Tying Word Vectors and Word Classifiers: A Loss Framework for Language Modeling
Recurrent neural networks have been very successful at predicting sequences of words in tasks such as language modeling. However, all such models are based on the conventional classification framework, where the model is trained against one-hot targe…
Authors: Hakan Inan, Khashayar Khosravi, Richard Socher
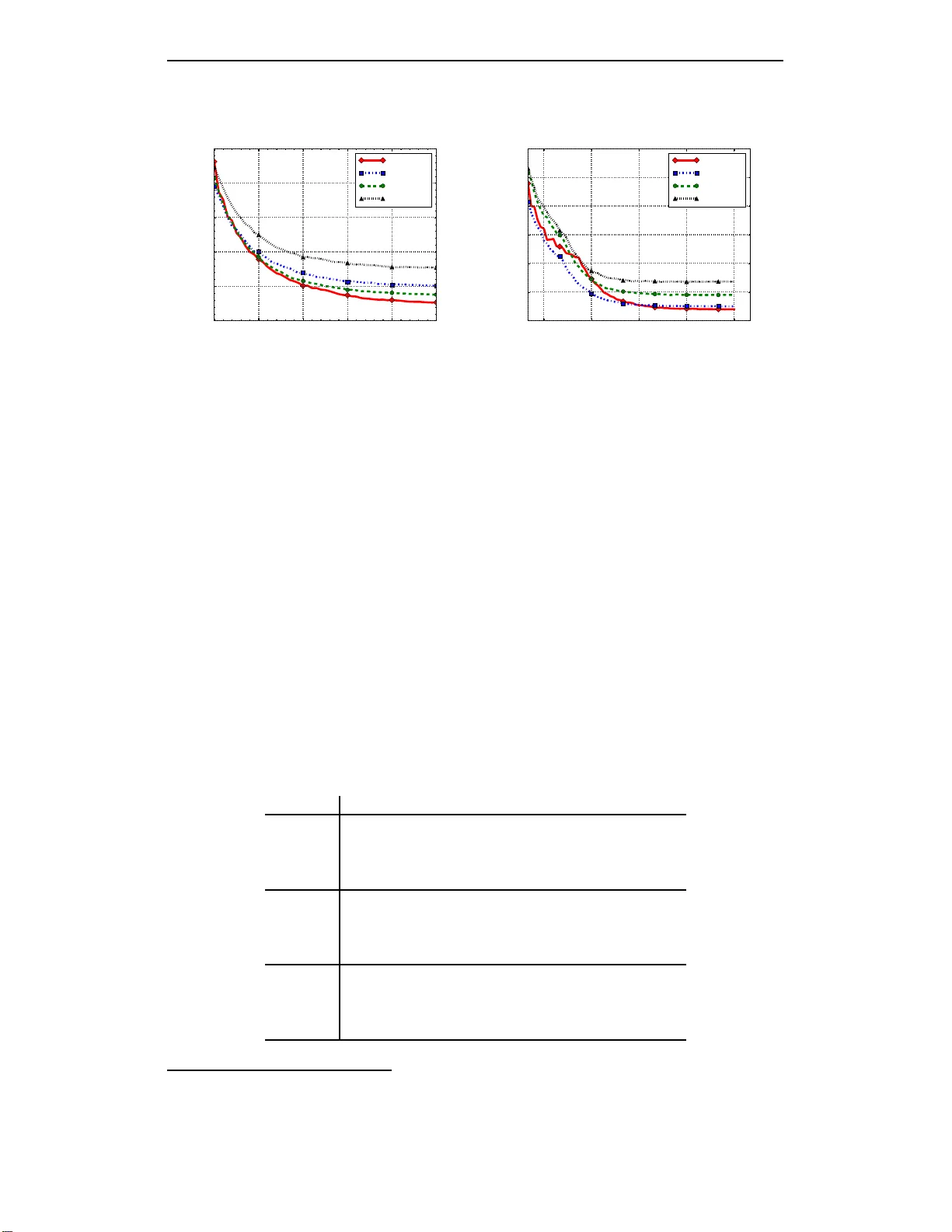
Published as a con f erence paper at ICLR 2017 T Y I N G W O R D V E C T O R S A N D W O R D C L A S S I FI E R S : A L O S S F R A M E W O R K F O R L A N G U AG E M O D E L I N G Hakan Inan, Khashay ar Khosra vi Stanford Univ ersity Stanford, CA, USA { inanh,kho sravi } @stan ford.edu Richard Socher Salesforce Research Palo Alto, CA, USA rsocher@sale sforce.com A B S T R A C T Recurrent neural networks have been very successfu l at pred ic tin g sequences o f words in tasks suc h as lang u age modelin g. Howe ver , all such m odels are based on the con ventional classification fram ew ork, where the model is trained against one-ho t targets, and each word is r epresented both as an in put and as an o utput in isolatio n. This cau ses in efficiencies in learnin g both in ter m s of utilizing all of the inf o rmation and in ter ms of the number o f p arameters n e e ded to train. W e introdu c e a novel theoretical fram ework that facilitates better learning in language modeling , and show that our fra mew ork lead s to tying togeth er th e inp ut e mbed- ding an d the output pr ojection matrices, greatly reducin g the n umber of trainable variables. Ou r f ramework leads to state of the art performance on the Penn T ree- bank with a variety of network models. 1 I N T R O D U C T I O N Neural ne twork models have recently made trem endou s progr ess in a variety of NLP application s such as spee c h r e cognition ( Irie et al. , 2016 ), sen timent analysis ( Soch er et al. , 2013 ), text summa- rization ( Rush et al. , 2015 ; Nallapati et al. , 2 016 ), and machine translation ( Firat et al. , 2 016 ). Despite the overwhelming success achieved by recu r rent neural networks in mod eling long range de- penden cies between words, current recurrent neural network langu age models (RNNLM) are based on the conventional classification framework, wh ich has two major drawbacks: First, there is no as- sumed m e tric o n the outp ut classes, whereas there is evidence sugge stin g th at lear n ing is improved when one can define a natural metric on the output space ( Frogner et al. , 2 015 ). In langu age model- ing, there is a well established m etric space f or the ou tputs ( words in the language) b a sed on word embedd in gs, with meaningfu l distances between words ( Mikolov e t al. , 2013 ; Penn ington et al. , 2014 ). Second , in the classical framework, inp uts and outpu ts are con sid ered as isolated entities with no seman tic lin k b etween th em. This is clearly not th e case for lang uage mo deling, whe re inputs an d ou tp uts in fact live in identical spaces. Ther efore, even fo r models with m oderately sized vocab ularies, the classical fr amew ork could be a vas t sou r ce of ineffi ciency in terms of the number of variables in the mo del, an d in terms of utilizin g the info rmation gathered by d ifferent pa r ts of th e model (e.g. in puts and o utputs). In this work, we introduce a nov el lo ss framew o rk for la n guage mo deling to r e medy th e above two problem s. Our fr amew ork is comprised of two closely linked imp rovements. First, we a u gment the classical cross-en tropy loss with an additio n al term which minimize s th e KL-divergence between the mod el’ s p rediction and an estimated target distribution b ased on the word embedd in gs space. This estimated distribution uses k nowledge of word vector similarity . W e th en theo retically analyze this loss, and this leads to a seco nd and sy n ergistic imp rovement: tying tog ether two large matrices by reusing the inpu t word embed d ing matr ix as the o utput classification matrix. W e empirically validate our theo ry in a p ractical setting, with much m ilder assump tio ns than those in theor y . W e also find empir ically that f o r large networks, m ost of the improvement could be achieved b y only reusing the word embedd ings. W e test ou r framework by perfo rming extensiv e experim e nts on the Penn Treebank corpus, a dataset widely u sed for b enchmar king languag e m odels ( Mikolov et al. , 2 0 10 ; Merity et al. , 201 6 ). W e demonstra te that mod els tr a ined u sing our pr oposed fr amew ork significan tly outperf orm models 1 Published as a con f erence pap er at ICLR 201 7 trained u sing the conv entional framew o rk. W e also perf orm experiments on the newly introdu ced W ikitext-2 dataset ( Merity et al. , 20 16 ), and verify that the em pirical performance of our proposed framework is c o nsistent across different datasets. 2 B AC K G RO U N D : R E C U R R E N T N E U R A L N E T W O R K L A N G U AG E M O D E L In any variant of r ecurrent n eural network lang uage model (RNNLM), the g oal is to pr edict the next word indexed by t in a sequen c e of one - hot word tokens ( y ∗ 1 , . . . y ∗ N ) as follows: x t = L y ∗ t − 1 , (2.1) h t = f ( x t , h t − 1 ) , (2.2) y t = so ftmax ( W h t + b ) . (2.3) The m atrix L ∈ R d x ×| V | is th e word embedd in g m atrix, where d x is the word embe dding dimen sion and | V | is the size of the vocabulary . The fu nction f ( ., . ) represents the recur rent neural network which takes in the cur rent input and the pr evious hidden state and p roduce s the next hidd e n state. W ∈ R | V |× d h and b ∈ R | V | are the the outpu t projection matrix an d the bias, respe cti vely , and d h is the size of the RNN hidden state. The | V | dimen sional y t models the d iscrete prob a bility d istribution for the next word. Note that the abov e formulatio n doe s no t make any assumption s abou t the specifics of the r e c urrent neural units, and f could be replaced with a standard recur rent unit, a gated recu r rent unit (GR U) ( Cho et al. , 2014 ), a long-short term mem ory (LSTM) unit ( Hochreiter & Sch midhub er , 1997 ), etc. For ou r experimen ts, we use LSTM units with two layer s. Giv e n y t for the t th example, a loss is ca lculated for that example. The loss used in the RNNLMs is almost exclusi vely the cross-en tropy between y t and th e o b served on e -hot word token, y ∗ t : J t = CE ( y ∗ t k y t ) = − X i ∈| V | y ∗ t,i log y t,i . (2.4) W e shall refer to y t as the mo d el pred ic tio n distribution for the t th example, and y ∗ t as the emp ir- ical target distribution (both are in fact cond itional distributions g iv e n the history). Since cross- entropy an d K ullback-Leibler div ergence are equiv alen t when the target distribution is one-ho t, we can rewrite the loss fo r the t th example as J t = D K L ( y ∗ t k y t ) . (2.5) Therefo re, w e ca n think of the op timization of the conventional loss in a n RNNLM as tr ying to mini- mize th e distance 1 between the mode l prediction distribution ( y ) and the empirical target d istribution ( y ∗ ), which, with many training examples, will get close to m inimizing distance to the actual tar- get d istribution. In the f ramework which we will intr oduce, we utilize K ullba ck-Leibler divergence as op posed to cross-entropy due to its in tuitiv e interpre ta tio n as a distance between distributions, although the two are not equivalent in o ur fra m ew o rk. 3 A U G M E N T I N G T H E C RO S S - E N T RO P Y L O S S W e prop ose to aug m ent the conventional cro ss-entropy loss with an add itional loss ter m a s follo ws: ˆ y t = softmax ( W h t /τ ) , (3.1) J aug t = D K L ( ˜ y t k ˆ y t ) , (3.2) J tot t = J t + αJ aug t . (3.3) In above, α is a hy perparam eter to be ad justed, and ˆ y t is almost identical to th e r egular model prediction distribution y t with the excep tio n that th e log its are divided by a temp erature p a rameter τ . W e define ˜ y t as some prob ability distrib utio n that estimates the true data distribution (conditioned on the word history) which satisfies E ˜ y t = E y ∗ t . The g oal of this fram ew o rk is to minimize the 1 W e note, ho we ver , that Kullbac k-L eibler diver gence is not a valid distance metric. 2 Published as a con f erence pap er at ICLR 201 7 distribution distance b etween the predictio n d istribution and a mo re accur a te estimate o f the true data distribution. T o u n derstand the effect of optimizing in th is setting, let’ s focus o n an ideal case in which w e are giv en th e true data distribution so that ˜ y t = E y ∗ t , an d we on ly use the augmen te d loss, J aug . W e will carry out ou r in vestigation through stochastic gradient descent, which is the techniq ue dominantly used for training neu ral networks. Th e g r adient of J aug t with respect to the log its W h t is ∇ J aug t = 1 τ ( ˆ y t − ˜ y t ) . (3.4) Let’ s de n ote by e j ∈ R | V | the vector whose j th entry is 1, and others are zero. W e can then rewrite ( 3.4 ) as τ ∇ J aug t = ˆ y t − e 1 , . . . , e | V | ˜ y t = X i ∈ V ˜ y t,i ( ˆ y t − e i ) . (3.5) Implication o f ( 3.5 ) is the following: Every time th e optimizer sees one training exam p le, it takes a step n ot only on accoun t of the label seen , but it pro c eeds taking into acco u nt all the class lab els fo r which the conditiona l prob ability is no t zero , and the re la tive step size for each step is gi ven by the condition al probability for that label, ˜ y t,i . Furthermo re, this is a much less noisy upd ate since the target distribution is e x act and deterministic. Therefo r e, unless all the example s exclusively belon g to a specific class with proba b ility 1 , the optimizatio n will act much differently and train with greatly improved sup ervision. The idea proposed in the r ecent work by Hinton et al. ( 2015 ) mig ht be con sidered as an application of this fra m ew o rk, w h ere they try to o btain a go od set of ˜ y ’ s by training very large mo d els a n d using the model pred iction distributions of tho se. Although fin d ing a good ˜ y in ge n eral is rath e r nontr i vial, in the c ontext of langu age modelin g we can hope to achiev e this b y exp loiting the inherent m etric sp a c e of classes en coded into the model, namely the space of word embed dings. Specifically , we pro p ose the fo llowing f or ˜ y : u t = Ly ∗ t , (3.6) ˜ y t = softmax L T u t τ . (3.7) In w o rds, we first find the target word v ector which corresponds to the target word token ( r esulting in u t ), a nd then take the inner pro d uct of the target word vector with all the other word vectors to get an unnor malized probability distribution. W e adjust this with th e same temp erature parameter τ used for obtainin g ˆ y t and apply softmax. The target distrib ution estimate, ˜ y , th erefore measures the similarity between the word vectors an d assigns similar pro b ability masses to words that th e languag e mod el deems close. No te that the estimation o f ˜ y with th is proced ure is iterative, and the estimates of ˜ y in the in itial ph ase of the train ing are no t necessarily in formative. Howev er , as training pro cedes, we expect ˜ y to captur e the word statistics better an d yield a consistently more accurate estimate of the true d a ta distribution. 4 T H E O R E T I C A L L Y D R I V E N R E U S E O F W O R D E M B E D D I N G S W e now theoretically moti vate and introduce a second modification to improve learnin g in the lan- guage mode l. W e do this by analyz ing th e propo sed au gmented loss in a particu lar setting , and observe an implicit co re mechan ism of th is loss. W e th en make our prop osition by makin g th is mechanism explicit. W e start by intr oducing o ur setting for the analysis. W e restrict our attention to the case where th e input embedding dimension is equ a l to the dim ension of th e RNN h idden state, i.e. d , d x = d h . W e also set b = 0 in ( 2.3 ) so that y t = W h t . W e only use the augmented loss, i.e. J tot = J aug , an d we assume that we can achieve zero training loss. Finally , we set the temperature param eter τ to be large. W e first show th at when the tem perature parameter, τ , is high enou gh, J aug t acts to match the logits of the predictio n distribution to the logits of th e th e more informative labels, ˜ y . W e proceed in the sam e 3 Published as a con f erence pap er at ICLR 201 7 way as was d one in Hinton et al. ( 201 5 ) to make an id e ntical argu ment. Particular ly , we consider the deriv a tive o f J aug t with respect to the entries of the lo gits p r oduced by the ne u ral network. Let’ s denote by l i the i th column of L. Using the fir st order approxim a tio n of exponential function around z e r o ( exp ( x ) ≈ 1 + x ), we can approximate ˜ y t (same ho lds for ˆ y t ) at high temperatu res as follows: ˜ y t,i = exp ( h u t , l i i /τ ) P j ∈ V exp ( h u t , l j i /τ ) ≈ 1 + h u t , l i i /τ | V | + P j ∈ V h u t , l j i /τ . (4.1) W e can fur th er simplify ( 4.1 ) if w e assum e that h u t , l j i = 0 on average: ˜ y t,i ≈ 1 + h u t , l i i /τ | V | . (4.2) By replacin g ˜ y t and ˆ y t in ( 3.4 ) with their simplified for ms accord ing to ( 4 .2 ), we g e t ∂ J aug t ∂ ( W h t ) i → 1 τ 2 | V | W h t − L T u t i as τ → ∞ , (4.3) which is th e de sired result that a u gmented loss tries to match the logits of th e model to the logits of ˜ y ’ s. Since the training loss is zero b y assumptio n, we n ecessarily have W h t = L T u t (4.4) for each tr a ining example, i.e., gr a dient contr ibuted b y each example is z ero. Provided that W and L are full rank matrices and ther e are mor e line a rly ind e pendent examples o f h t ’ s than the embed ding dimension d , we g et that the space spanned by the column s of L T is equiv alent to that spanned by the colu mns of W . Let’ s now intro duce a squ are matrix A such that W = L T A . (W e know A exists since L T and W span the same column space). In th is case, we can rewrite W h t = L T Ah t , L T ˜ h t . (4.5) In oth er words, by reusing th e em b edding matrix in the output pr o jection layer (with a tr a n spose) and letting the n eural n e twork do the necessary linear mapping h → Ah , we ge t the same result as we would h av e in the first p lace. Although the above scenario could be difficult to exactly replicate in practice, it uncovers a mech- anism thro ugh which our prop o sed loss augmentation acts, which is tr y ing to constrain the outpu t (unno rmalized) p robability spac e to a small subspace governed by the embe d ding matrix. This sug- gests th at we can make this mechanism explicit and con strain W = L T during training while setting the outp ut b ias, b , to zero. Doing so would n ot only elimin ate a big matrix which d ominates the network size for mo dels with even moderately sized vocabularies, but it would also be optim al in our setting of loss augmen ta tio n as it would eliminate much work to be don e b y the aug mented loss. 5 R E L A T E D W O R K Since their intro duction in Mikolov et al. ( 201 0 ), m a ny improvements have been prop osed for RNNLMs , including different dropout metho ds ( Zaremba et al. , 20 14 ; Gal , 2015 ), novel recurre n t units ( Zilly et al. , 2 0 16 ), and u se of pointer n etworks to com plement the r ecurrent neural network ( Merity et al. , 2016 ). Howe ver, none of the impr ovements dealt with th e loss stru cture, and to the best of our knowledge, o u r work is the first to offer a ne w loss fr amew ork. Our techn ique is clo sely related to the o ne in Hinton et al. ( 2015 ), where th ey also try to estimate a more informed data distrib ution and augment th e co n ventio nal loss with KL di vergenc e b e twe en model pred iction distribution and th e estimated data distribution. However , th ey estimate their data distribution by training large n etworks o n the data and then use it to improve learnin g in smaller networks. This is fundamentally different fr om ou r ap proach , wh ere we improve le a rning by trans- ferring knowledge between different p arts o f th e same n e twork, in a self contained manner . The w o rk we pre sen t in this paper is based on a report which was made pu blic in Inan & Khosravi ( 2016 ). W e have rec ently co me across a con current prep rint ( Pr ess & W o lf , 2016 ) wher e the authors reuse the word embedd in g m atrix in the outp ut p rojection to imp rove langu age modeling . How- ev er , their work is pu rely emp irical, and they d o n ot p rovide any th eoretical justification f or their 4 Published as a con f erence pap er at ICLR 201 7 approa c h . Finally , we would like to note that th e idea of using the same re p resentation for inpu t and outpu t words has been explor ed in the past, and there exists lang uage models which co uld be interpreted as simple neural n etworks with shar ed inp ut and o utput emb eddings ( Bengio et al. , 2001 ; Mnih & Hinton , 2 0 07 ). Howe ver , shared input and output representatio ns were im plicitly built into these models, rather tha n proposed as a supplemen t to a baseline. Con sequently , p ossibility of im- provement was no t pa rticularly pursued b y sh aring in put and output represen ta tio ns. 6 E X P E R I M E N T S In o ur expe r iments, we use the Penn Treebank c orpus (PTB) ( M a r cus et al. , 199 3 ), and the W ikitext- 2 d ataset ( Merity et al. , 2016 ). PTB has been a stand a r d dataset used for be n chmark in g language models. I t consists of 92 3 k training , 7 3 k validation, and 82 k test word s. The version o f this dataset which we u se is the one p rocessed in Mikolov e t al. ( 2010 ), with the mo st fre q uent 10 k words selected to be in th e vocabulary an d rest replaced with a an < u nk > token 2 . W ikitext-2 is a dataset released recently as an alternati ve to PTB 3 . It contains 2 , 088 k training, 217 k validation, and 2 45 k test tokens, and h as a vocabulary o f 3 3 , 278 words; ther efore, in com p arison to PTB, it is rough ly 2 times larger in d a taset size, an d 3 times larger in v ocabulary . 6 . 1 M O D E L A N D T R A I N I N G H I G H L I G H T S W e closely fo llow the LSTM based langua ge m odel pro posed in Zarem b a et al. ( 201 4 ) for con struct- ing our baseline m o del. Specifically , we use a 2 -layer LSTM with the same n umber of hidde n u nits in each layer, and we use 3 different n e twork sizes: small ( 200 un its), m edium ( 6 50 units), and large ( 1500 units). W e tr ain our models using stochastic gradient descent, and we use a variant of the d ropou t me thod prop osed in Gal ( 2 015 ). W e defer fu rther details regarding training the models to section A of the appendix . W e refer to o ur baseline network as variational drop out LSTM, or VD-LSTM in short. 6 . 2 E M P I R I C A L V A L I D A T I O N F O R T H E T H E O RY O F R E U S I N G W O R D E M B E D D I N G S In Sectio n 4 , we showed that the pa rticular loss au gmentation schem e we choose con strains the output projectio n matrix to be close to the input embedding m atrix, without explicitly d oing so by reusing the in put embedd ing matrix . As a first experiment, we set ou t to validate this theoretical result. T o do this, we try to simu late the settin g in Sectio n 4 b y d oing the following: W e select a ra n domly cho sen 20 , 000 contig uous word sequ ence in the PT B tr aining set, and train a 2 -layer LSTM lang uage mod el w ith 300 units in each layer with lo ss aug m entation by minimizing th e following loss: J tot = β J aug τ 2 | V | + (1 − β ) J. (6.1) Here, β is the pr oportio n of the augmen ted loss used in the total loss, and J aug is scaled by τ 2 | V | to approx imately match th e magnitudes of the deriv atives of J and J aug (see ( 4.3 )). Since we aim to ach ieve th e minim um training loss possible, an d the goal is to show a par ticular r esult rathe r than to achie ve goo d generalizatio n, we do n o t use any kind of re gularization in th e ne ural network (e.g. weigh t decay , dropo ut). For this set of experime n ts, we also constrain each row of the input embedd in g matrix to have a no rm of 1 b e cause tra in ing become s difficult without th is co nstraint when only aug mented loss is u sed. After tra ining, we com p ute a metric that me a sures distance between the subspace span ned by the rows of the input embed d ing matrix, L , and that spanned by the c o lumns o f th e ou tput pr ojection m atrix, W . For this, we use a com mon metric based on th e relativ e residual no rm f rom projection of one matrix onto ano ther ( Bj ¨ orck & Golub , 19 73 ). The computed distance betwe en the subspaces is 1 when they are ortho gonal, and 0 wh en they are the same. Inter ested read e r may ref er to sectio n B in the append ix for the details o f th is metric. Figure 1 shows th e r esults from two tests. I n one (pan el a), we test the effect of using th e augm ented loss by sweeping β in ( 6.1 ) fro m 0 to 1 at a reasonab ly high tempera ture ( τ = 10 ). W ith no loss augmen ta tio n ( β = 0 ), the distance is almost 1 , and as more and more augmented loss is used the 2 PTB can be downloaded at http://www .fit.vutbr .cz/ imikolov/rnnlm/simple-e xamples.tgz 3 W i kitext-2 can be do wnloaded at https://s3.amazona ws.com/research.metamind.io/wikitex t/wikitext-2-v1.zip 5 Published as a con f erence pap er at ICLR 201 7 0.0 0.2 0.4 0.6 0.8 1.0 Proportion of Augmented Loss( β ) 0.0 0.2 0.4 0.6 0.8 1.0 Normalized distance (a) Subspace distance at τ = 10 for differe nt proportions of J aug 0 5 10 15 20 25 30 35 40 T emperature( τ ) 0 . 06 0 . 08 0 . 10 0 . 12 0 . 14 0 . 16 0 . 18 0 . 20 Normalized distance (b) Subspace distance at different temp- eratures when only J aug is used Figure 1: S ubspace distance between L T and W for different experiment conditions for the v alidation ex- periments. Results are av eraged ov er 10 independent runs. These results v alidate our theory under practical conditions. distance decreases rapidly , and eventually reach es around 0 . 06 when only augmented loss is used. In th e second test (pan el b), we set β = 1 , and try to see the effect of the temperatu r e on the sub space distance (remem ber the theory predicts lo w distance when τ → ∞ ). Notably , the au gmented loss causes W to appro ach L T sufficiently even at temperatu res as low as 2 , alth ough higher temperatur es still le a d to smaller subspa c e distances. These results c o nfirm the m echanism throu gh which our pr oposed loss pu shes W to learn the same column space as L T , and it suggests that reusing the inp ut embedd ing matr ix by explicitly c on- straining W = L T is n ot simply a kind of regu larization, but is in fact an optima l choice in our framework. What can b e achie ved sepa r ately w ith each of the two proposed improvements as well as with the two of them comb ined is a q uestion of emp irical nature, whic h we inv estigate in the next section. 6 . 3 R E S U LT S O N P T B A N D W I K I T E X T - 2 D A TA S E T S In order to in vestigate the extent to which each of our prop osed imp rovements helps with learnin g, we train 4 d ifferent mo dels f or each network size: (1) 2-L ayer LSTM w ith variational drop out (VD-LSTM) (2 ) 2- Layer LSTM with variational drop out and au gmented loss (VD-LSTM +AL) (3) 2-Layer LSTM with variational dropout a n d reused em bedding s (VD-LSTM +RE) (4) 2 -Layer LSTM with variational drop out and bo th RE and AL ( VD-LSTM +REAL). Figure 2 shows the validation perp lexities o f the f our mo dels du ring tra in ing on the PTB corpu s for small (p a nel a) and large (panel b) netw orks. All of AL, RE, and REAL n etworks significantly outperf orm the baselin e in both cases. T able 1 comp ares the fina l validation and test perplexities of the fou r mod els on b o th PTB and W ik itext-2 for each network size. In both datasets, bo th AL and RE improve u p on the b aseline in dividually , and using RE and AL together leads to the best perfor mance. Based on perfo rmance comparison s, we make the following notes on the two pro posed improvements: • AL provides better per forman ce gains fo r smaller n etworks. This is n ot surp rising given the fact that sma ll models ar e rather inflexible, and one would expect to see impr oved learn- ing by trainin g a gainst a more inf ormative data d istribution (contr ibuted by the au g mented loss) (see Hinton et al. ( 201 5 ) ). For the smaller PTB dataset, p erforma n ce with AL sur- passes that with RE. In co mparison, for the larger Wikite x t-2 dataset, imp rovement by AL is mor e limited . This is expected given larger train in g sets better repre sent the true data distribution, m itig ating the su pervision problem. I n fact, we set out to validate this rea- soning in a direct man n er , an d a d ditionally train the small networks separately on the first and second h alves of the W ik itext-2 trainin g set. Th is results in two distinct datasets which are e a ch about the same size as PTB (10 44K vs 929K) . As can be seen in T ab le 2 , AL 6 Published as a con f erence pap er at ICLR 201 7 20 30 40 50 60 10 Epoch ( N ) 85 90 95 100 105 110 V alidation Perplexity +REAL +RE +AL Baseline (a) Small Network 15 30 45 60 75 10 Epoch ( N ) 70 75 80 85 90 95 100 V alidation Perplexity +REAL +RE +AL Baseline (b) L arge Network Figure 2: Progress of validation perplexities during training f or the 4 differen t models f or two (small ( 200 ) and large ( 1500 )) network sizes. has significan tly impr oved co mpetitive perfo r mance aga in st RE a n d REAL despite the fact that embedd ing size is 3 times larger com pared to PTB. The se re sults sup port our argument that the pro posed augmen ted loss term acts to improve th e amou nt of inform ation g athered from the dataset. • RE significantly o utperfor ms AL for larger networks. This indicates th a t, for large models, the mor e effective mechanism of o ur propo sed fram ew o rk is the o ne which enfor ces p r ox- imity between the o utput projection space and the inp ut embedding space. From a model complexity perspec ti ve, th e nontrivial g ains offered by RE f or a ll n etwork sizes and fo r both datasets could b e largely attributed to its explicit f unction to r educe the mo del size while preservin g the rep r esentational power acco rding to ou r f ramework. W e list in T able 3 the co mparison of models with and witho ut our pro posed modification s on the Pen n Treebank Corpu s. Th e best LSTM mo d el (VD-LSTM+ REAL) outperf o rms all pr evious work which uses conv entional fram ew o rk, includin g large en sembles. Th e re cently pr oposed rec u r- rent hig hway networks ( Z illy et al. , 20 16 ) when trained with r eused emb eddings (VD-RHN + RE) achieves the best overall perfor mance, improving on VD-RHN b y a p erplexity of 2 . 5 . T able 1: Comparison of t he final word lev el perplexities on the validation and test set for the 4 different models. PTB Wikitext-2 Network Model V alid T est V alid T est Small 4 (200 units) VD-LSTM 92.6 87.3 1 12.2 105.9 VD-LSTM+AL 86.3 82.9 1 10.3 103.8 VD-LSTM+RE 89.9 85.1 1 06.1 100.5 VD-LSTM+REAL 86.3 82.7 105.6 98 .9 Medium (650 units) VD-LSTM 82.0 77.7 1 00.2 95.3 VD-LSTM+AL 77.4 74.7 98.8 93.1 VD-LSTM+RE 77.1 73.9 92.3 87.7 VD-LSTM+REAL 75.7 73.2 91.5 87.0 Large 5 (1500 units) VD-LSTM 76.8 72.6 - - VD-LSTM+AL 74.5 71.2 - - VD-LSTM+RE 72.5 69.0 - - VD-LSTM+REAL 71.1 68.5 - - 4 For PTB, small models were re-trained by initializing to their fi nal configuration from the first training session. This did not change the final perplexity for baseline, but lead to improveme nts for the other models. 