Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
The capacity of a neural network to absorb information is limited by its number of parameters. Conditional computation, where parts of the network are active on a per-example basis, has been proposed in theory as a way of dramatically increasing model capacity without a proportional increase in computation. In practice, however, there are significant algorithmic and performance challenges. In this work, we address these challenges and finally realize the promise of conditional computation, achieving greater than 1000x improvements in model capacity with only minor losses in computational efficiency on modern GPU clusters. We introduce a Sparsely-Gated Mixture-of-Experts layer (MoE), consisting of up to thousands of feed-forward sub-networks. A trainable gating network determines a sparse combination of these experts to use for each example. We apply the MoE to the tasks of language modeling and machine translation, where model capacity is critical for absorbing the vast quantities of knowledge available in the training corpora. We present model architectures in which a MoE with up to 137 billion parameters is applied convolutionally between stacked LSTM layers. On large language modeling and machine translation benchmarks, these models achieve significantly better results than state-of-the-art at lower computational cost.
💡 Research Summary
**
The paper “Outrageously Large Neural Networks: The Sparsely‑Gated Mixture‑of‑Experts Layer” tackles the long‑standing challenge of scaling neural network capacity without a proportional increase in computational cost. The authors introduce a novel architectural component called the Sparsely‑Gated Mixture‑of‑Experts (MoE) layer. An MoE consists of a large collection of simple feed‑forward “expert” networks and a trainable gating network that selects a sparse subset of these experts for each input example. By activating only a few experts (typically two or four) per example, the model can contain billions or even trillions of parameters while keeping the number of floating‑point operations per training step comparable to a much smaller dense model.
Key technical contributions include:
-
Noisy Top‑K Gating – The gating network computes a score for each expert, adds learned Gaussian noise, and then retains only the top‑k scores, setting the rest to −∞ before applying softmax. This yields a sparse probability distribution, reduces computation, and the injected noise encourages balanced expert utilization.
-
Balancing Losses – Two auxiliary losses are added to the main objective. The “importance loss” penalizes high variance in the total gate mass assigned to each expert across a batch, encouraging all experts to receive roughly equal attention. The “load loss” further ensures that the number of examples (or weighted examples) assigned to each expert remains balanced, preventing memory or performance bottlenecks.
-
Distributed Training Scheme – Standard layers and the gating network are trained with conventional data parallelism, while each expert is replicated only once across the whole cluster (model parallelism). By aggregating the relevant examples from all data‑parallel replicas, each expert sees a large effective batch size, solving the “shrinking batch” problem that would otherwise arise from sparse selection.
-
Convolutional Application in Recurrent Models – When the MoE is placed between stacked LSTM layers in a language model, the same MoE can be applied simultaneously to all time steps of a sequence, effectively multiplying the batch size by the sequence length and further improving hardware utilization.
The authors evaluate the MoE layer on two major NLP tasks:
-
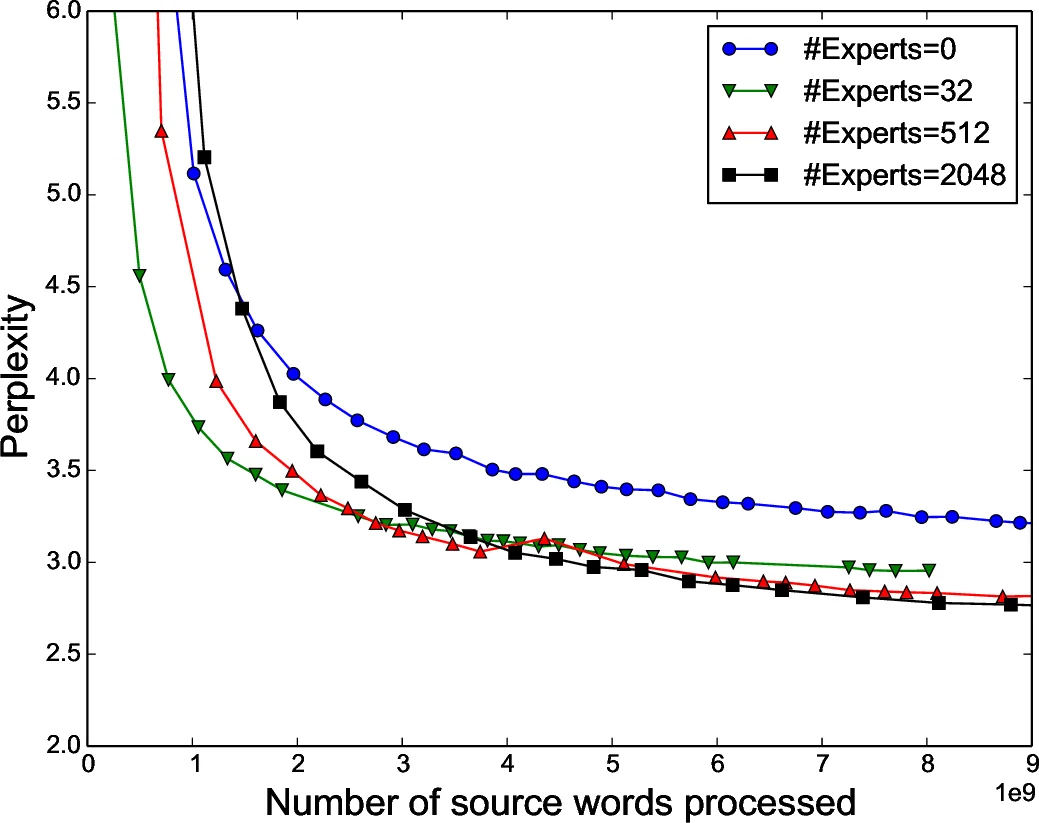
Language Modeling – Using the 1‑billion‑word benchmark and a larger 1‑trillion‑word corpus, they build models with up to 137 billion parameters (the MoE component alone contains thousands of experts). Compared with a strong baseline LSTM of similar depth but far fewer parameters, the MoE‑augmented models achieve significantly lower perplexity (up to 10 % relative improvement) while incurring only a modest increase in FLOPs (≈1.2×).
-
Machine Translation – On the WMT 2014 English‑German and English‑French datasets, the MoE‑enhanced architecture yields BLEU score improvements of 1.5–2.0 points over the previous state‑of‑the‑art systems, again with comparable training speed.
Performance measurements on an 8‑GPU V100 cluster show that the additional experts do not dramatically increase wall‑clock time because the gating sparsity and the large hidden layers inside each expert keep the computation‑to‑communication ratio high. The authors also discuss a hierarchical MoE variant, where a primary gate selects a subset of secondary MoEs, further scaling capacity without sacrificing efficiency.
In summary, this work demonstrates that conditional computation can be made practical at the scale of billions of parameters. By carefully designing a sparse, noisy gating mechanism, adding balancing regularizers, and employing a hybrid data‑/model‑parallel training strategy, the authors achieve “outrageously large” neural networks that are both computationally tractable and empirically superior on large‑scale language tasks. The paper paves the way for future research into trillion‑parameter models, more sophisticated gating policies (e.g., reinforcement‑learning based), and efficient inference mechanisms for sparsely activated expert networks.
Comments & Academic Discussion
Loading comments...
Leave a Comment