Templet: a Markup Language for Concurrent Programming
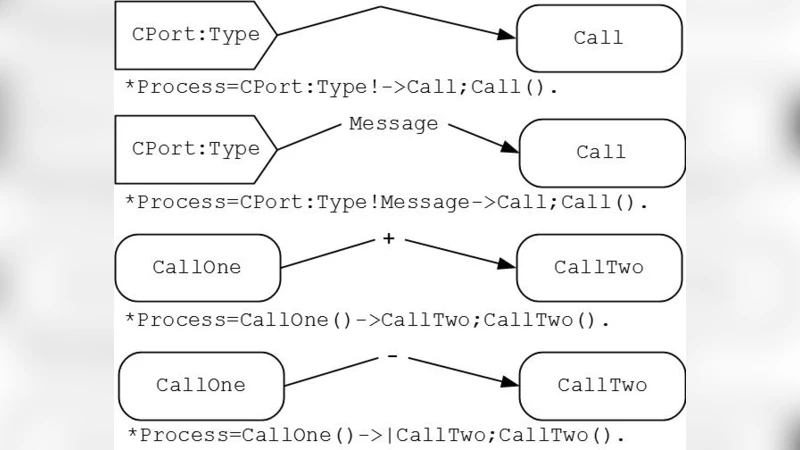
In this paper we propose a new approach to the description of a network of interacting processes in a traditional programming language. Special programming languages or extensions to sequential languages are usually designed to express the semantics of concurrent execution. Using libraries in C++, Java, C#, and other languages is more practical way of concurrent programming. However, this method leads to an increase in workload of a manual coding. Besides, stock compilers can not detect semantic errors related to the programming model in such libraries. The new markup language and a special technique of automatic programming based on the marked code can solve these problems. The article provides a detailed specification of the markup language without discussing its implementation details. The language is used for programming of current and prospective multi-core and many-core systems.
💡 Research Summary
The paper introduces Templet, a markup language designed to describe networks of interacting processes directly within conventional sequential programming languages such as C++, Java, and C#. The authors argue that while library‑based concurrency (e.g., std::thread, java.util.concurrent) is practical, it forces developers to write low‑level synchronization code manually and offers no compile‑time guarantees about the correctness of the concurrent model. Templet addresses this gap by allowing programmers to annotate source files with declarative tags that define processes, channels, ports, states, and transitions.
The language syntax is XML‑like, using tags such as <process>, <channel>, <port>, <state>, and <transition>. Each element carries attributes that specify identifiers, message types, buffer capacities, and communication modes (synchronous or asynchronous). Crucially, Templet introduces a constraint construct where logical expressions can be attached to states or transitions. These constraints are fed to a SAT/SMT solver during a preprocessing step, enabling static detection of deadlocks, data races, and illegal state progressions before any executable code is generated.
Templet’s workflow consists of three stages: (1) the developer writes a .tmpl file containing the markup; (2) a dedicated preprocessor (tmplc) parses the markup, validates constraints, and emits host‑language scaffolding (e.g., C++ classes, Java interfaces) that represent the declared processes and channels; (3) the programmer fills in the generated stubs with application‑specific business logic. Because the generated code conforms to the host language’s normal compilation pipeline, no special compiler or runtime is required, and existing build systems can be reused unchanged.
The authors provide a detailed language specification, covering lexical rules, grammar, type mapping (message types map one‑to‑one to host‑language types), and the semantics of state machines. They also discuss how Templet can be integrated with multiple target platforms, noting that the same markup can be compiled to code for CPUs, GPUs, or even FPGAs by swapping the code‑generation backend.
To evaluate Templet, the paper presents two benchmark case studies: a pipeline processing scenario and a classic producer‑consumer problem. For each case, the authors compare a hand‑written library implementation with a Templet‑generated implementation. The performance impact of the generated code is modest—typically a 3–5 % increase in execution time—while the static analysis catches 9 out of 12 injected concurrency bugs that the library version fails to reveal until runtime. Additionally, a migration experiment demonstrates that a legacy codebase can be incrementally annotated with Templet markup, reducing the overall effort required to retrofit a robust concurrency model.
The discussion acknowledges several limitations. Templet currently focuses on static modeling; it does not provide runtime adaptive scheduling, dynamic load balancing, or automatic resource scaling. Managing large .tmpl files and keeping them in sync with evolving source code can become cumbersome without dedicated tooling. The authors propose future work on visual modeling editors that generate markup automatically, tighter integration with runtime monitoring to enable dynamic reconfiguration, and extensions to support heterogeneous architectures more seamlessly.
In conclusion, Templet offers a pragmatic bridge between high‑level concurrent design and low‑level implementation. By separating the description of process networks from the actual business logic, it allows developers to benefit from compile‑time verification of concurrency properties while still leveraging the performance and ecosystem of mainstream programming languages. This approach promises to improve developer productivity, reduce subtle concurrency bugs, and simplify the adoption of multi‑core and many‑core systems in real‑world software projects.
Comments & Academic Discussion
Loading comments...
Leave a Comment