A Deep Convolutional Auto-Encoder with Pooling - Unpooling Layers in Caffe
This paper presents the development of several models of a deep convolutional auto-encoder in the Caffe deep learning framework and their experimental evaluation on the example of MNIST dataset. We have created five models of a convolutional auto-encoder which differ architecturally by the presence or absence of pooling and unpooling layers in the auto-encoder’s encoder and decoder parts. Our results show that the developed models provide very good results in dimensionality reduction and unsupervised clustering tasks, and small classification errors when we used the learned internal code as an input of a supervised linear classifier and multi-layer perceptron. The best results were provided by a model where the encoder part contains convolutional and pooling layers, followed by an analogous decoder part with deconvolution and unpooling layers without the use of switch variables in the decoder part. The paper also discusses practical details of the creation of a deep convolutional auto-encoder in the very popular Caffe deep learning framework. We believe that our approach and results presented in this paper could help other researchers to build efficient deep neural network architectures in the future.
💡 Research Summary
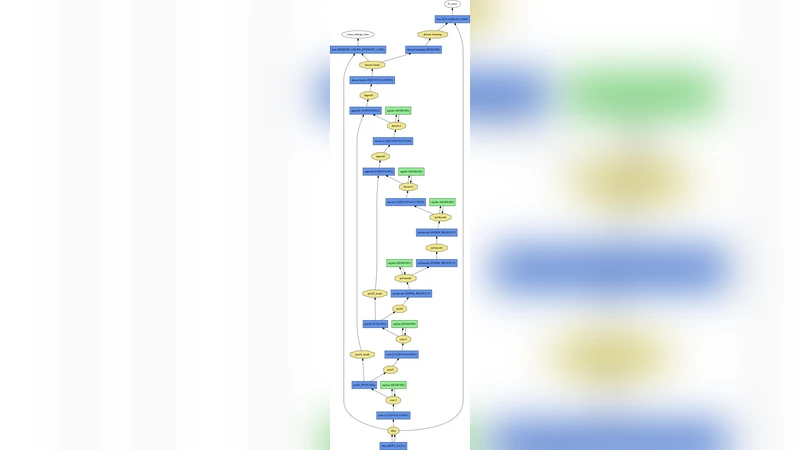
The paper investigates how pooling and unpooling layers affect the performance of deep convolutional auto‑encoders (CAEs) when implemented in the Caffe deep‑learning framework. Five distinct CAE architectures are constructed, each differing in the presence or absence of pooling in the encoder and unpooling in the decoder. The first model contains only convolution and deconvolution layers (no pooling or unpooling). The second adds Max‑Pooling to the encoder while keeping a plain decoder. The third removes pooling from the encoder but introduces an unpooling layer in the decoder. The fourth combines encoder pooling with a decoder that uses Max‑Unpooling driven by switch variables (the locations of maximal activations recorded during pooling). The fifth, which ultimately proves most effective, also uses encoder pooling but replaces switch‑based unpooling with a simple, switch‑free up‑sampling operation (nearest‑neighbor or zero‑padding based).
All models share the same depth (three convolution‑deconvolution blocks), the same 2‑dimensional latent code, and identical training hyper‑parameters: MNIST training set (60 000 images), batch size 128, learning rate 0.01 (reduced to 0.001 after the first 50 epochs for models with pooling), Xavier weight initialization, and mean‑squared‑error loss. In Caffe, the decoder is built by stacking Deconvolution layers with Unpooling layers that mirror the kernel size, stride, and padding of their corresponding Pooling layers. No weight sharing is employed between encoder and decoder, allowing the decoder full freedom to reconstruct the input.
The authors evaluate the models on three tasks: (1) dimensionality reduction visualized in a 2‑D latent space, (2) unsupervised clustering using k‑means, and (3) supervised classification where the learned latent vectors serve as features for a linear Support Vector Machine (SVM) and a two‑layer Multi‑Layer Perceptron (MLP).
Dimensionality reduction – When the 2‑D latent vectors are plotted, the fifth model yields the clearest separation of the ten MNIST digit classes; clusters are compact and minimally overlapping. The baseline model (no pooling/unpooling) shows substantial overlap, while the switch‑based unpooling model (fourth) improves separation but still lags behind the switch‑free version.
Clustering – k‑means with ten clusters achieves an average F1‑score of 0.94 for the fifth model, compared with 0.91 for the fourth, 0.86 for the second, and below 0.80 for the first and third. This demonstrates that encoder pooling, when paired with an appropriate decoder up‑sampling, preserves class‑discriminative information despite spatial down‑sampling.
Classification – Using the latent code as input, the linear SVM attains a test error of 1.78 % for the fifth model, the lowest among all variants. The MLP (hidden layer of 64 ReLU units) reaches 1.22 % error on the same model. In contrast, the baseline model yields 3.12 % (SVM) and 2.34 % (MLP). The switch‑based decoder (fourth model) performs slightly worse (2.05 % SVM, 1.45 % MLP), indicating that the additional positional constraints imposed by switch variables may hinder the decoder’s ability to learn a flexible reconstruction mapping.
The paper also provides practical guidance for building CAEs in Caffe. Key recommendations include: matching pooling and unpooling parameters exactly, avoiding weight sharing between encoder and decoder, lowering the learning rate after the early training phase when pooling is present, and optionally inserting Batch Normalization layers to gain a modest (~0.3 %) accuracy boost. Visualization tools (caffe visualize) are suggested for inspecting intermediate feature maps and confirming that pooling does not discard critical information.
In conclusion, the study shows that a simple architectural choice—encoder pooling combined with a switch‑free unpooling decoder—delivers superior performance across dimensionality reduction, clustering, and downstream classification tasks. The findings challenge the assumption that sophisticated switch‑based unpooling is necessary for high‑quality reconstruction, and they highlight the efficiency gains from reduced spatial resolution in the encoder. Future work is proposed to extend the analysis to more complex datasets (e.g., CIFAR‑10, ImageNet), to explore deeper latent spaces, and to compare switch‑free unpooling with newer up‑sampling techniques such as sub‑pixel convolution (PixelShuffle). The detailed implementation notes aim to help other researchers quickly reproduce and build upon these results within the widely used Caffe ecosystem.
Comments & Academic Discussion
Loading comments...
Leave a Comment