Learning to reinforcement learn
In recent years deep reinforcement learning (RL) systems have attained superhuman performance in a number of challenging task domains. However, a major limitation of such applications is their demand for massive amounts of training data. A critical p…
Authors: Jane X Wang, Zeb Kurth-Nelson, Dhruva Tirumala
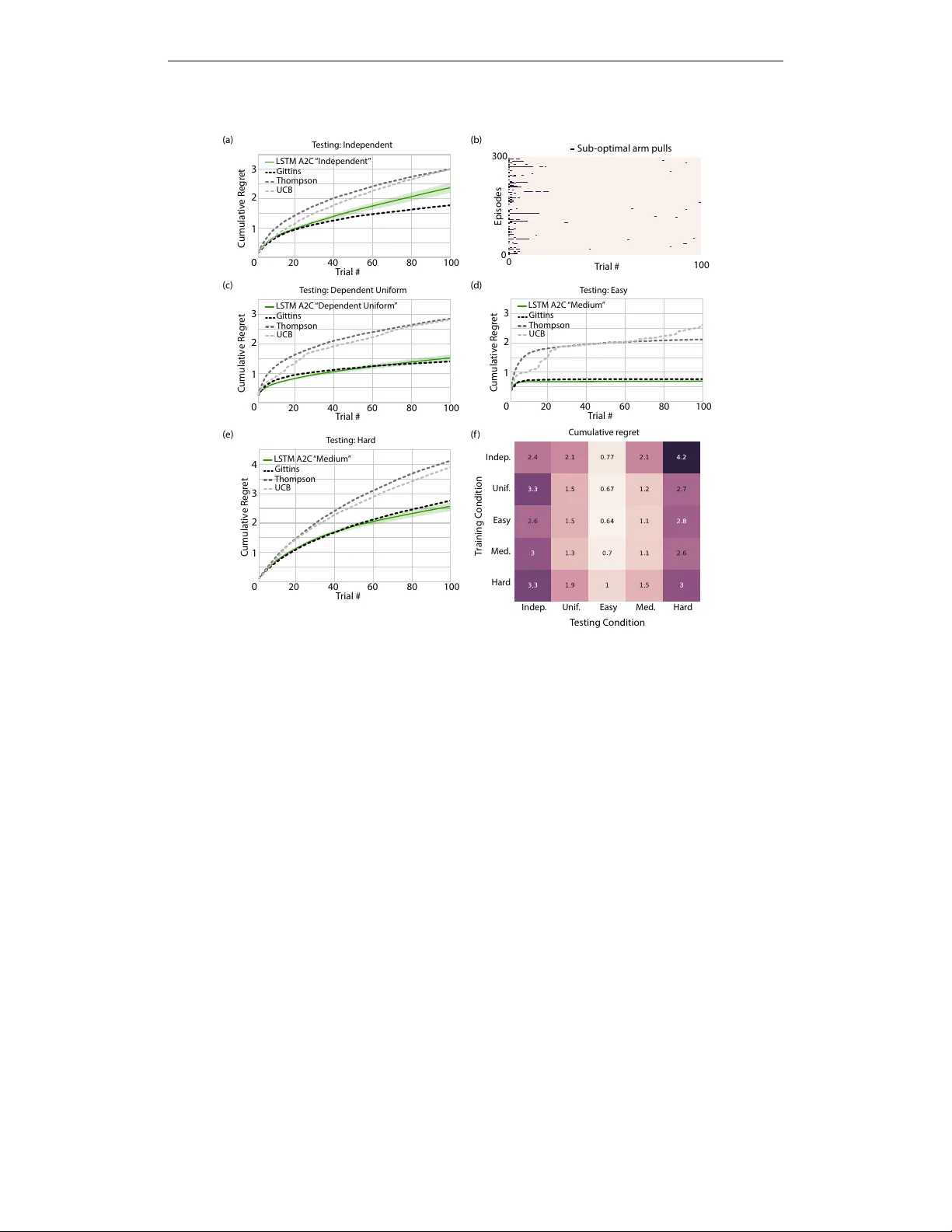
L E A R N I N G T O R E I N F O R C E M E N T L E A R N JX W ang 1 , Z Kurth-Nelson 1 , D Tirumala 1 , H Soyer 1 , JZ Leibo 1 , R Munos 1 , C Blundell 1 , D Kumaran 1 , 3 , M Botvinick 1 , 2 1 DeepMind, London, UK 2 Gatsby Computational Neuroscience Unit, UCL, London, UK 3 Institute of Cognitiv e Neuroscience, UCL, London, UK {wangjane, zebk, dhruvat, soyer, jzl, munos, cblundell, dkumaran, botvinick} @google.com A B S T R AC T In recent years deep reinforcement learning (RL) systems have attained superhuman performance in a number of challenging task domains. Howe ver , a major limitation of such applications is their demand for massi ve amounts of training data. A critical present objectiv e is thus to de velop deep RL methods that can adapt rapidly to new tasks. In the present work we introduce a nov el approach to this challenge, which we refer to as deep meta-reinforcement learning. Previous work has shown that recurrent networks can support meta-learning in a fully supervised conte xt. W e extend this approach to the RL setting. What emerges is a system that is trained using one RL algorithm, but whose recurrent dynamics implement a second, quite separate RL procedure. This second, learned RL algorithm can differ from the original one in arbitrary w ays. Importantly , because it is learned, it is configured to exploit structure in the training domain. W e unpack these points in a series of sev en proof-of-concept experiments, each of which examines a ke y aspect of deep meta-RL. W e consider prospects for extending and scaling up the approach, and also point out some potentially important implications for neuroscience. 1 I N T RO D U C T I O N Recent adv ances ha ve allo wed long-standing methods for reinforcement learning (RL) to be ne wly extended to such complex and large-scale task environments as Atari (Mnih et al., 2015) and Go (Silver et al., 2016). The key enabling breakthrough has been the de velopment of techniques allo wing the stable integration of RL with non-linear function approximation through deep learning (LeCun et al., 2015; Mnih et al., 2015). The resulting deep RL methods are attaining human- and often superhuman-lev el performance in an expanding list of domains (Jaderberg et al., 2016; Mnih et al., 2015; Silver et al., 2016). Howe ver , there are at least two aspects of human performance that the y starkly lack. First, deep RL typically requires a massive volume of training data, whereas human learners can attain reasonable performance on any of a wide range of tasks with comparativ ely little experience. Second, deep RL systems typically specialize on one restricted task domain, whereas human learners can flexibly adapt to changing task conditions. Recent critiques (e.g., Lake et al., 2016) hav e inv oked these differences as posing a direct challenge to current deep RL research. In the present work, we outline a framew ork for meeting these challenges, which we refer to as deep meta-reinfor cement learning , a label that is intended to both link it with and distinguish it from previous work employing the term “meta-reinforcement learning” (e.g. Schmidhuber et al., 1996; Schweighofer and Doya, 2003, discussed later). The key concept is to use standard deep RL techniques to train a recurrent neural network in such a way that the recurrent network comes to implement its own, free-standing RL procedure. As we shall illustrate, under the right circumstances, the secondary learned RL procedure can display an adaptiv eness and sample efficiency that the original RL procedure lacks. The following sections re view pre vious work employing recurrent neural networks in the conte xt of meta-learning and describe the general approach for e xtending such methods to the RL setting. W e 1 then present sev en proof-of-concept experiments, each of which highlights an important ramification of the deep meta-RL setup by characterizing agent performance in light of this framew ork. W e close with a discussion of key challenges for next-step research, as well as some potential implications for neuroscience. 2 M E T H O D S 2 . 1 B A CK G RO U N D : M E TA - L E A R N I N G I N R E C U R R E N T N E U R A L N E T W O R K S Flexible, data-efficient learning naturally requires the operation of prior biases. In general terms, such biases can deriv e from two sources; they can either be engineered into the learning system (as, for example, in con volutional netw orks), or they can themselves be acquired through learning. The second case has been e xplored in the machine learning literature under the rubric of meta-learning (Schmidhuber et al., 1996; Thrun and Pratt, 1998). In one standard setup, the learning agent is confronted with a series of tasks that differ from one another but also share some underlying set of regularities. Meta-learning is then defined as an effect whereby the agent improv es its performance in each new task more rapidly , on av erage, than in past tasks (Thrun and Pratt, 1998). At an architectural level, meta-learning has generally been conceptualized as inv olving two learning systems: one lower -level system that learns relativ ely quickly , and which is primarily responsible for adapting to each new task; and a slo wer higher-le vel system that works across tasks to tune and improv e the lower -le vel system. A variety of methods hav e been pursued to implement this basic meta-learning setup, both within the deep learning community and beyond (Thrun and Pratt, 1998). Of particular relevance here is an approach introduced by Hochreiter and colleagues (Hochreiter et al., 2001), in which a recurrent neural network is trained on a series of interrelated tasks using standard backpropagation. A critical aspect of their setup is that the network receiv es, on each step within a task, an auxiliary input indicating the target output for the preceding step. For e xample, in a regression task, on each step the network recei ves as input an x v alue for which it is desired to output the corresponding y , but the network also receiv es an input disclosing the target y value for the preceding step (see Hochreiter et al., 2001; Santoro et al., 2016). In this scenario, a dif ferent function is used to generate the data in each training episode, b ut if the functions are all drawn from a single parametric family , then the system gradually tunes into this consistent structure, con ver ging on accurate outputs more and more rapidly across episodes. One interesting aspect of Hochreiter’ s method is that the process that underlies learning within each ne w task inheres entirely in the dynamics of the recurrent network, rather than in the backpropag ation procedure used to tune that netw ork’ s weights. Indeed, after an initial training period, the network can improve its performance on new tasks even if the weights are held constant (see also Cotter and Conwell, 1990; Prokhorov et al., 2002; Y ounger et al., 1999). A second important aspect of the approach is that the learning procedure implemented in the recurrent network is fit to the structure that spans the family of tasks on which the network is trained, embedding biases that allow it to learn efficiently when dealing with tasks from that f amily . 2 . 2 D E E P M E TA - R L : D E FI N I T I O N A N D K E Y F E AT U R E S Importantly , Hochreiter’ s original work (Hochreiter et al., 2001), as well as its subsequent extensions (Cotter and Conwell, 1990; Prokhoro v et al., 2002; Santoro et al., 2016; Y ounger et al., 1999) only addressed supervised learning (i.e. the auxiliary input provided on each step explicitly indicated the target output on the pre vious step, and the network was trained using explicit tar gets). In the present work we consider the implications of applying the same approach in the context of reinforcement learning. Here, the tasks that make up the training series are interrelated RL problems, for example, a series of bandit problems varying only in their parameterization. Rather than presenting target outputs as auxiliary inputs, the agent receiv es inputs indicating the action output on the previous step and, critically , the quantity of re ward resulting from that action. The same rew ard information is fed in parallel to a deep RL procedure, which tunes the weights of the recurrent network. It is this setup, as well as its result, that we refer to as deep meta-RL (although from here on, for brevity , we will often simply call it meta-RL, with apologies to authors who hav e used that term 2 pre viously). As in the supervised case, when the approach is successful, the dynamics of the recurrent network come to implement a learning algorithm entirely separate from the one used to train the network weights. Once again, after sufficient training, learning can occur within each task even if the weights are held constant. Howe ver , here the procedure the recurrent network implements is itself a full-fledged reinforcement learning algorithm, which negotiates the exploration-e xploitation tradeof f and improv es the agent’ s policy based on reward outcomes. A key point, which we will emphasize in what follows, is that this learned RL procedure can differ starkly from the algorithm used to train the network’ s weights. In particular , its policy update procedure (including features such as the ef fecti ve learning rate of that procedure), can dif fer dramatically from those in volved in tuning the network weights, and the learned RL procedure can implement its own approach to e xploration. Critically , as in the supervised case, the learned RL procedure will be fit to the statistics spanning the multi-task en vironment, allowing it to adapt rapidly to ne w task instances. 2 . 3 F O R M A L I S M Let us write as D a distribution (the prior) over Markov Decision Processes (MDPs). W e want to demonstrate that meta-RL is able to learn a prior -dependent RL algorithm, in the sense that it will perform well on av erage on MDPs drawn from D or slight modifications of D . An appropriately structured agent, embedding a recurrent neural network, is trained by interacting with a sequence of MDP en vironments (also called tasks) through episodes. At the start of a new episode, a ne w MDP task m ∼ D and an initial state for this task are sampled, and the internal state of the agent (i.e., the pattern of activ ation over its recurrent units) is reset. The agent then executes its action-selection strategy in this environment for a certain number of discrete time-steps. At each step t an action a t ∈ A is executed as a function of the whole history H t = { x 0 , a 0 , r 0 , . . . , x t − 1 , a t − 1 , r t − 1 , x t } of the agent interacting in the MDP m during the current episode (set of states { x s } 0 ≤ s ≤ t , actions { a s } 0 ≤ s
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment