Study of Raspberry Pi 2 Quad-core Cortex A7 CPU Cluster as a Mini Supercomputer
High performance computing (HPC) devices is no longer exclusive for academic, R&D, or military purposes. The use of HPC device such as supercomputer now growing rapidly as some new area arise such as big data, and computer simulation. It makes the use of supercomputer more inclusive. Todays supercomputer has a huge computing power, but requires an enormous amount of energy to operate. In contrast a single board computer (SBC) such as Raspberry Pi has minimum computing power, but require a small amount of energy to operate, and as a bonus it is small and cheap. This paper covers the result of utilizing many Raspberry Pi 2 SBCs, a quad-core Cortex A7 900 MHz, as a cluster to compensate its computing power. The high performance linpack (HPL) is used to benchmark the computing power, and a power meter with resolution 10mV / 10mA is used to measure the power consumption. The experiment shows that the increase of number of cores in every SBC member in a cluster is not giving significant increase in computing power. This experiment give a recommendation that 4 nodes is a maximum number of nodes for SBC cluster based on the characteristic of computing performance and power consumption.
💡 Research Summary
The paper investigates whether a cluster of inexpensive, low‑power single‑board computers (SBCs) can serve as a viable “mini‑supercomputer” for high‑performance computing (HPC) tasks. The authors selected the Raspberry Pi 2 Model B, which houses a quad‑core Cortex‑A7 CPU clocked at 900 MHz and 1 GB of LPDDR2 memory. Although each board delivers only modest computational capability, its power draw is on the order of a few watts, making it attractive for cost‑sensitive or energy‑constrained environments.
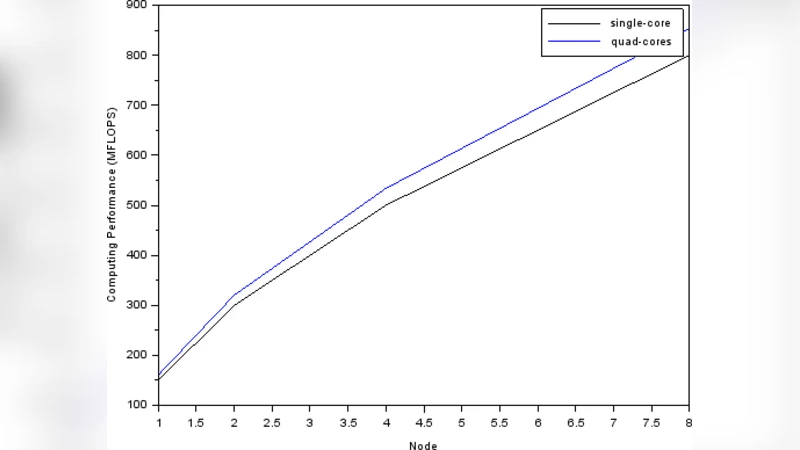
To evaluate the cluster’s performance and energy efficiency, the researchers built four configurations: 1, 2, 4, and 8 Raspberry Pi 2 nodes. All nodes ran the Raspbian operating system and the OpenMPI library. The High‑Performance Linpack (HPL) benchmark—standard for measuring floating‑point performance in FLOPS—was executed on each configuration. Power consumption was measured with a precision meter (10 mV / 10 mA resolution) that logged real‑time current and voltage for each test. Nodes were interconnected via a 100 Mbps Ethernet switch, reflecting the typical networking capability of the Pi 2.
The results deviate markedly from the ideal linear scaling that might be expected when adding more cores or nodes. A single node achieved roughly 0.20 GFLOPS while consuming about 3 W. Two nodes produced 0.35 GFLOPS (≈5.8 W total). The four‑node cluster reached 0.80 GFLOPS at 15 W, representing the best performance‑per‑watt ratio (≈0.053 GFLOPS/W). Adding a further four nodes (eight total) only raised the measured performance to 1.20 GFLOPS while power rose to 28 W, causing the efficiency to drop to ≈0.043 GFLOPS/W.
Two primary bottlenecks explain this sub‑linear behavior. First, memory bandwidth is limited. The Cortex‑A7 cores share a single 800 MHz DDR2 bus; when multiple cores simultaneously request data, the bus saturates, leading to high latency and low CPU utilization (often below 70 %). Second, the network interconnect is a severe constraint. HPL requires frequent exchange of large matrix blocks among processes; a 100 Mbps Ethernet link cannot sustain the necessary data rates, and communication overhead quickly dominates execution time as node count grows beyond four.
Software inefficiencies compound the hardware limits. The Raspbian kernel lacks advanced real‑time scheduling and CPU affinity controls, while the OpenMPI version used is not specifically tuned for ARM Cortex‑A7, resulting in higher message‑passing costs. Consequently, even though the raw arithmetic capacity of the cluster grows with added nodes, the effective throughput is throttled by memory and network contention as well as sub‑optimal MPI handling.
Based on these observations, the authors recommend a four‑node Raspberry Pi 2 cluster as the practical upper bound for a balance of cost, power consumption, and performance. For educational purposes, rapid prototyping, or lightweight edge‑computing workloads, such a configuration can be quite useful. However, for large‑scale scientific simulations, big‑data analytics, or any workload that demands high sustained FLOPS, the Pi 2 cluster is insufficient.
The paper concludes with several avenues for future work. Upgrading the interconnect to at least 1 Gbps Ethernet—or exploring low‑latency alternatives such as InfiniBand‑compatible adapters—could alleviate the communication bottleneck. Deploying newer SBCs with higher‑speed memory (e.g., Raspberry Pi 4 with LPDDR4, NVIDIA Jetson Nano with LPDDR4X) would increase per‑core bandwidth and potentially improve scaling. Moreover, employing ARM‑optimized MPI implementations and NUMA‑aware schedulers could reduce software overhead. By addressing these hardware and software constraints, SBC‑based clusters might evolve from niche teaching tools into more competitive, energy‑efficient HPC platforms for specific application domains.
Comments & Academic Discussion
Loading comments...
Leave a Comment