Dynamic time warping distance for message propagation classification in Twitter
Social messages classification is a research domain that has attracted the attention of many researchers in these last years. Indeed, the social message is different from ordinary text because it has some special characteristics like its shortness. Then the development of new approaches for the processing of the social message is now essential to make its classification more efficient. In this paper, we are mainly interested in the classification of social messages based on their spreading on online social networks (OSN). We proposed a new distance metric based on the Dynamic Time Warping distance and we use it with the probabilistic and the evidential k Nearest Neighbors (k-NN) classifiers to classify propagation networks (PrNets) of messages. The propagation network is a directed acyclic graph (DAG) that is used to record propagation traces of the message, the traversed links and their types. We tested the proposed metric with the chosen k-NN classifiers on real world propagation traces that were collected from Twitter social network and we got good classification accuracies.
💡 Research Summary
**
The paper addresses the problem of classifying short social media messages, specifically tweets, by exploiting the way these messages spread through the network rather than relying on their textual content. Traditional text‑based classifiers (e.g., bag‑of‑words, TF‑IDF, SVM) perform poorly on micro‑blogging platforms because the limited character count yields sparse word statistics, and preprocessing often removes most of the remaining tokens. To overcome this limitation, the authors model each message’s diffusion as a Propagation Network (PrNet), a directed acyclic graph (DAG) whose nodes are Twitter users and whose edges represent three possible interaction types: follow, mention, and retweet. Each edge is assigned a weight vector (w_f, w_m, w_r) reflecting the strength of the corresponding interaction.
Previous work on PrNet classification transformed the graph into probability distributions or Basic Belief Assignments (BBA) and then applied simple distances such as Euclidean or Jaccard. This transformation discards the temporal ordering of events and can cause significant information loss, especially when the timing of propagation is discriminative. The authors therefore propose a novel distance metric, PrNet‑DTW, which adapts Dynamic Time Warping (DTW) – originally designed for time‑series alignment – to the graph domain.
The construction of PrNet‑DTW proceeds in two steps. First, each PrNet is decomposed into a set of dipaths: directed paths that start at the source node and follow a single branch to a leaf. Because dipaths preserve the chronological order of user interactions, they can be treated as sequences. Second, for every dipath in the first PrNet, the algorithm computes DTW distances to all dipaths in the second PrNet, selects the minimal distance for that dipath, and finally averages these minima across all dipaths of the first PrNet. Memoization reduces the computational complexity to O(|S|·|T|), where |S| and |T| are the lengths of the two sequences being compared.
Having defined a distance between propagation graphs, the authors employ two distance‑based classifiers. The first is the classic probabilistic k‑Nearest Neighbors (k‑NN), which assigns a class by majority vote among the k closest training examples. The second is an evidential k‑NN that operates within the Dempster‑Shafer theory of belief functions. For each neighbor j, a confidence parameter α_j is derived from its distance d_j using α_j = α_0·exp(−γ·d_j^β). This α_j determines a BBA that allocates mass to the singleton class of the neighbor and the remaining mass to ignorance. All BBAs are combined using a chosen combination rule (e.g., conjunctive), then transformed to a pignistic probability distribution, and the class with the highest pignistic probability is selected. This approach explicitly models the uncertainty associated with each neighbor’s distance.
The experimental evaluation uses a real‑world Twitter dataset collected via the Twitter4j API between September 8 and November 3, 2014. After cleaning, the dataset contains tweets belonging to three topical classes: “Android”, “Galaxy”, and “Windows”. A tweet is considered to belong to a class if it contains the corresponding keyword. Propagation traces are extracted under three conditions: (1) the follower relationship, (2) a mention of the target user, and (3) a retweet of the source tweet. Each condition contributes to the edge weight vector. The resulting PrNets comprise thousands of nodes and edges per class.
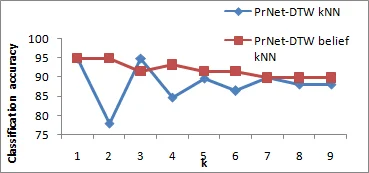
The authors compare four configurations: (i) Euclidean distance + probabilistic k‑NN, (ii) Jaccard distance + probabilistic k‑NN, (iii) PrNet‑DTW + probabilistic k‑NN, and (iv) PrNet‑DTW + evidential k‑NN. Results show that the DTW‑based distance consistently outperforms the baseline distances. The best performance is achieved with PrNet‑DTW combined with evidential k‑NN, reaching an average classification accuracy of about 84 %, which is roughly 5–7 percentage points higher than the best baseline. Notably, the DTW metric captures subtle timing differences in diffusion patterns, enabling the classifier to distinguish between classes that have similar structural propagation but differ in speed or order of spread.
The paper also discusses limitations. Computing DTW for all dipath pairs can become expensive when the number of dipaths grows, suggesting future work on path sampling, clustering, or embedding techniques to reduce dimensionality. The edge weight vectors are manually set based on domain knowledge; learning these weights automatically (e.g., via gradient‑based optimization) could improve adaptability. Finally, while the study focuses on Twitter, the methodology is applicable to other social platforms where diffusion can be represented as weighted, time‑dependent DAGs.
In conclusion, the authors present a compelling alternative to text‑centric classification by leveraging propagation dynamics. By adapting Dynamic Time Warping to directed acyclic propagation graphs and integrating it with both probabilistic and evidential k‑NN classifiers, they achieve superior classification performance on real Twitter data. This work opens avenues for network‑driven content analysis, including spam detection, rumor tracking, and targeted marketing, especially in scenarios where textual content is unavailable, heavily censored, or too sparse for conventional natural‑language processing techniques.
Comments & Academic Discussion
Loading comments...
Leave a Comment