Consistent Alignment of Word Embedding Models
Word embedding models offer continuous vector representations that can capture rich contextual semantics based on their word co-occurrence patterns. While these word vectors can provide very effective features used in many NLP tasks such as clustering similar words and inferring learning relationships, many challenges and open research questions remain. In this paper, we propose a solution that aligns variations of the same model (or different models) in a joint low-dimensional latent space leveraging carefully generated synthetic data points. This generative process is inspired by the observation that a variety of linguistic relationships is captured by simple linear operations in embedded space. We demonstrate that our approach can lead to substantial improvements in recovering embeddings of local neighborhoods.
💡 Research Summary
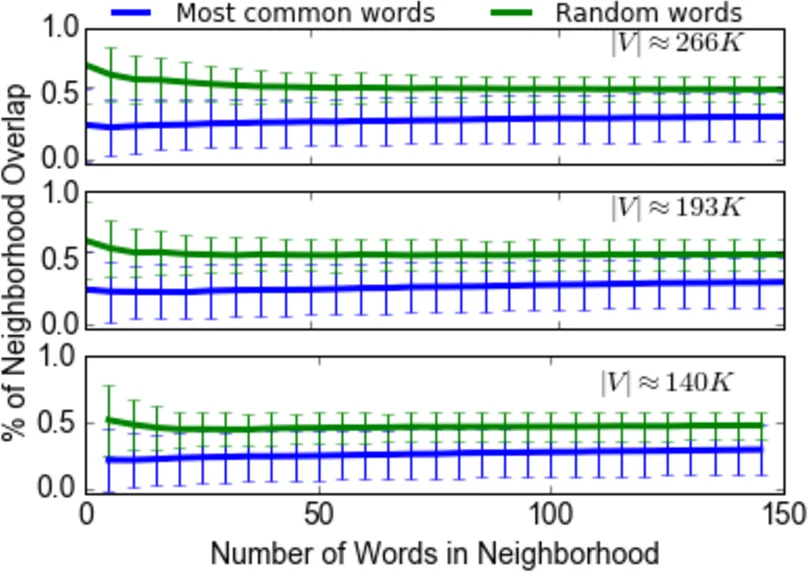
The paper tackles the problem of aligning multiple word‑embedding models—whether they are different runs of the same algorithm or entirely distinct architectures—into a single low‑dimensional latent space. The authors begin by demonstrating that even when trained on the same corpus (a 2016 Wikipedia dump) with identical hyper‑parameters, repeated training of a 200‑dimensional Word2Vec model yields highly unstable local neighborhoods. This instability is quantified by measuring the overlap of ε‑neighborhoods across successive model instances; the overlap rapidly deteriorates as the neighborhood size grows, indicating that high‑dimensional embeddings are sensitive to random initialization and the curse of dimensionality.
To address this, the authors propose a two‑step approach. First, they generate synthetic “latent words” within each model’s embedding space. These latent points are created by taking linear combinations of existing word vectors that lie within an ε‑neighborhood of a target word. Formally, a latent word (w_i^) is defined as (w_i^ = P(\alpha_n \times w_i^{r_n})), where (\alpha_n) is an integer randomly drawn from (
Comments & Academic Discussion
Loading comments...
Leave a Comment