5 Large netwo rk results on W ikitext-2 are not reported since computational resources were insuf ficient to run some of the configurations. 7 Published as a con f erence pap er at ICLR 201 7 T able 2: Performan ce of the f our different small models trained on the equally si zed two partit ions of W i kit ext- 2 training set. These results are consistent with those on PTB (see T able 1 ), which has a similar training set size with each of these partitions, alt hough its word embedding dimension is three times smaller. Wikitext-2, P artition 1 Wikitext-2, P artition 2 Network Model V alid T est V alid T est Small (200 units) VD-LSTM 159.1 148.0 163.19 148.6 VD-LSTM+AL 153.0 142.5 156.4 143.7 VD-LSTM+RE 152.4 141.9 152.5 140.9 VD-LSTM+REAL 149.3 140.6 150.5 138.4 T able 3: Comparison of our work t o pre vious state of the art o n word-le vel va lidation and test perplexities on the Penn Tree bank corpus. Mod els using our framew ork significantly outperform other models. Model Parameter s V alidation T est RNN ( Mikolo v & Zweig ) 6M - 124.7 RNN+LD A ( Mikolo v & Zweig ) 7M - 113.7 RNN+LD A+KN-5+Cache ( Mikolov & Zweig ) 9M - 92.0 Deep RNN ( Pascanu et al. , 2013a ) 6M - 107.5 Sum-Prod Net ( Cheng et al. , 2014 ) 5M - 100.0 LSTM (medium) ( Zaremba et al. , 2014 ) 20M 86.2 82.7 CharCNN ( Kim et al. , 2015 ) 19M - 78.9 LSTM (large) ( Zaremba et al. , 2014 ) 66M 82.2 78.4 VD-LSTM (large, untied, MC) ( Gal , 2015 ) 66M - 73 . 4 ± 0 . 0 Pointer Sentinel-LSTM(medium) ( Merity et al. , 2016 ) 21M 72.4 70.9 38 Large L S TMs ( Z aremba et al. , 2014 ) 2.51B 71.9 68.7 10 Large VD-L STMs ( Gal , 2015 ) 660M - 68.7 VD-RHN ( Zilly et al. , 2016 ) 32M 71.2 68.5 VD-LSTM +REAL (large) 51M 71.1 68.5 VD-RHN +RE ( Zilly et al. , 2016 ) 6 24M 68.1 66.0 6 . 4 Q UA L I TA T I V E R E S U LT S One impo rtant feature of o ur fr a mew o rk tha t leads to better word predictions is the explicit mecha- nism to assign probab ilities to words not m erely accord ing to the o b served ou tput statistics, but also considerin g th e me tric similarity b e twe en words. W e ob serve direct co nsequences of this m echa- nism q ualitatively in the Penn Treebank in different ways: First, we n otice th at the pr obability of generating the < unk > token with ou r pro posed network (VD-LSTM +REAL) is significantly lower compare d to th e baseline network (VD-LSTM) acro ss m any words. This cou ld b e explained by noting the fact that the < un k > token is an aggregated token rath er than a spe c ific word, and it is often not expected to b e close to specific words in the word em b edding space. W e observe the same behavior with very frequ e n t words such as ”a”, ”an”, and ”th e”, owing to the same fact tha t they are not c o rrelated with p articular words. Second, we not o nly observe better proba bility assignments for the target words, but we also observe relatively higher prob ability weights associated with the words close to the targets. Som etimes this happens in the form of predicting word s seman tica lly close to- gether which are plausible even when the target word is not successfu lly captur ed by the mod el. W e provide a few examp les f rom the PTB test set which comp are the prediction perfor m ance of 1 500 unit VD-LST M and 1500 u nit VD-LSTM +REAL in table 4 . W e w o uld like to note that p rediction perfor mance of VD-LSTM +RE is similar to VD-LST M +REAL fo r the large network. 6 This model was dev eloped following our work i n Inan & Khosravi ( 2016 ). 8 Published as a con f erence pap er at ICLR 201 7 T able 4: Prediction for the next word by the baseline (VD-LS TM) and proposed (VD - LSTM +RE AL) networks for a few e xample phrases in the PTB test set. T op 1 0 wo rd p redictions are sorted i n descending probab ility , and are arranged in column-major format. Phrase + Next wor d(s) T op 10 predicted words VD-LSTM T op 10 predicted words VD-LSTM +REAL information international said it believ es t hat the complaints filed in + f edera l court the 0.27 an 0.03 a 0.13 august 0.01 federal 0.13 ne w 0.01 N 0.09 response 0.01 h unk i 0.05 connection 0.01 federal 0.22 connec tion 0.03 the 0.1 august 0.03 a 0.08 july 0.03 N 0.06 an 0.03 state 0.04 september 0.03 oil compan y refi neries ran flat out to prepare for a robust holiday driv ing season in july and + august the 0.09 in 0.03 N 0.08 has 0.03 a 0.07 is 0.02 h unk i 0.07 will 0.02 was 0.04 its 0.02 august 0.08 a 0.03 N 0.05 in 0.03 early 0.05 that 0.02 september 0.05 ended 0.02 the 0.03 its 0.02 southmark said it plans to h unk i its h unk i to provid e financial results as soon as its audit is + completed the 0.06 to 0.03 h unk i 0.05 likely 0.03 a 0.05 expected 0.03 in 0.04 scheduled 0.01 n’t 0.04 completed 0.01 expec ted 0.1 a 0.03 completed 0.04 scheduled 0.03 h unk i 0.03 n’t 0.03 the 0.03 due 0.02 in 0.03 to 0.01 merieux said the gov ernment ’ s minister of industry science and + t echn ology h unk i 0.33 industry 0.01 the 0.06 commerce 0.01 a 0.01 planning 0.01 other 0.01 management 0.01 others 0.01 mail 0.01 h unk i 0.09 ind ustry 0.03 health 0.08 busine ss 0.02 de velopment 0.04 telecomm. 0.0 2 the 0.04 human 0.02 a 0.03 other 0.01 7 C O N C L U S I O N In this work, we intro duced a novel loss fram ew o rk fo r languag e mod eling. Particularly , we showed that the m e tric encod ed into th e space of word embedd ings could b e used to generate a more in- formed data distribution than the on e-hot targets, and tha t add itionally training against this distri- bution improves learnin g. W e also showed theoretically that this approach lends itself to a second improvement, wh ich is simply reu sing the in put embedd ing matrix in the output projection layer . This has an addition a l benefit of r educing the num ber o f trainable variables in the mod el. W e empir- ically validated the theoretica l link , and verified that both pro posed chan ges do in fact belong to th e same fram ework. In ou r experime n ts on th e Penn Treebank corpus and W ikitext-2, we showed that our framew o rk outper f orms the con ventional on e, and tha t even the simple modification of reusing the word embedd in g in the outp u t proje c tion layer is sufficient fo r large networks. The imp rovements achieved by o ur framework are not uniq ue to vanilla lang uage modeling , and are readily a p plicable to other tasks which utilize lan g uage mod els such as n eural mac h ine translatio n , speech recogn ition, and text summar ization. This could lead to significant impr ovements in su ch models especially with large vocabularies, with the additio nal benefit of gre a tly reducin g the number of paramete r s to be trained. 9 Published as a con f erence pap er at ICLR 201 7 R E F E R E N C E S Y oshua Bengio, R ´ ejean Ducharm e, and Pascal V incent. A n eural p robab ilistic lang uage mo d el. 2001. URL http://www.i ro.umontreal. ca/ ˜ lisa/pointeu rs/nips00_lm. ps . ◦ Ake Bj ¨ orck an d Gen e H Golub. Nu merical metho ds fo r com puting angles between linear subspaces. Mathematics of computatio n , 27(1 23):579 –594, 1973 . W ei-Chen Che ng, Stanley K o k, Hoa i V u Pham, Hai Leong Chieu, and Kian Ming Adam Chai. Languag e modeling with sum-p r oduct networks. 201 4. Kyunghyun Ch o , Bart V an Merr i ¨ enboer, Dzmitry Bahdanau , and Y oshua Bengio . On the proper ties of neur al machine tran slation: Encoder-decod er a pproach es. a rXiv preprint arXiv:1 409.1 259 , 2014. Orhan Firat, Kyunghyun Ch o , and Y oshua Bengio . Mu lti-way , m ultilingual neural mach ine tran sla- tion with a shared attention m e c hanism. arXiv pr ep rint arXiv:1601. 01073 , 20 16. Charlie Frog ner , Chiyua n Z hang, Hossein Mob ahi, Mauricio Araya, and T o maso A Po g gio. Learn- ing with a wasserstein loss. I n Adva nces in Neural In formation Pr ocessing S ystems , pp. 205 3– 2061, 201 5. Y arin Gal. A th eoretically grou n ded applicatio n of dr opout in recurr e n t neu ral n etworks. a rXiv pr ep rint arXiv:1512 .05287 , 2 0 15. Geoffrey Hinto n, Orio l V inyals, an d Jeff Dean . Distilling the kn owledge in a neu ral network. arXiv pr ep rint arXiv:1503 .02531 , 2 0 15. Sepp Hochreiter and J ¨ urgen Schm id huber . Lon g short-ter m m emory . Neural co mputation , 9(8 ): 1735– 1780, 1997. Hakan I nan an d Khashayar Kh osravi. Impr oved learning th rough a u gmenting the loss. Stanford CS 224D: Deep Learning for Natural Language Pr ocessing, Spring 2016 , 2 0 16. Kazuki Irie, Zolt ´ an T ¨ uske, T a m er Alkh ouli, Ralf Sch l ¨ uter, and Hermann Ney . Lstm, gru, high - way and a bit of attention: an em p irical overvie w for language modelin g in spe ech recogn itio n. Interspeech, San F rancisco, CA, USA , 2 016. Camille Jord an. Essai sur la g ´ eom ´ etrie ` a n dimen sions. Bulletin de la So ci ´ et ´ e math ´ ematique de F rance , 3:10 3 –174, 187 5. Y oon Kim, Y acine Jern ite, David Son tag, an d Alexander M Rush. Character-aware n e ural lang uage models. arXiv preprint arXiv:1508.06 615 , 201 5 . Mitchell P Mar c u s, Mar y Ann Marcinkiewicz, and Beatrice Santorini. Build ing a large annotated corpus of english: The penn treeban k. Computa tional linguistics , 19( 2):313 –330, 199 3. Stephen Merity , Caiming Xiong , James Bradbury , and Richard Socher . Pointer sentinel mixtu re models. arXiv preprint arXiv:1609.07 843 , 201 6 . T omas Mikolov an d Geoffrey Zweig. Context depen dent recur rent neural network languag e mode l. T omas Mikolov , M artin Karafi ´ at, L ukas B urget, J an C ernock ` y, and Sanjeev Kh u danpu r . Recurren t neural network b ased lan guage mo del. In Interspeech , volume 2, pp. 3 , 2 010. T omas Mikolov , Ilya Sutskever , Kai Chen , Greg S Corra do, and Jeff De a n. D istributed r epresen- tations of words a nd phrases and their co mpositionality . In Advances in neural info rmation pr o - cessing systems , pp. 311 1–311 9, 2013 . Andriy Mnih an d Geoffrey Hinto n . Three new graph ical mo dels f or statistical language modelling . In Pr o ceedings of the 24th internatio nal con fer ence on Machin e learnin g , pp . 641– 6 48. A CM, 2007. Ramesh Nallapati, Bowen Zho u, C ¸ ag lar Gulc ¸ ehre, and Bing Xiang. Abstractive text summariz a tio n using sequenc e-to-sequen ce rnns and beyond . 2016 . 10 Published as a con f erence pap er at ICLR 201 7 Razvan Pascanu, C ¸ aglar G ¨ ulc ¸ ehre, Kyunghy un Cho, an d Y oshua Bengio . How to con struct deep recurren t n eural networks. CoRR , abs/13 1 2.602 6, 201 3a. Razvan Pascanu, T omas Mikolov , and Y oshua Bengio. On the difficulty of train in g recu rrent n eural networks. ICML (3) , 28:13 10–1 3 18, 2013 b. Jeffrey Penningto n, R ichard Socher, and Christoph er D Man ning. Glove: Globa l vectors for word representatio n. In EMNLP , volume 14, pp. 153 2–43, 201 4. Ofir Press and Lior W olf. Using the ou tput emb edding to imp rove lan g uage m odels. arXiv preprint arXiv:160 8.058 59 , 2016. Alexander M Rush, Sumit Cho pra, and Jason W eston. A neu ral attention mode l f or ab stractiv e sentence summar ization. arXiv preprint arXiv:1509.00 685 , 201 5 . Richard Socher, Alex Perely gin, Jean Y W u, Jason Chu ang, Christoph er D Mann ing, And rew Y Ng, and Christop her Potts. Recursive deep models fo r semantic compo sitionality over a sentiment treebank . Citeseer, 2013. W ojciech Zarem ba, Ilya Sutske ver , and Oriol V inyals. Recurren t neural network regulariza tio n. arXiv pr ep rint arXiv:1409. 2329 , 2 014. Julian Georg Zilly , Rupesh Kumar Sriv astav a , Jan K o utn´ ık, an d J ¨ urgen Schmidh uber . Recurrent highway n etworks. a rXiv pr eprint arXiv:16 07.03 474 , 201 6 . 11 Published as a con f erence pap er at ICLR 201 7 APPENDI X A M O D E L A N D T R A I N I N G D E TA I L S W e begin train ing with a learnin g rate of 1 and start de c a ying it with a constant rate after a certain epoch. This is 5 , 10 , and 1 f or the small, medium, and large n etworks re sp ecti vely . The decay rate is 0 . 9 for the small and m e d ium n e tworks, and 0 . 9 7 for th e large network. For bo th PTB and Wikitext-2 datasets, we unroll the network for 35 steps fo r b ackprop agation. W e u se gradien t c lipping ( Pascanu et al. , 2013 b ) ; i.e. we rescale the gr adients using the global no rm if it exceeds a certain value. For both datasets, this is 5 for the small and the medium n etwork, and 6 for the large ne twork . W e u se the dr opout method introd uced in Gal ( 2015 ); particu larly , we use the same dr opout mask for ea ch exam ple thro ugh the un r olled network. Differently fro m what was prop osed in Gal ( 201 5 ), we tie the d ropou t weights fo r hidden states further, and w e u se the sam e mask when they are propag ated as states in the curren t laye r and when they are u sed as in p uts fo r th e next lay er . W e don’t use dropout in the input emb edding layer, and we use th e same dropout p robability for inp uts and h idden states. For PTB, d ropou t pro babilities are 0 . 7 , 0 . 5 and 0 . 35 for small, me d ium and large networks respectively . For W ik itext-2 , pr obabilities are 0 . 8 for the small and 0 . 6 f or the m edium networks. When train in g the networks with the aug mented loss (AL ) , we use a tem perature τ = 20 . W e ha ve empirically observed that setting α , th e weight o f th e augmented lo ss, according to α = γ τ fo r all the n etworks works satis factorily . W e set γ to values between 0 . 5 and 0 . 8 fo r the PTB dataset, and between 1 . 0 and 1 . 5 f or the W ikitext-2 dataset. W e would like to no te that we have not o bserved sudden deterior a tions in the perf ormance with respect to m oderate variations in either τ o r α . B M E T R I C F O R C A L C U L A T I N G S U B S P A C E D I S T A N C E S In this section, we d etail the metric used for comp uting the sub space distance between two matrices. The compu ted metric is closely related with the p rinciple an gles b etween subspaces, first defined in Jordan ( 1875 ). Our aim is to co mpute a metric distance between two given ma tr ices, X and Y . W e d o this in thr ee steps: (1) Obtain two matrices with o r thonor mal co lumns, U a n d V , such that span ( U ) =span ( X ) and span ( V ) =span ( Y ) . U and V co uld be o btained with a QR deco mposition. (2) Calculate th e pro jection of either on e of U and V o n to th e other; e.g. do S = U U T V , where S is the pr ojection of V onto U . Then calculate the residual matr ix as R = V − S . (3) Let k . k F r denote the fr o beniou s norm , and let C be the nu mber of column s o f R . Then the distance metric is fou nd as d wher e d 2 = 1 C k R k 2 F r = 1 C T r ace ( R T R ) . W e n ote that d as calculated above is a valid metric up to the equivalence set of matrices which span the same column spa c e, althou gh we are n ot go in g to show it. In stead, we will mention som e metric proper ties of d , and relate it to the p rincipal an gles between the subspaces. W e first work ou t an expression fo r d : 12 Published as a con f erence pap er at ICLR 201 7 C d 2 = T race ( R T R ) = T race ( V − U U T V ) T ( V − U U T V ) = T race V T ( I − U U T )( I − U U T ) V = T race V T ( I − U U T ) V = T race ( I − U U T ) V V T = T race ( V T V ) − T r ace U U T V V T = C − Trace U U T V V T = C − Trace ( U T V ) T ( U T V ) = C − k U T V k 2 F r = C X i =1 1 − ρ 2 i , (B.1) where ρ i is the i th singular v a lue of U T V , common ly referred to as the i th principle angle between the subspac es of X and Y , θ i . In a b ove, we used the cyclic permu tation p roperty o f the tra c e in the third and the fourth lines. Since d 2 is 1 C T r ace ( R T R ) , it is always non negati ve, and it is only zero wh en the residu a l is zero, which is the case when span ( X ) = sp an(Y). Further , it is symm e tric be twe e n U an d V d u e to the form of ( B.1 ) (singular values o f V T U and V T U are the same). Also, d 2 = 1 C P C i =1 sin 2 ( θ i ) , namely the av erage o f th e sine s of the prin c iple angle s, whic h is a quantity between 0 and 1 . 13
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment