Multiplex visibility graphs to investigate recurrent neural networks dynamics
A recurrent neural network (RNN) is a universal approximator of dynamical systems, whose performance often depends on sensitive hyperparameters. Tuning of such hyperparameters may be difficult and, typically, based on a trial-and-error approach. In this work, we adopt a graph-based framework to interpret and characterize the internal RNN dynamics. Through this insight, we are able to design a principled unsupervised method to derive configurations with maximized performances, in terms of prediction error and memory capacity. In particular, we propose to model time series of neurons activations with the recently introduced horizontal visibility graphs, whose topological properties reflect important dynamical features of the underlying dynamic system. Successively, each graph becomes a layer of a larger structure, called multiplex. We show that topological properties of such a multiplex reflect important features of RNN dynamics and are used to guide the tuning procedure. To validate the proposed method, we consider a class of RNNs called echo state networks. We perform experiments and discuss results on several benchmarks and real-world dataset of call data records.
💡 Research Summary
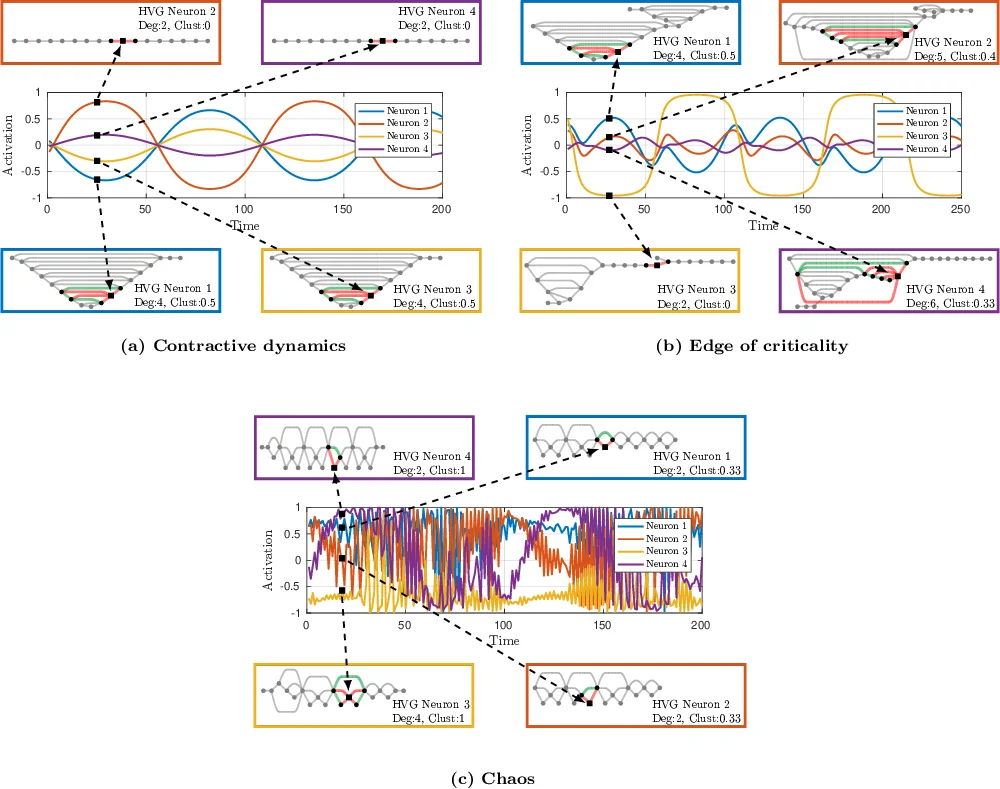
This paper introduces a novel graph‑theoretic framework for analyzing and tuning echo state networks (ESNs), a widely used class of recurrent neural networks (RNNs). The authors first convert the activation time series of each reservoir neuron into a Horizontal Visibility Graph (HVG), a planar graph where each time point becomes a vertex and edges are drawn according to a simple visibility criterion. To capture both temporal distance and amplitude differences, they extend the classic binary HVG to a weighted version (wHVG) whose edge weights are a function of the time lag and the absolute difference of the connected values.
All individual HVGs are then stacked into a multiplex network: each layer corresponds to one neuron, vertices are replicated across layers, and inter‑layer connections link the replicas while intra‑layer edges retain the neuron‑specific HVG structure. This multiplex representation preserves the full multivariate dynamics of the reservoir while providing a common set of vertex‑level descriptors (degree, clustering coefficient, betweenness, closeness, etc.) that can be computed for every time step.
The central insight is that the statistical distribution of these vertex properties reflects the underlying dynamical regime of the ESN. In particular, high entropy of the vertex‑property vectors indicates a heterogeneous, critical‑like state where the reservoir exhibits both fading memory (ordered dynamics) and high sensitivity to inputs (chaotic dynamics). Such a regime, often described as the “edge of criticality,” is known to maximize computational capacity. Consequently, the authors propose to search the hyper‑parameter space (spectral radius ρ of the reservoir matrix and input scaling ω_i) for configurations that maximize the average entropy of the multiplex vertex descriptors.
To assess memory capacity, the paper introduces a second unsupervised metric. Delayed versions of the input signal are also transformed into HVGs, and the similarity between the delayed‑input graphs and the neuron‑specific graphs is quantified via the agreement of their vertex descriptors. A high agreement implies that certain neurons retain information about past inputs, which directly translates into larger linear memory capacity.
These two graph‑based criteria are compared against traditional unsupervised indicators such as the maximal local Lyapunov exponent (MLLE) and the minimal singular value of the reservoir Jacobian (λ). Experiments are conducted on several synthetic benchmark tasks (e.g., NARMA, chaotic time‑series prediction) and on a real‑world Call Data Records (CDR) dataset. Results show that the entropy‑based multiplex measure reliably identifies hyper‑parameter settings that yield low prediction error and high memory capacity, often matching or surpassing the performance of supervised cross‑validation approaches while requiring no labeled validation data.
The paper’s contributions can be summarized as follows:
- A systematic method to map multivariate reservoir activations to a weighted HVG and then to a multiplex network, preserving both local and non‑local temporal information.
- Introduction of vertex‑entropy as a proxy for dynamical heterogeneity and a principled unsupervised objective for hyper‑parameter optimization.
- A novel graph‑based memory‑capacity estimator based on the alignment of delayed‑input and neuron graphs.
- Extensive empirical validation demonstrating that the proposed unsupervised tuning achieves competitive or superior performance compared to existing statistical methods and supervised baselines.
Overall, the work bridges time‑series analysis, complex‑network theory, and reservoir computing, offering a powerful new toolbox for interpreting and automatically configuring recurrent neural networks without relying on extensive labeled data.
Comments & Academic Discussion
Loading comments...
Leave a Comment