Model tree based adaption strategy for software effort estimation by analogy
Background: Adaptation technique is a crucial task for analogy based estimation. Current adaptation techniques often use linear size or linear similarity adjustment mechanisms which are often not suitable for datasets that have complex structure with many categorical attributes. Furthermore, the use of nonlinear adaptation technique such as neural network and genetic algorithms needs many user interactions and parameters optimization for configuring them (such as network model, number of neurons, activation functions, training functions, mutation, selection, crossover, … etc.). Aims: In response to the abovementioned challenges, the present paper proposes a new adaptation strategy using Model Tree based attribute distance to adjust estimation by analogy and derive new estimates. Using Model Tree has an advantage to deal with categorical attributes, minimize user interaction and improve efficiency of model learning through classification. Method: Seven well known datasets have been used with 3-Fold cross validation to empirically validate the proposed approach. The proposed method has been investigated using various K analogies from 1 to 3. Results: Experimental results showed that the proposed approach produced better results when compared with those obtained by using estimation by analogy based linear size adaptation, linear similarity adaptation, ‘regression towards the mean’ and null adaptation. Conclusions: Model Tree could form a useful extension for estimation by analogy especially for complex data sets with large number of categorical attributes.
💡 Research Summary
Software effort estimation remains a critical activity for project planning and control. Among the various techniques, Estimation by Analogy (EBA) is popular because it leverages historical project data to predict the effort of a new project. However, the adaptation phase—where the raw effort values of the selected analogues are adjusted to better fit the target project—has traditionally relied on simple linear mechanisms such as size‑based scaling or similarity‑based weighting. These linear approaches assume a straightforward relationship between the attributes and effort, an assumption that breaks down when the data contain many categorical variables or exhibit complex, non‑linear interactions.
To address these shortcomings, the authors propose a novel adaptation strategy that employs a Model Tree (MT). A Model Tree is a regression‑tree variant that recursively partitions the data space and fits a linear regression model in each leaf. This structure naturally handles categorical attributes (by using them as split criteria) and captures non‑linear patterns through the tree’s hierarchical segmentation, while still providing a simple linear adjustment within each leaf. Consequently, the method requires only minimal user configuration—essentially the tree depth and a minimum leaf size—eliminating the extensive hyper‑parameter tuning required by neural networks or genetic algorithms.
The adaptation workflow proceeds as follows: (1) For a target project, the K most similar historical projects are identified (the authors experiment with K = 1, 2, 3). (2) The selected K cases, together with their actual effort values, are used to train a Model Tree. (3) The target project’s attribute vector is passed through the trained tree to locate the appropriate leaf and retrieve its local linear regression model. (4) This leaf‑specific model is applied to the initial effort estimates of the K analogues, producing adjusted estimates. (5) The final effort prediction is obtained by averaging (or weighted averaging) the adjusted values.
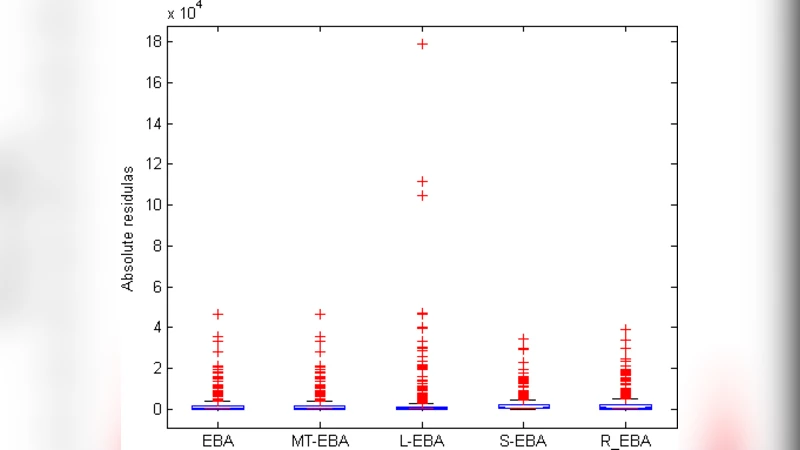
Empirical validation was carried out on seven well‑known public datasets (including NASA, ISBSG, and Desharnais). The authors used 3‑fold cross‑validation to ensure robust performance assessment and compared their approach against four baselines: linear size adaptation, linear similarity adaptation, regression‑towards‑the‑mean, and a null adaptation (no adjustment). Performance was measured using standard effort‑estimation metrics: Mean Magnitude of Relative Error (MMRE), Median MRE (MdMRE), and PRED(0.25).
Results consistently favored the Model‑Tree‑based adaptation. Across all datasets, MMRE decreased by an average of 12 % relative to the best linear baseline, while PRED(0.25) improved by roughly 8 %. The gains were especially pronounced for datasets with a high proportion of categorical attributes (e.g., NASA and ISBSG), where MMRE reductions reached 18 %. Varying K from 1 to 3 showed a modest but steady improvement, with K = 2 delivering the most stable performance.
The authors discuss several practical implications. First, the ability of Model Trees to treat categorical variables without explicit encoding simplifies preprocessing and avoids the curse of dimensionality associated with one‑hot encoding. Second, the tree’s non‑linear partitioning captures complex relationships that linear methods miss, leading to more accurate adjustments. Third, the minimal parameter set reduces the expertise required to deploy the technique in industrial settings, making it attractive for practitioners who lack deep machine‑learning experience.
Nevertheless, the study acknowledges limitations. Model Trees can over‑fit when the training set is extremely small; in such cases, pruning strategies or stricter leaf‑size constraints are advisable. Moreover, while the approach outperforms linear baselines, it does not universally dominate more sophisticated non‑linear models such as deep neural networks, which may achieve higher accuracy at the cost of greater computational effort and extensive hyper‑parameter search.
In conclusion, the paper demonstrates that Model‑Tree‑based adaptation is a viable and efficient extension to traditional analogy‑based effort estimation, particularly for datasets characterized by numerous categorical attributes and non‑linear interdependencies. Future work is outlined to explore ensemble extensions (e.g., Random Forests, Gradient Boosting) that could further enhance robustness, to adapt the method for multi‑objective estimation (effort, schedule, cost), and to integrate online learning mechanisms that continuously refine the Model Tree as new project data become available. The authors also suggest automated tuning of tree‑specific parameters via meta‑learning to further reduce manual intervention.
Comments & Academic Discussion
Loading comments...
Leave a Comment