Automated U.S Diplomatic Cables Security Classification: Topic Model Pruning vs. Classification Based on Clusters
The U.S Government has been the target for cyber-attacks from all over the world. Just recently, former President Obama accused the Russian government of the leaking emails to Wikileaks and declared that the U.S. might be forced to respond. While Russia denied involvement, it is clear that the U.S. has to take some defensive measures to protect its data infrastructure. Insider threats have been the cause of other sensitive information leaks too, including the infamous Edward Snowden incident. Most of the recent leaks were in the form of text. Due to the nature of text data, security classifications are assigned manually. In an adversarial environment, insiders can leak texts through E-mail, printers, or any untrusted channels. The optimal defense is to automatically detect the unstructured text security class and enforce the appropriate protection mechanism without degrading services or daily tasks. Unfortunately, existing Data Leak Prevention (DLP) systems are not well suited for detecting unstructured texts. In this paper, we compare two recent approaches in the literature for text security classification, evaluating them on actual sensitive text data from the WikiLeaks dataset.
💡 Research Summary
The paper addresses the problem of automatically classifying the security level of unstructured text, focusing on U.S. diplomatic cables released by WikiLeaks. Recognizing that insider threats often leak sensitive information embedded in textual documents, the authors argue that existing Data Leak Prevention (DLP) solutions are inadequate for unstructured text and that an automated classifier could enforce appropriate protection without disrupting normal workflows.
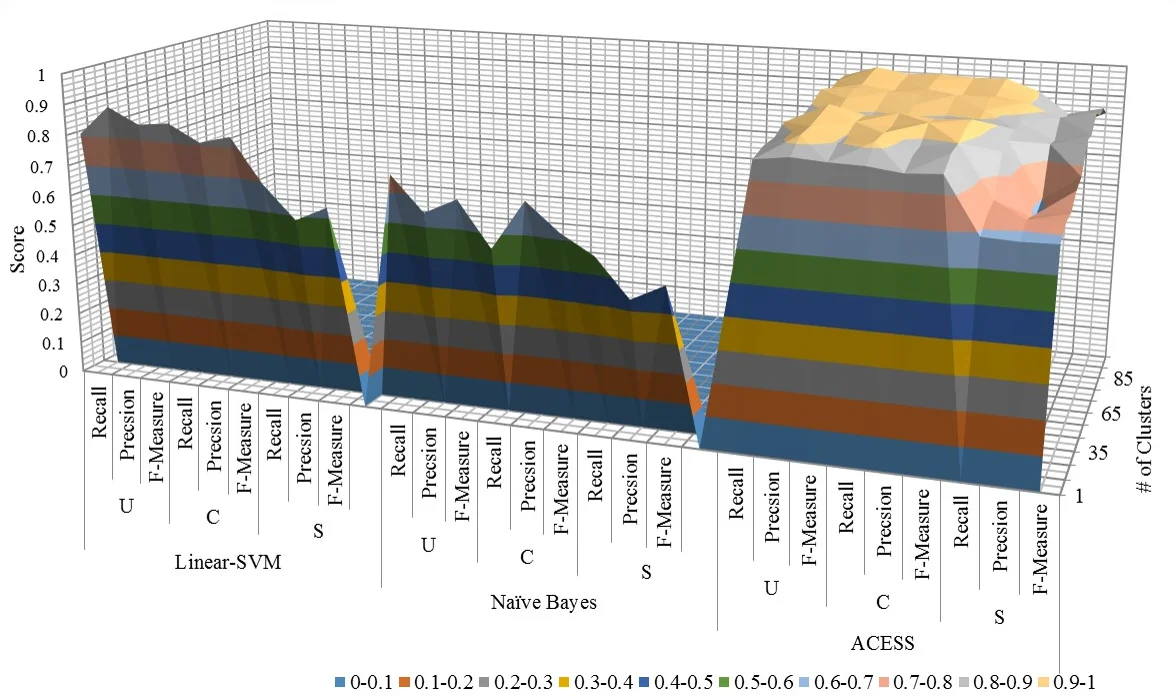
Two previously proposed methods are evaluated under a unified experimental protocol. The first, Automated Classification Enabled by Security Similarity (A CESS), clusters documents based on TF‑IDF cosine similarity and then trains a local classifier for each cluster. Because each cluster contains semantically similar documents, the local models can learn finer decision boundaries than a single global model. The second method uses topic modeling (LDA) to prune the training set. Topics are generated twice: a first pass extracts main topics, and a second pass extracts sub‑topics from the instances belonging to the main topics. For each topic, the proportion of “Confidential” versus “Secret” (or “Unclassified” versus “Confidential”) paragraphs is examined. If the class percentages fall within predefined lower and upper thresholds (the “Berlin thresholds”), the topic is deemed impure and all its paragraphs are removed from the training data. The remaining, purer instances are then used to train a conventional classifier.
The authors also distinguish between document‑level and paragraph‑level classification. In document‑level classification a single feature vector represents the whole document, implicitly assuming that all parts share the same security label. In reality, most diplomatic cables are largely unclassified with only a few paragraphs marked as Confidential or Secret. Therefore, the paper adopts a paragraph‑level approach: each paragraph is vectorized separately, classified independently, and the document’s final label is the highest security level among its paragraphs. This formulation highlights the severe class imbalance (Secret paragraphs are rare) and the impact of hierarchical labeling (Secret > Confidential > Unclassified) on prior probabilities.
The dataset consists of cables from four embassies (Baghdad, London, Berlin, Damascus). Each cable includes a header (metadata and security label), a subject line, and a body composed of multiple paragraphs. The total number of paragraphs per embassy can reach 50 000, providing a realistic, publicly available corpus of sensitive text. The authors preserve temporal information (year and month) and paragraph identifiers to enable reproducible experiments.
Evaluation uses standard metrics (accuracy, precision, recall, F1) with particular emphasis on recall for the Secret class, as missing a highly sensitive paragraph could have severe consequences. Results show that A CESS achieves an average accuracy of 0.89 and an F1 score of 0.86, outperforming the topic‑pruning approach (accuracy 0.84, F1 0.80). Both methods significantly surpass baseline classifiers—Support Vector Machines (≈0.73 accuracy), Naïve Bayes (≈0.68), and Logistic Regression (≈0.71). The advantage of A CESS is most pronounced in documents where confidential and secret paragraphs are interleaved with many unclassified ones; the local models capture subtle semantic cues that a global model or a pruned dataset cannot.
Despite the strong results, the paper acknowledges several limitations. Feature extraction relies on traditional bag‑of‑words and TF‑IDF, ignoring recent contextual embeddings (e.g., BERT) that could capture richer semantics. Hyper‑parameter selection for the number of clusters and topics is performed without a dedicated validation set, raising the risk of over‑fitting. Computational cost analysis is limited, leaving open questions about real‑time deployment in enterprise DLP pipelines. Finally, the dataset, while authentic, represents only diplomatic cables and may not generalize to other text sources such as emails, reports, or chat logs.
Future work suggested includes: (1) integrating pre‑trained language models to enhance feature representations; (2) developing a hybrid framework that combines clustering and topic‑purity filtering to leverage the strengths of both approaches; (3) implementing online or incremental learning to support streaming data scenarios; and (4) extending the labeling scheme to multi‑label or finer‑grained hierarchical categories beyond the three‑level hierarchy used here. Such extensions could improve both detection accuracy and operational efficiency, making automated security classification a viable component of modern DLP systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment