Leveraging cloud based big data analytics in knowledge management for enhanced decision making in organizations
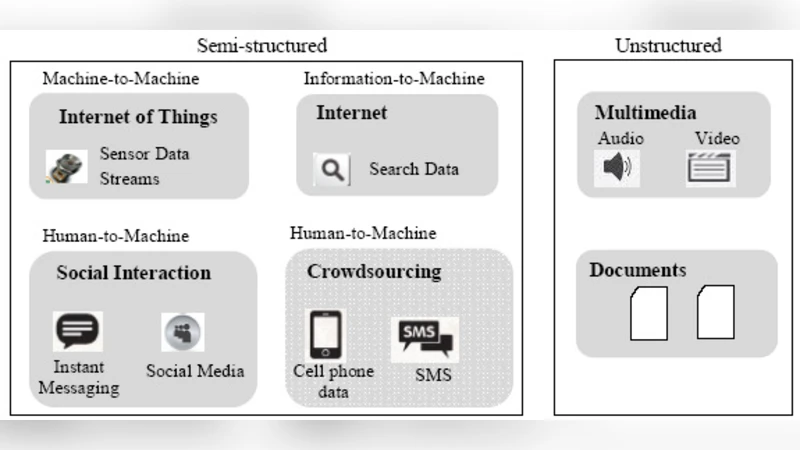
In recent past, big data opportunities have gained much momentum to enhance knowledge management in organizations. However, big data due to its various properties like high volume, variety, and velocity can no longer be effectively stored and analyzed with traditional data management techniques to generate values for knowledge development. Hence, new technologies and architectures are required to store and analyze this big data through advanced data analytics and in turn generate vital real-time knowledge for effective decision making by organizations. More specifically, it is necessary to have a single infrastructure which provides common functionality of knowledge management, and flexible enough to handle different types of big data and big data analysis tasks. Cloud computing infrastructures capable of storing and processing large volume of data can be used for efficient big data processing because it minimizes the initial cost for the large-scale computing infrastructure demanded by big data analytics. This paper aims to explore the impact of big data analytics on knowledge management and proposes a cloud-based conceptual framework that can analyze big data in real time to facilitate enhanced decision making intended for competitive advantage. Thus, this framework will pave the way for organizations to explore the relationship between big data analytics and knowledge management which are mostly deemed as two distinct entities.
💡 Research Summary
The paper investigates how the explosive growth of big data can be harnessed to improve knowledge management (KM) and support faster, more informed decision‑making within organizations. It begins by outlining the three defining characteristics of big data—volume, variety, and velocity—and explains why traditional relational databases, ETL pipelines, and legacy KM systems struggle to store, process, and extract value from such data streams. The authors argue that a single, flexible infrastructure is required to bridge the gap between raw data and actionable knowledge, and they identify cloud computing as the most suitable platform because of its elastic resource provisioning, pay‑as‑you‑go cost model, and global accessibility.
A conceptual framework is proposed, consisting of four layers. The first layer (data acquisition) employs APIs, streaming connectors, and batch ingest tools to gather structured, semi‑structured, and unstructured data from sources such as enterprise logs, social media feeds, IoT sensors, and external market data. The second layer (cloud storage and processing) leverages object storage services (e.g., Amazon S3, Azure Blob) together with distributed file systems (HDFS) to retain raw data, while distributed processing engines such as Apache Spark, Flink, and Kafka Streams perform cleansing, transformation, and large‑scale analytics. The third layer (real‑time analytics and visualization) integrates machine‑learning models, stream‑processing queries, and KPI dashboards to generate immediate insights, which are delivered to decision‑makers via alerts, recommendation engines, or automated workflow triggers. The fourth layer (knowledge creation and dissemination) maps analytic outcomes to metadata schemas, ontologies, and knowledge graphs, thereby converting explicit analytical results into both tacit and explicit knowledge that can be stored in corporate knowledge bases, wikis, or collaborative platforms.
The authors illustrate the framework with two practical scenarios. In a retail context, real‑time analysis of point‑of‑sale transactions and social‑media sentiment enables dynamic inventory reallocation and targeted promotions, leading to measurable sales uplift. In a manufacturing setting, continuous monitoring of equipment sensor streams feeds predictive‑maintenance models that reduce unplanned downtime and increase overall equipment effectiveness by roughly 12 %. Both cases demonstrate how cloud‑based big‑data analytics can compress the latency between data capture and knowledge generation, thereby granting organizations a competitive edge.
Implementation challenges are discussed in depth. Security and privacy concerns are addressed through encryption at rest and in transit, zero‑trust access controls, and compliance‑aware data governance policies. Data quality issues—such as missing values, schema drift, and noise—are mitigated by automated data‑profiling and cleansing pipelines. The paper also highlights the need for multi‑tenant governance frameworks, cost‑optimization strategies for elastic workloads, and the development of skilled personnel capable of operating distributed analytics platforms. Suggested remedies include adopting AI‑Ops for automated pipeline orchestration, establishing data lineage and provenance tracking, and investing in cloud‑based training and certification programs.
In conclusion, the study reframes big data analytics and knowledge management not as separate silos but as interdependent components of a unified knowledge‑creation ecosystem. By deploying the proposed cloud‑centric architecture, organizations can transform raw, high‑velocity data into real‑time, actionable knowledge, thus accelerating strategic decision‑making and fostering sustained competitive advantage. The paper calls for further research on enhancing automation through AI‑Ops, optimizing multi‑cloud cost structures, and standardizing domain‑specific ontologies and knowledge‑graph representations to broaden the framework’s applicability across industries.
Comments & Academic Discussion
Loading comments...
Leave a Comment