Detecting Sockpuppets in Deceptive Opinion Spam
This paper explores the problem of sockpuppet detection in deceptive opinion spam using authorship attribution and verification approaches. Two methods are explored. The first is a feature subsampling scheme that uses the KL-Divergence on stylistic language models of an author to find discriminative features. The second is a transduction scheme, spy induction that leverages the diversity of authors in the unlabeled test set by sending a set of spies (positive samples) from the training set to retrieve hidden samples in the unlabeled test set using nearest and farthest neighbors. Experiments using ground truth sockpuppet data show the effectiveness of the proposed schemes.
💡 Research Summary
This paper, titled “Detecting Sockpuppets in Deceptive Opinion Spam,” presents a comprehensive investigation into identifying sockpuppets—single physical authors using multiple aliases to post deceptive fake reviews. The core challenge lies in the limited context per user ID (often just one review), which renders traditional behavioral spam detection methods ineffective. The authors reframe the problem as one of authorship verification (AV): given a few known reviews by a sockpuppet author a, the task is to build a verifier AV_a to determine if a new, unseen review was also written by a.
The paper begins with a hardness analysis, demonstrating that the performance of a verifier degrades significantly as the diversity and size of the negative class (¬a, all authors except a) increase. This highlights the fundamental difficulty of learning a representative model of the universal negative set from limited training data.
To address this, the authors propose two novel schemes:
-
Feature Subsampling via ΔKL-PTFs: This method models an author’s stylistic fingerprint using Parse Tree Features (PTFs). It calculates the Kullback-Leibler Divergence between the PTF distribution of the target author a and the negative set ¬a. The PTFs that contribute most to this divergence are selected as discriminative features. This process subsamples the original high-dimensional, sparse feature space into a lower-dimensional space containing the most author-specific stylistic markers, improving learning efficiency and model focus.
-
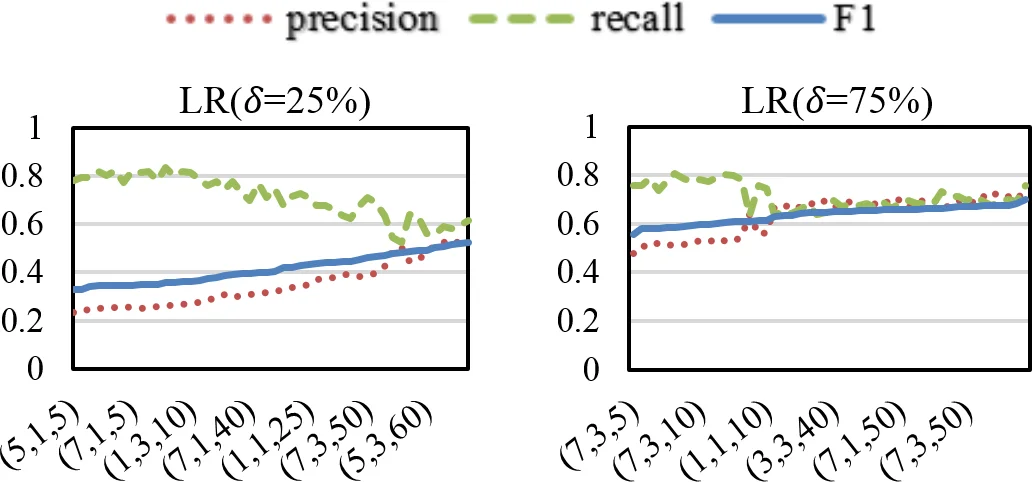
Spy Induction Transduction: This is an innovative transductive learning scheme designed to leverage the structure of the unlabeled test data. A carefully selected set of “spy” samples (known reviews by author a) from the training set is inserted into the unlabeled test set. Using a distance metric, the nearest neighbors (potential positive samples) and farthest neighbors (potential negative samples) of these spies within the test set are retrieved. These retrieved samples are then used to augment the original training set, effectively growing the diversity and representativeness of both positive and negative examples for retraining the verifier AV_a. This approach is distinct from traditional transduction, as it actively samples the test set rather than using it entirely.
The research is grounded in a novel dataset of ground-truth sockpuppet reviews collected via Amazon Mechanical Turk across three domains: hotels, restaurants, and products. Experimental results validate the effectiveness of both proposed methods. The ΔKL-PTFs feature selection improves upon baseline models using full lexical and PTF features. More impressively, the Spy Induction method consistently and significantly outperforms all baselines, including traditional transduction, across multiple classifiers (SVM, Logistic Regression, k-NN) in within-domain experiments. Its robustness is further confirmed in cross-domain experiments, where a model trained on one domain (e.g., hotels) is tested on another (e.g., products), with Spy Induction maintaining superior performance.
In conclusion, the paper makes significant contributions by formally defining the sockpuppet detection problem in opinion spam, constructing a valuable dataset, and proposing two effective, complementary solutions. The ΔKL-PTFs method offers a principled way to capture authorial style, while Spy Induction provides a powerful mechanism to overcome data sparsity by intelligently exploiting the unlabeled test environment. Together, they offer a promising direction for building practical and robust sockpuppet detection systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment