and phrases and their compositionality . In Advances in neural information pr ocessing systems , pages 3111–3119, 2013. G. A. Miller . W ordNet: a lexical database for english. Communications of the ACM , 38(11):39–41, 1995. X. A. Miro, S. Bozonnet, N. Evans, C. Fredouille, G. Friedland, and O. V inyals. Speaker diarization: A revie w of recent research. Audio, Speec h, and Language Pr ocessing, IEEE T ransactions on , 20(2):356–370, 2012. K. Mo, S. Li, Y . Zhang, J. Li, and Q. Y ang. Personalizing a dialogue system with transfer learning. arXiv preprint arXiv:1610.02891 , 2016. S. Mohan and J. Laird. Learning goal-oriented hierarchical tasks from situated interactiv e instruction. In AAAI , 2014. 41 T . Nguyen, M. Rosenberg, X. Song, J. Gao, S. Tiw ary , R. Majumder , and L. Deng. Ms marco: A human generated machine reading comprehension dataset. arXiv pr eprint arXiv:1611.09268 , 2016. L. Nio, S. Sakti, G. Neubig, T . T oda, M. Adriani, and Sa. Nakamura. Developing non-goal dialog system based on examples of drama tele vision. In Natur al Inter action with Robots, Knowbots and Smartphones , pages 355–361. Springer , 2014a. L Nio, S. Sakti, G. Neubig, T . T oda, and S. Nakamura. Con versation dialog corpora from television and mo vie scripts. In 17th Oriental Chapter of the International Committee for the Co-ordination and Standar dization of Speec h Databases and Assessment T echniques (COCOSDA) , pages 1–4, 2014b. E. N ¨ oth, A. Horndasch, F . Gallwitz, and J. Haas. Experiences with commercial telephone-based dialogue systems. it– Information T echnology (vormals it+ ti) , 46(6/2004):315–321, 2004. C. Oertel, F . Cummins, J. Edlund, P . W agner , and N. Campbell. D64: A corpus of richly recorded con versational interaction. Journal on Multimodal User Interfaces , 7(1-2):19–28, 2013. A. H. Oh and A. I. Rudnicky . Stochastic language generation for spoken dialogue systems. In Confer ence of the North American Chapter of the Association for Computational Linguistics (NAA CL 2000), W orkshop on Con versational Systems , volume 3, pages 27–32. Association for Computational Linguistics, 2000. T . Paek. Reinforcement learning for spoken dialogue systems: Comparing strengths and weaknesses for practical deploy- ment. In Pr oc. Dialog-on-Dialog W orkshop, INTERSPEECH , 2006. K. Papineni, S. Roukos, T W ard, and W Zhu. BLEU: a method for automatic ev aluation of machine translation. In Pr oceedings of the 40th annual meeting on Association for Computational Linguistics (ACL) , 2002. A. N. Pargellis, H-K. J. Kuo, and C. Lee. An automatic dialogue generation platform for personalized dialogue applica- tions. Speech Communication , 42(3-4):329–351, 2004. doi: 10.1016/j.specom.2003.10.003. R. Passonneau and E. Sachar . Loqui human-human dialogue corpus (transcriptions and annotations), 2014. D. Perez-Marin and I. Pascual-Nieto. Con versational Agents and Natural Language Interaction: T echniques and Ef fective Practices . IGI Global, 2011. S. Petrik. W izard of Oz Experiments on Speec h Dialogue Systems . PhD thesis, T echnischen Uni versitat Graz, 2004. R. Pieraccini, D. Suendermann, K. Dayanidhi, and J. Liscombe. Are we there yet? research in commercial spok en dialog systems. In T e xt, Speech and Dialogue , pages 3–13, 2009. O. Pietquin. A framework for unsupervised learning of dialogue strate gies . Presses Universit ´ e Catholique de Louvain, 2004. O. Pietquin. A probabilistic description of man-machine spoken communication. In Multimedia and Expo, 2005. ICME 2005. IEEE International Confer ence on , pages 410–413, 2005. O. Pietquin. Learning to ground in spok en dialogue systems. In Acoustics, Speec h and Signal Pr ocessing, 2007. ICASSP 2007. IEEE International Confer ence on , volume 4, pages IV –165, 2007. O Pietquin and T . Dutoit. A probabilistic framew ork for dialog simulation and optimal strategy learning. IEEE T ransac- tions on Audio, Speec h, and Language Pr ocessing , 14(2):589–599, 2006. O. Pietquin and H. Hastie. A surv ey on metrics for the ev aluation of user simulations. The knowledge engineering r eview , 28(01):59–73, 2013. B. Piot, M. Geist, and O. Pietquin. Imitation learning applied to embodied conv ersational agents. In 4th W orkshop on Machine Learning for Inter active Systems (MLIS 2015) , volume 43, 2015. S. Png and J. Pineau. Bayesian reinforcement learning for pomdp-based dialogue systems. In IEEE International Con- fer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , pages 2156–2159, 2011. C. Potts. Goal-driv en answers in the cards dialogue corpus. In Pr oceedings of the 30th west coast conference on formal linguistics , pages 1–20, 2012. A. Ratnaparkhi. T rainable approaches to surface natural language generation and their application to con versational dialog systems. Computer Speech & Languag e , 16(3):435–455, 2002. A. Raux, B. Langner , D. Bohus, A. W . Black, and M. Eskenazi. Lets go public! taking a spoken dialog system to the real world. In Pr oceedings of INTERSPEECH . Citeseer, 2005. N. Reithinger and M. Klesen. Dialogue act classification using language models. In Eur oSpeech , 1997. H. Ren, W . Xu, Y . Zhang, and Y . Y an. Dialog state tracking using conditional random fields. In Special Inter est Group on Discourse and Dialogue (SIGDIAL) , 2013. S. Renals, T . Hain, and H. Bourlard. Recognition and understanding of meetings the AMI and AMID A projects. In IEEE W orkshop on Automatic Speech Recognition & Under standing (ASR U) , 2007. R. Reppen and N. Ide. The american national corpus overall goals and the first release. Journal of English Linguistics , 32(2):105–113, 2004. 42 J. Rickel and W . L. Johnson. Animated agents for procedural training in virtual reality: Perception, cognition, and motor control. Applied artificial intelligence , 13(4-5):343–382, 1999. V . Rieser and O. Lemon. Natural language generation as planning under uncertainty for spoken dialogue systems. In Empirical methods in natural languag e gener ation , pages 105–120. Springer , 2010. A. Ritter, C. Cherry , and B. Dolan. Unsupervised modeling of twitter conv ersations. In North American Chapter of the Association for Computational Linguistics (NAA CL 2010) , 2010. A. Ritter , C. Cherry , and W . B. Dolan. Data-driv en response generation in social media. In Pr oceedings of the conference on Empirical Methods in Natural Languag e Pr ocessing , 2011. S. Rosenthal and K. McKeo wn. I couldnt agree more: The role of con versational structure in agreement and disagreement detection in online discussions. In Special Inter est Gr oup on Discourse and Dialogue (SIGDIAL) , page 168, 2015. S. Rosset and S. Petel. The ritel corpus-an annotated human-machine open-domain question answering spoken dialog corpus. In The International Confer ence on Language Resour ces and Evaluation (LREC) , 2006. S. Rossignol, O. Pietquin, and M. Ianotto. T raining a bn-based user model for dialogue simulation with missing data. In Pr oceedings of the International Joint Confer ence on Natural Langua ge Pr ocessing , pages 598–604, 2011. A. Roy , C. Guinaudeau, H. Bredin, and C. Barras. TVD: a reproducible and multiply aligned tv series dataset. In The International Confer ence on Language Resour ces and Evaluation (LREC) , volume 2, 2014. J. Ruppenhofer, M. Ellsworth, M. R.L. Petruck, C. R. Johnson, and J. Scheffczyk. F rameNet II: Extended Theory and Practice . International Computer Science Institute, 2006. Distrib uted with the FrameNet data. J. Schatzmann and S. Y oung. The hidden agenda user simulation model. IEEE transactions on audio, speech, and language pr ocessing , 17(4):733–747, 2009. J. Schatzmann, K. Georgila, and S. Y oung. Quantitative ev aluation of user simulation techniques for spoken dialogue systems. In Special Inter est Gr oup on Discourse and Dialogue (SIGDIAL) , 2005. J. Schatzmann, K. W eilhammer , M. Stuttle, and S. Y oung. A survey of statistical user simulation techniques for reinforcement-learning of dialogue management strategies. The Knowledge Engineering Review , 21(02):97–126, 2006. J. Schatzmann, B. Thomson, K. W eilhammer , . Y e, and S. Y oung. Agenda-based user simulation for bootstrapping a pomdp dialogue system. In Human Language T echnologies 2007: The Conference of the North American Chapter of the Association for Computational Linguistics; Companion V olume, Short P apers , pages 149–152, 2007. J. N. Schrading. Analyzing domestic ab use using natural language processing on social media data. Master’ s thesis, Rochester Institute of T echnology , 2015. http://scholarworks.rit.edu/theses . N. Schrading, C. O. Alm, R. Ptucha, and C. M. Homan. An analysis of domestic a.se discourse on reddit. In Empirical Methods in Natural Languag e Pr ocessing (EMNLP) , 2015. K. K. Schuler . V erbNet: A broad-co vera ge, comprehensive verb lexicon . PhD thesis, Uni versity of Pennsylvania, 2005. Paper AAI3179808. I. V . Serban. Maximum likelihood learning and inference in conditional random fields. Bachelor’ s thesis, Univ ersity of Copenhagen, Denmark, 2012. http://www.blueanalysis.com/thesis/thesis.pdf . I. V . Serban and J. Pineau. T ext-based speaker identification for multi-participant open-domain dialogue systems. Neural Information Pr ocessing Systems W orkshop on Machine Learning for Spoken Langua ge Understanding , 2015. I. V . Serban, A. Sordoni, Y . Bengio, A. Courville, and J. Pineau. Building End-T o-End Dialogue Systems Using Genera- tiv e Hierarchical Neural Networks. In AAAI , 2016. In press. I. V . Serban, T . Klinger, G. T esauro, K. T alamadupula, B. Zhou, Y . Bengio, and A. Courville. Multiresolution recurrent neural networks: An application to dialogue response generation. In AAAI Conference , 2017a. I. V . Serban, A. Sordoni, R. Lowe, L. Charlin, J. Pineau, A. Courville, and Y . Bengio. A hierarchical latent v ariable encoder-decoder model for generating dialogues. In AAAI Conference , 2017b. S. Shaikh, T . Strzalko wski, G. A. Broadwell, J. Stromer-Galley , S. M. T aylor , and N. W ebb . Mpc: A multi-party chat corpus for modeling social phenomena in discourse. In The International Confer ence on Language Resources and Evaluation (LREC) , 2010. L. Shang, Z. Lu, and H. Li. Neural responding machine for short-text con versation. arXiv preprint , 2015. C. Shaoul and C. W estb ury . A usenet corpus (2005-2009), 2009. S. Sharma, J. He, K. Suleman, H. Schulz, and P . Bachman. Natural language generation in dialogue using lexicalized and delexicalized data. arXiv pr eprint arXiv:1606.03632 , 2016. B. A. Shawar and E. Atwell. Different measurements metrics to ev aluate a chatbot system. In Pr oceedings of the W orkshop on Bridging the Gap: Academic and Industrial Researc h in Dialog T echnologies , pages 89–96, 2007a. B. A. Shawar and Eric Atwell. Chatbots: are they really useful? In LD V F orum , volume 22, pages 29–49, 2007b. 43 E. Shriberg, R. Dhillon, S. Bhagat, J. Ang, and H. Carve y . The ICSI meeting recorder dialog act (mrda) corpus. T echnical report, DTIC Document, 2004. A. Simpson and N. M Eraser . Black box and glass box ev aluation of the sundial system. In Third Eur opean Confer ence on Speech Communication and T echnology , 1993. S. Singh, D. Litman, M. K earns, and M. W alker . Optimizing dialogue management with reinforcement learning: Experi- ments with the njfun system. Journal of Artificial Intellig ence Resear ch , pages 105–133, 2002. S. P . Singh, M. J. K earns, D. J. Litman, and M. A. W alker . Reinforcement learning for spoken dialogue systems. In Neural Information Pr ocessing Systems , 1999. A. Sordoni, Y . Bengio, H. V ahabi, C. Lioma, J. G. Simonsen, and J. Nie. A hierarchical recurrent encoder-decoder for generativ e context-aw are query suggestion. In Pr oceedings of the 24th ACM International Confer ence on Information and Knowledge Manag ement (CIKM 2015) , 2015a. A. Sordoni, M. Galle y , M. Auli, C. Brockett, Y . Ji, M. Mitchell, J. Nie, J. Gao, and B. Dolan. A neural network approach to context-sensitiv e generation of conv ersational responses. In Conference of the North American Chapter of the Association for Computational Linguistics (NAA CL-HLT 2015) , 2015b. A. Stenstr ¨ om, G. Andersen, and I. K. Hasund. T r ends in teenage talk: Corpus compilation, analysis and findings , volume 8. J. Benjamins, 2002. A. Stent, R. Prasad, and M. W alker . T rainable sentence planning for complex information presentation in spoken dialog systems. In Proceedings of the 42nd annual meeting on association for computational linguistics , page 79. Association for Computational Linguistics, 2004. A. Stolcke, K. Ries, N. Coccaro, E. Shriberg, R. Bates, D. Jurafsky , P . T aylor , R. Martin, C. V an Ess-Dykema, and M. Meteer . Dialogue act modeling for automatic tagging and recognition of conv ersational speech. Computational linguistics , 26(3):339–373, 2000. P .-H. Su, Y .-B. W ang, T .-H. Y u, and L.-S. Lee. A dialogue game framework with personalized training using reinforce- ment learning for computer-assisted language learning. In 2013 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing , pages 8213–8217. IEEE, 2013. P .-H. Su, D. V andyke, M. Gasic, D. Kim, N. Mrksic, T .-H. W en, and S. Y oung. Learning from real users: Rating dialogue success with neural networks for reinforcement learning in spoken dialogue systems. In INTERSPEECH , 2015. P .-H. Su, M. Gasic, N. Mrksic, L. Rojas-Barahona, S. Ultes, D. V andyke, T .-H. W en, and S. Y oung. Continuously learning neural dialogue management. arXiv pr eprint arXiv:1606.02689 , 2016. S. Sukhbaatar , A. Szlam, J. W eston, and R. Fergus. End-to-end memory networks. In Neural Information Pr ocessing Systems (NIPS) , 2015. X. Sun, J. Lichtenauer, M. V alstar , A. Nijholt, and M. Pantic. A multimodal database for mimicry analysis. In Affective Computing and Intelligent Interaction , pages 367–376. Springer , 2011. J. Svartvik. The London-Lund corpus of spoken English: Description and resear ch . Number 82 in 1. Lund University Press, 1990. B. Thomson and S. Y oung. Bayesian update of dialogue state: A POMDP framework for spoken dialogue systems. Computer Speech & Languag e , 24(4):562–588, 2010. J. T iedemann. Parallel data, tools and interfaces in opus. In The International Confer ence on Language Resources and Evaluation (LREC) , 2012. S. E. Tranter , D. Reynolds, et al. An overvie w of automatic speaker diarization systems. A udio, Speech, and Language Pr ocessing, IEEE T ransactions on , 14(5):1557–1565, 2006. D. T raum and J. Rickel. Embodied agents for multi-party dialogue in immersi ve virtual w orlds. In Pr oceedings of the first international joint confer ence on Autonomous a gents and multiag ent systems: part 2 , pages 766–773. ACM, 2002. A. M. T uring. Computing machinery and intelligence. Mind , pages 433–460, 1950. D. C Uthus and D. W Aha. The ubuntu chat corpus for multiparticipant chat analysis. In AAAI Spring Symposium: Analyzing Micr otext , 2013. J. V andev enter , A. J. Aubrey , P . L. Rosin, and D. Marshall. 4d cardif f conv ersation database (4D CCDb): A 4D database of natural, dyadic con versations. In Proceedings of the 1st Joint Conference on F acial Analysis, Animation and Auditory-V isual Speech Pr ocessing (F AA VSP 2015) , 2015. D. V andyke, P .-H. Su, M. Gasic, N. Mrksic, T .-H. W en, and S. Y oung. Multi-domain dialogue success classifiers for policy training. In Automatic Speech Recognition and Understanding (ASRU), 2015 IEEE W orkshop on , pages 763– 770. IEEE, 2015. O. V inyals and Q. Le. A neural con versational model. arXiv pr eprint arXiv:1506.05869 , 2015. 44 M. A. W alker , D. J. Litman, C. A. Kamm, and A. Abella. Paradise: A framew ork for ev aluating spoken dialogue agents. In Pr oceedings of the eighth confer ence on Eur opean chapter of the Association for Computational Linguistics , pages 271–280, 1997. M. A. W alker , O. C. Rambo w , and M. Rogati. Training a sentence planner for spok en dialogue using boosting. Computer Speech & Languag e , 16(3):409–433, 2002. M. A. W alker , R. Grant, J. Sa wyer , G. I. Lin, N. W ardrip-Fruin, and M. Buell. Perceived or not perceiv ed: Film character models for expressi ve nlg. In ICIDS , pages 109–121, 2011. M. A W alker , G. I. Lin, and J. Sawyer . An annotated corpus of film dialogue for learning and characterizing character style. In The International Confer ence on Language Resour ces and Evaluation (LREC) , pages 1373–1378, 2012a. M. A W alker , J. E. F . T ree, P . Anand, R. Abbott, and J. King. A corpus for research on deliberation and debate. In The International Confer ence on Language Resour ces and Evaluation (LREC) , pages 812–817, 2012b. Z. W ang and O. Lemon. A simple and generic belief tracking mechanism for the dialog state tracking challenge: On the believ ability of observed information. In Special Inter est Gr oup on Discourse and Dialogue (SIGDIAL) , 2013. S. W ebb . A corpus dri ven study of the potential for v ocabulary learning through watching mo vies. International J ournal of Corpus Linguistics , 15(4):497–519, 2010. J. W eizenbaum. ELIZAa computer program for the study of natural language communication between man and machine. Communications of the A CM , 9(1):36–45, 1966. T . W en, M. Ga ˇ sic, D. Kim, N. Mrk ˇ sic, P . Su, D. V andyke, and S. Y oung. Stochastic language generation in dialogue using recurrent neural networks with con volutional sentence reranking. Special Inter est Gr oup on Discourse and Dialogue (SIGDIAL) , 2015. T .-H. W en, M. Gasic, N. Mrksic, L. M. Rojas-Barahona, P .-H. Su, D. V andyke, and S. Y oung. Multi-domain neural network language generation for spoken dialogue systems. In Confer ence of the North American Chapter of the Association for Computational Linguistics (NAA CL-HLT 2016) , 2016. J. W eston. Dialog-based language learning. arXiv pr eprint arXiv:1604.06045 , 2016. J. W eston, S. Chopra, and A. Bordes. Memory networks. In International Confer ence on Learning Representations (ICLR) , 2015. J. W illiams, A. Raux, D. Ramachandran, and A. Black. The dialog state tracking challenge. In Special Inter est Gr oup on Discourse and Dialogue (SIGDIAL) , 2013. J. D. W illiams and S. Y oung. Partially observable markov decision processes for spoken dialog systems. Computer Speech & Languag e , 21(2):393–422, 2007. J. D. Williams and G. Zweig. End-to-end lstm-based dialog control optimized with supervised and reinforcement learning. arXiv pr eprint arXiv:1606.01269 , 2016. M. W olska, Q. B. V o, D. Tsov altzi, I. Kruijf f-Korbayov ´ a, E. Karagjosova, H. Horacek, A. Fiedler, and C. Benzm ¨ uller . An annotated corpus of tutorial dialogs on mathematical theorem proving. In The International Confer ence on Language Resour ces and Evaluation (LREC) , 2004. B. Wrede and E. Shriberg. Relationship between dialogue acts and hot spots in meetings. In A utomatic Speech Recogni- tion and Understanding, 2003. ASR U’03. 2003 IEEE W orkshop on , pages 180–185. IEEE, 2003. Y i Y ang, W en-tau Y ih, and Christopher Meek. W ikiqa: A challenge dataset for open-domain question answering. In EMNLP , pages 2013–2018. Citeseer , 2015. Z. Y ang, B. Li, Y . Zhu, I. King, G. Levo w , and H. Meng. Collection of user judgments on spoken dialog system with crowdsourcing. In Spoken Language T echnology W orkshop (SLT), 2010 IEEE , pages 277–282, 2010. S. Y oung, M. Gasic, B. Thomson, and J. D. W illiams. POMDP-based statistical spok en dialog systems: A revie w . Pr oceedings of the IEEE , 101(5):1160–1179, 2013. S. J. Y oung. Probabilistic methods in spoken–dialogue systems. Philosophical T ransactions of the Royal Society of London. Series A: Mathematical, Physical and Engineering Sciences , 358(1769), 2000. J. Zhang, R. Kumar , S. Ravi, and C. Danescu-Niculescu-Mizil. Con versational flo w in oxford-style debates. In Confer- ence of the North American Chapter of the Association for Computational Linguistics (NAA CL-HLT 2016) , 2016. 45 A ppendix A. Learning fr om Dialogue Corpora In this appendix section, we revie w some existing computational architectures suitable for learning dialogue strategies directly from data. The goal is not to provide full technical details on the methods av ailable to achieve this — though we provide appropriate citations for the interested reader — but rather to illustrate concretely how the datasets described abov e can, and hav e, been used in different dialogue learning ef forts. As such, we limit this revie w to a small set of existing work. A.1 Data Pre-pr ocessing Before applying machine learning methods to a dialogue corpus, it is common practice to perform some form of pre-processing. The aim of pre-processing is to standardize a dataset with minimal loss of information. This can reduce data scarcity , and eventually make it easier for models to learn from the dataset. In natural language processing, it is commonly ackno wledged that pre-processing can hav e a significant ef fect on the results of the natural language processing system—the same observ ation holds for dialogue. Although the specific procedure for pre-processing is task- and data-dependent, in this section we highlight a fe w common approaches, in order to giv e a general idea of where pre-processing can be ef fecti ve for dialogue systems. Pre-processing is often used to remove anomalies in the data. For text-based corpora, this can include remo ving acronyms, slang, misspellings and phonemicization (e.g. where words are written according to their pronunciation instead of their correct spelling). For some models, such as the generati ve dialogue models discussed later, tokenization (e.g. defining the smallest unit of input) is also critical. In datasets collected from mobile te xt, forum, microblog and chat-based settings, it is common to observe a significant number of acronyms, abbre viations, and phonemicizations that are specific to the topic and userbase ( Clark , 2003 ). Although there is no widely accepted standard for handling such occurrences, many NLP systems incorporate some form of pre-processing to normalize these entries ( Kaufmann and Kalita , 2010 ; A w et al. , 2006 ; Clark , 2003 ). For example, there are look-up tables, such as the IRC Beginner List 18 , which can be used to translate the most common acronyms and slang into standard English. Another common strategy is to use stemming and lemmatization to replace man y w ords with a single item (e.g. walking and walker both replaced by walk ). Of course, depending on the task at hand and the corpus size, an option is also to leav e the acronyms and phonemicized w ords as they are. In our e xperience, almost all dialogue datasets contain some amount of spelling errors. By correcting these, we expect to reduce data sparsity . This can be done by using automatic spelling correctors. Howe ver , it is important to inspect their ef fectiveness. F or e xample, for movie scripts, Serban et al. ( 2016 ) found that automatic spelling correctors introduced more spelling errors than they corrected, and a better strategy was to use W ikipedia’ s most commonly misspelled w ords 19 to lookup and replace potential spelling errors. Transcribed spoken language corpora often include many non-words in their transcriptions (e.g. uh, oh). Depending on whether or not these provide additional information to the dialogue system, researchers may also w ant to remo ve these words by using automatic spelling correctors. 18. http://www.ircbeginner.com/ircinfo/abbreviations.html 19. https://en.wikipedia.org/wiki/Commonly_misspelled_English_words 46 A.2 Segmenting Speakers and Con versations Some dialogue corpora, such as those based on movie subtitles, come without explicit speaker segmentation. Ho we ver , it is often possible to estimate the speaker segmentation, which is useful to build a model of a giv en speaker —as compared to a model of the con versation as a whole. For text-based corpora, Serban and Pineau ( 2015 ) have recently proposed the use of recurrent neural networks to estimate turn-taking and speaker labels in mo vie scripts with promising results. In the speech recognition literature, this is the subtask of speaker diarisation ( Miro et al. , 2012 ; T ranter et al. , 2006 ). When the audio stream of the speech is a v ailable, the segmentation is quite accurate with classification error rates as lo w as 5% . A strategy sometimes used for segmentation of spoken dialogues is based on labelling a small subset of the corpus, kno wn as the gold corpus, and training a specific segmentation model based on this. The remaining corpus is then se gmented iterativ ely according to the segmentation model, after which the gold corpus is expanded with the most confident segmentations and the segmentation model is retrained. This process is sometimes kno wn as embedded training, and is widely used in other speech recognition tasks ( Jurafsky and Martin , 2008 ). It appears to work well in practice, but has the disadvantage that the interpretation of the label can drift. Naturally , this approach can be applied to text dialogues as well in a straightforw ard manner . In certain corpora, such as those based on chat channels or extracted from mo vie subtitles, many con versations occur in sequence. In some cases, there are no labels partitioning the beginning and end of separate con versations. Similarly , certain corpora with multiple speakers, such as corpora based on chat channels, contain se veral conv ersations occurring in parallel (e.g. simultaneously) but do not contain an y se gmentation separating these con versations. This makes it hard to learn a meaningful model from such con versations, because they do not represent consistent speak ers or coherent semantic topics. T o le verage such data tow ards learning indi vidual con versations, researchers have proposed methods to automatically estimate segmentations of con versations ( Lo we et al. , 2015a ; Nio et al. , 2014a ). F ormer solutions were mostly based on hand-crafted rules and seemed to work well upon manual inspection. For chat forums, one solution in volves thresholding the be ginning and end of con versations based on time (e.g. delay of more than x minutes between utterances), and eliminat- ing speak ers from the con versation unless the y are referred to explicitly by other speakers ( Lo we et al. , 2015a ). More adv anced techniques in volve maximum-entropy classifiers, which lev erage the content of the utterances in addition to the discourse structure and timing information ( Elsner and Charniak , 2008 ). For movie scripts, researchers have proposed the use of simple information- retrie v al similarity measures, such as cosine similarity , to identify con versations ( Nio et al. , 2014a ). Based on the their performance on estimating turn-taking and speaker labels, recurrent neural net- works also hold promise for se gmenting con versations ( Serban and Pineau , 2015 ). A.3 Discriminative Model Ar chitectures As discussed in Subsection 2.3 , discriminative models aim to predict certain labels or annotations manually associated with a portion of a dialogue. For e xample, a discriminati ve model might be trained to predict the intent of a person in a dialogue, or the topic, or a specific piece of information. 47 In the following subsections, we discuss research directions where discriminati ve models hav e been de veloped to solve dialogue-related tasks. 20 This is primarily meant to revie w and contrast the work from a data-dri ven learning perspectiv e. A . 3 . 1 D I A L O G U E A C T C L A S S I FI C A T I O N A N D D I A L O G U E T O P I C S P O T T I N G Here we consider the simple task kno wn as dialogue act classification (or dialogue move recogni- tion). In this task, the goal is to classify a user utterance, independent of the rest of the con versation, as one out of K dialogue acts: P ( A | U ) , where A is the discrete variable representing the dialogue act and U is the user’ s utterance. This falls under the general umbrella of text classification tasks, though its application is specific to dialogue. Like the dialogue state track er model, a dialogue act classification model could be plugged into a dialogue system as an additional natural language understanding component. Early approaches for this task focused on using n -gram models for classification ( Reithinger and Klesen , 1997 ; Bird et al. , 1995 ). F or example, Reithinger et al. assumed that each dialogue act is generated by its own language model. The y trained an n -gram language model on the utterances of each dialogue act, P θ ( U | A ) , and afterwards use Bayes’ rule to assign the probability of a new dialogue act P θ ( A | U ) to be proportional to the probability of generating the utterance under the language model P θ ( U | A ) . Ho we ver , a major problem with this approach is the lack of datasets with annotated dialogue acts. More recent work by For gues et al. ( 2014 ) acknowledged this problem, and tried to ov ercome the data scarcity issue by leveraging word embeddings learned from other , lar ger text corpora. They created an utterance-lev el representation by combining the word embeddings of each word, for example, by summing the word embeddings or taking the maximum w .r .t. each dimension. These utterance-le vel representations, together with word counts, were then gi ven as inputs to a linear classifier to classify the dialogue acts. Thus, For gues et al. sho wed that by lev eraging another , substantially larger , corpus they were able to impro ve performance on their original task. This makes the work on dialogue act classification very appealing from a data-driven perspec- ti ve. First, it seems that the accuracy can be improved by le veraging alternativ e data sources. Sec- ond, unlike the dialogue state tracking models, dialogue act classification models typically in volv e relati vely little feature hand-crafting thus suggesting that data-driv en approaches may be more po w- erful for these tasks. A . 3 . 2 D I A L O G U E S T A T E T R A C K I N G The core task of the DSTC ( Williams et al. , 2013 ) adds more complexity by focusing on tracking the state of a con versation. This is framed as a classification problem: for e very time step t of the dialogue, the model is gi ven the current input to the dialogue state tracker (including ASR and SLU outputs) together with e xternal knowledge sources (e.g. b us timetables). The required output is a probability distribution over a set of N t predefined hypotheses, in addition to the REST hypothesis (which represents the probability that none of the pre vious N t hypotheses are correct). The goal is to match the distrib ution o ver hypotheses as closely as possible to the real annotated 20. It is important to note that although discriminativ e models have been fav ored to model supervised problems in the dialogue-system literature, in principle generati ve models ( P ( X , Y ) ) instead of discriminative models ( P ( Y | X ) ) could be used. 48 data. By providing an open dataset with accurate labels, it has been possible for researchers to perform rigourous comparati ve e valuations of dif ferent classification models for dialogue systems. Models for the DSTC include both statistical approaches and hand-crafted systems. An example of the latter is the system proposed in W ang and Lemon ( 2013 ), which relies on ha ving access to a marginal confidence score P t ( u, s, v ) for a user dialogue u ( s = v ) with slot s and value v giv en by a subsystem at time t . The marginal confidence score gi ves a heuristic estimate of the probability of a slot taking a particular value. The model must then aggre gate all these estimates and confidence scores to compute probabilities for each hypothesis. In this model, the SLU component may for example gi ve the marginal confidence score ( in- form(data.day=today)=0.9 ) in the bus scheduling DSTC, meaning that it belie ves with high confi- dence (0.9) that the user has requested information for the current day . This mar ginal confidence score is used to update the belief state of the system b t ( s, v ) at time t using a set of hand-crafted updates to the probability distribution o ver hypotheses. From a data-driv en l earning perspectiv e, this approach does not make ef ficient use of the dataset, but instead relies heavily on the accuracy of the hand-crafted tracker outputs. More sophisticated models for the DSTC take a dynamic Bayesian approach by modeling the latent dialogue state and observed tracker outputs in a directed graphical model ( Thomson and Y oung , 2010 ). These models are sometimes called generative state tracking models, though they are still discriminati ve in nature as the y only attempt to model the state of the dialogue and not the words and speech acts in each dialogue. For simplicity we drop the inde x i in the following equations. Similar to before, let x t be the observed tracker outputs at time t . Let s t be the dialogue state at time t , which represents the state of the world including, for example, the user actions (e.g. defined by slot-value pairs) and system actions (e.g. number of times a piece of information has been requested). For the DSTC, the state s t must represent the true current slot-v alue pair at time t . Let r t be the reward observed at time t , and let a t be the action taken by the dialogue system at time t . This general framework, also known as a partially-observable Markov decision process (POMDP) then defines the graphical model: P θ ( x t , s t , r t | a t , s t − 1 ) = P θ ( x t | s t , a t ) P θ ( s t | s t − 1 , a t ) P θ ( r t | s t , a t ) , (3) where a t is assumed to be a deterministic v ariable of the dialogue history . This v ariable is given in the DSTC, because it comes from the policy used to interact with the humans when g athering the datasets. This approach is attracti ve from a data-dri ven learning perspective, because it models the uncertainty (e.g. noise and ambiguity) inherent in all v ariables of interest. Thus, we might expect such a model to be more robust in real applications. No w , since all variables are observed in this task, and since the goal is to determine s t gi ven the other v ariables, we are only interested in: P θ ( s t | x t , r t , a t ) ∝ P θ ( x t | s t , a t ) P θ ( s t | s t − 1 , a t ) P θ ( r t | s t , a t ) , (4) which can then be normalized appropriately since s t is a discrete stochastic v ariable. Howe ver , due to the temporal dependency between s t and s t − 1 , the complexity of the model is similar to a hidden Marko v model, and thus both learning and inference become intractable when the state, observation and action spaces are too lar ge. Indeed, as noted by Y oung et al. ( 2013 ), the number of states, actions and observations can easily reach 10 10 configurations in some dialogue systems. Thus, it is necessary to make simplifying assumptions on the distribution P θ ( s t | x t , r t , a t ) and to approximate 49 the learning and inference procedures ( Y oung et al. , 2013 ). W ith appropriate structural assumptions and approximations, these models perform well compared to baseline systems on the DSTC ( Black et al. , 2011 ). Non-bayesian data-dri ven models have also been proposed. These models are sometimes called discriminati ve state tracking models, because they do not assume a generation process for the tracker outputs, x t or for any other variables, but instead only condition on them. For example, Henderson et al. ( 2013 ) proposed to use a feed-forward neural network. At each time step t , they extracted a set of features and then concatenate a window of W feature vectors together . These are giv en as input to the neural network, which outputs the probability of each hypothesis from the set of hypotheses. By learning a discriminative model and using a windo w ov er the last time steps, they do not face the intractability issues of dynamic Bayesian networks. Instead, their system can be trained with gradient descent methods. This approach could ev entually scale to large datasets, and is therefore very attractive for data-driven learning. Ho we ver , unlike the dynamic Bayesian approaches, these models do not represent probability distrib utions o ver variables apart from the state of the dialogue. Without probability distrib utions, it is not clear ho w to define a confidence interv al o ver the predictions. Thus the models might not provide adequate information to determine when to seek confirmation or clarification follo wing unclear statements. Researchers hav e also inv estigated the use of conditional random fields (CRFs) for state tracking ( Ren et al. , 2013 ). This class of models also falls under the umbrella of discriminati ve state tracking models; ho we ver , they are able to take into account temporal dependencies within dialogues by modeling a complete joint distribution o ver states: P θ ( S | X ) ∝ Y c ∈ C Y i f i ( s c , x c ) , (5) where C is the set of factors, i.e. sets of state and tracker v ariables across time, s c is the set of states associated with factor c , x c is the set of observations associated with factor c , and { f i } i is a set of functions parametrized by parameters θ . There exist certain functions f i , for which exact inference is tractable and learning the parameters θ is efficient ( K oller and Friedman , 2009 ; Serban , 2012 ). For example, Ren et al. ( 2013 ) propose a set of factors which create a linear dependency structure between the dialogue states while conditioning on all the observed track er outputs: P θ ( S | X ) ∝ Y t Y i f i ( s t − 1 , s t , s t + 1 , X ) . (6) This creates a dependenc y between all dialogue states, forcing them be coherent with each other . This should be contrasted to the feed-forward neural network approach, which does not enforce an y sort of consistency between different predicted dialogue states. The CFR models can be trained with gradient descent to optimize the exact log-likelihood, but exact inference is typically intractable. Therefore, an approximate inference procedure, such as loopy belief propagation, is necessary to approximate the posterior distribution o ver states s t . In summary , there exist different approaches to b uilding discriminativ e learning architectures for dialogue. While they are fairly straightforward to ev aluate and often form a crucial component for real-world dialogue systems, by themselves they only of fer a limited view of what we ultimately want to accomplish with dialogue models. They often require labeled data, which is often dif ficult to acquire on a large scale (e xcept in the case of answer re-ranking) and require manual feature selection, which reduces their potential ef fectiveness. Since each model is trained independently 50 of the other models and components with which it interacts in the complete dialogue system, one cannot gi ve guarantees on the performance of the final dialogue system by ev aluating the indi vidual models alone. Thus, we desire models that are capable of producing probability distributions o ver all possible responses instead of ov er all annotated labels—in other words, models that can actually gener ate new responses by selecting the highest probability next utterance. This is the subject of the next section. A.4 Response Generation Models Both the response re-ranking approach and the generati ve response model approach ha ve allo wed for the use of lar ge-scale unannotated dialogue corpora for training dialogue systems. W e therefore close this section by discussing these classes of approaches In general, approaches which aim to generate responses have the potential to learn semantically more powerful representations of dialogues compared to models trained for dialogue state tracking or dialogue act classification tasks: the concepts they are able to represent are limited only by the content of the dataset, unlike the dialogue state tracking or dialogue act classification models which are limited by the annotation scheme used (e.g. the set of possible slot-value pairs pre-specified for the DSTC). A . 4 . 1 R E - R A N K I N G R E S P O N S E M O D E L S Researchers ha ve recently turned their attention to the problem of b uilding models that produce answers by re-ranking a set of candidate answers, and outputting the one with the highest rank or probability . While the task may seem artificial, the main adv antage is that it allows the use of completely un-annotated datasets. Unlike dialogue state tracking, this task does not require datasets where experts have labeled ev ery utterance and system response. This task only requires kno wing the sequence of utterances, which can be extracted automatically from transcribed con versations. Banchs and Li ( 2012 ) construct an information retrie val system based on movie scripts using the vector space model. Their system searches through a database of mo vie scripts to find a dialogue similar to the current dialogue with the user , and then emits the response from the closest dialogue in the database. Similarly , Ameixa et al. ( 2014 ) also use an information retriev al system, but based on movie subtitles instead of movie scripts. The y show that their system gi ves sensible responses to questions, and that bootstrapping an existing dialogue system from movie subtitles improv es an- swering out-of-domain questions. Both approaches assume that the responses gi ven in the movie scripts and movie subtitle corpora are appropriate. Such information retriev al systems consist of a relati vely small set of manually tuned parameters. For this reason, they do not require (annotated) labels and can therefore tak e adv antage of ra w data (in this case mo vie scripts and mo vie subtitles). Ho we ver , these systems are effecti vely nearest-neighbor methods. They do not learn rich represen- tations from dialogues which can be used, for example, to generalize to pre viously unseen situations. Furthermore, it is unclear how to transform such models into full dialogue agents. They are not ro- bust and it is not clear how to maintain the dialogue state. Contrary to search engines, which present an entire page of results, the dialogue system is only allo wed to gi ve a single response to the user . ( Lo we et al. , 2015a ) also propose a re-ranking approach using the Ubuntu Dialogue Corpus. The authors propose an affinity model between a context c (e.g. five consecutiv e utterances in a con versation) and a potential reply r . Given a conte xt-reply pair the model compares the output of a conte xt-specific LSTM against that of a response-specific LSTM neural network and outputs 51 whether or not the response is correct for the gi ven conte xt. The model maximizes the lik elihood of a correct context-response pair: max θ X i P θ ( true response | c i , r i ) I c i ( r i ) (1 − P θ ( true response | c i , r i )) 1 − I c i ( r i ) (7) where θ stands for the set of all model parameters and I c i ( · ) denotes a function that returns 1 when r i is the correct response to c i and 0 otherwise. Learning in the model uses stochastic gradient descent. As is typical with neural netw ork architectures, this learning procedure scales to large datasets. Giv en a context, the trained model can be used to pick an appropriate answer from a set of potential answers. This model assumes that the responses given in the corpus are appropriate (i.e., this model does not generate novel responses). Howe ver , unlike the abov e information retrie v al systems, this model is not provided with a similarity metric as in the v ector space model, b ut instead must learn the semantic relev ance of a response to a context. This approach is more attracti ve from a data-driv en learning perspectiv e because it uses the dataset more efficiently and av oids costly hand tuning of parameters. A . 4 . 2 F U L L G E N E R A T I V E R E S P O N S E M O D E L S Generati ve dialogue response strategies are designed to automatically produce utterances by com- posing text (see Section 2.4 ). A straightforward way to define the set of dialogue system actions is by considering them as sequences of words which form utterances. Sordoni et al. ( 2015b ) and Ser- ban et al. ( 2016 ) both use this approach. They assume that both the user and the system utterances can be represented by the same generati ve distrib ution: P θ ( u 1 , . . . , u T ) = T Y t =1 P θ ( u t | u
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment