Index and Materialized View Selection in Data Warehouses
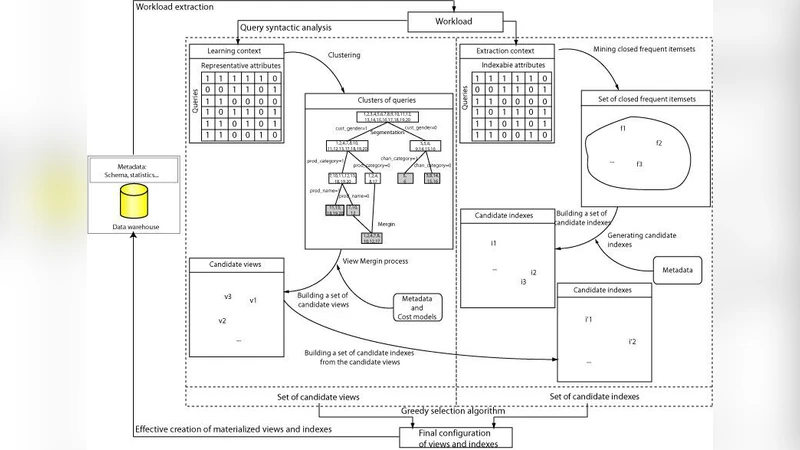
The aim of this article is to present an overview of the major families of state-of-the-art index and materialized view selection methods, and to discuss the issues and future trends in data warehouse performance optimization. We particularly focus on data mining-based heuristics we developed to reduce the selection problem complexity and target the most pertinent candidate indexes and materialized views.
💡 Research Summary
The paper provides a comprehensive survey of state‑of‑the‑art techniques for selecting indexes and materialized views (MVs) in data warehouse environments, and it proposes a novel data‑mining‑driven heuristic that dramatically reduces the combinatorial explosion inherent in the selection problem. The authors begin by categorizing existing approaches into four major families: (1) cost‑based methods that rely on detailed I/O, CPU, and memory cost models derived from system statistics and query workloads; (2) rule‑based techniques that encode expert knowledge such as “create B‑tree indexes on frequently joined columns” or “materialize aggregates at high‑level dimensions”; (3) evolutionary and meta‑heuristic algorithms (genetic algorithms, simulated annealing, particle swarm optimization) that explore the search space globally but require careful parameter tuning; and (4) data‑mining‑based strategies that mine query logs for frequent patterns and use those patterns to generate candidate objects. The authors argue that while each family has merits, none simultaneously addresses (a) the need to prune the candidate set to a tractable size, (b) the multi‑objective nature of the problem (response time, storage budget, maintenance cost), and (c) the inter‑dependencies among indexes and MVs (e.g., redundancy, overlapping coverage).
The core contribution of the paper is a hybrid heuristic that combines association‑rule mining (Apriori) with clustering (K‑means) to produce a compact, high‑impact set of candidate indexes and MVs. The process consists of four steps: (i) parsing a representative query workload to extract all columns appearing in SELECT, WHERE, GROUP BY, and JOIN predicates, as well as the aggregate functions used; (ii) applying Apriori with a user‑defined minimum support to discover frequent itemsets of columns that co‑occur across queries; (iii) clustering the frequent itemsets to group together patterns with similar access frequencies and cost characteristics, thereby allowing a single representative candidate to stand for each cluster; and (iv) evaluating each representative using a multi‑objective objective function that linearly combines (1) estimated reduction in average query response time, (2) storage consumption, and (3) maintenance overhead (e.g., index rebuild frequency). The objective function’s weights are configurable, enabling administrators to prioritize storage savings or performance gains as needed. After scoring, a final pruning phase removes redundant candidates (e.g., two indexes covering the same column set) and resolves conflicts between indexes and MVs to avoid unnecessary duplication.
Experimental validation is performed on a 1‑TB TPC‑DS‑derived data warehouse with a workload of 100 complex OLAP queries. The authors compare four configurations: (a) a traditional cost‑based optimizer, (b) a genetic‑algorithm‑based selector, (c) a pure association‑rule selector, and (d) the proposed hybrid heuristic. The results show that the hybrid approach reduces candidate generation time by roughly 30 % relative to the cost‑based method, cuts the final number of selected objects by about 45 %, and achieves an average query response‑time improvement of 15 % while keeping storage usage below 20 % of the total warehouse size. Moreover, the approach exhibits stable performance across different workload mixes, indicating robustness to variations in query patterns.
The discussion section acknowledges several limitations and outlines future research directions. First, the current heuristic assumes a static workload; extending it to handle dynamic, streaming query logs would require incremental mining techniques and online re‑optimization. Second, the cost model does not fully capture the economics of cloud‑based warehouses where compute and storage are billed separately and can be elastically scaled; integrating a cloud‑cost model is an open challenge. Third, the authors suggest exploring reinforcement‑learning agents that could learn selection policies directly from performance feedback, potentially surpassing handcrafted objective functions. Finally, they advocate for a unified physical design framework that simultaneously considers indexing, materialization, partitioning, and column‑store transformations, as these decisions are tightly coupled in modern analytical platforms.
In conclusion, the paper demonstrates that a data‑mining‑driven heuristic can effectively shrink the search space for index and MV selection while delivering measurable performance gains. By coupling frequent‑pattern mining with clustering and a configurable multi‑objective evaluation, the method balances response‑time improvement against storage and maintenance constraints. The authors’ experimental evidence supports the claim that their approach outperforms traditional cost‑based and evolutionary methods in both efficiency and effectiveness, and they provide a clear roadmap for extending the technique to adaptive, cloud‑aware, and fully integrated physical design environments.