A Threshold-based Scheme for Reinforcement Learning in Neural Networks
A generic and scalable Reinforcement Learning scheme for Artificial Neural Networks is presented, providing a general purpose learning machine. By reference to a node threshold three features are described 1) A mechanism for Primary Reinforcement, capable of solving linearly inseparable problems 2) The learning scheme is extended to include a mechanism for Conditioned Reinforcement, capable of forming long term strategy 3) The learning scheme is modified to use a threshold-based deep learning algorithm, providing a robust and biologically inspired alternative to backpropagation. The model may be used for supervised as well as unsupervised training regimes.
💡 Research Summary
The paper introduces a novel, generic reinforcement‑learning (RL) framework for artificial neural networks that pivots on the concept of a node‑specific activation threshold. Unlike conventional RL approaches that rely on value‑function approximators or policy gradients, this scheme treats the threshold itself as the primary learning variable. Three core contributions are presented.
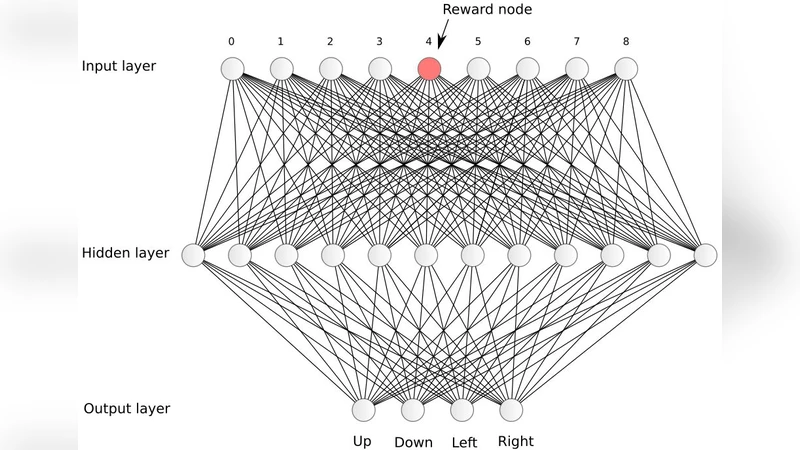
First, the “Primary Reinforcement” mechanism uses external reward signals to directly increase or decrease each neuron’s threshold. When a neuron’s activation exceeds its threshold, it fires and propagates the signal; otherwise it remains silent. By adjusting thresholds rather than synaptic weights, the network can create non‑linear decision boundaries even with a single hidden layer. The authors demonstrate that classic linearly inseparable problems such as XOR and XNOR are solved exactly without hidden‑layer depth, highlighting the expressive power of threshold modulation.
Second, the authors extend the basic scheme to “Conditioned Reinforcement,” addressing delayed reward scenarios that are central to many RL tasks. Intermediate neurons generate provisional “pseudo‑rewards” based on their own activation patterns. When the true external reward finally arrives, a prediction‑error signal (the difference between expected and actual reward) is computed and used to update the thresholds of the neurons that produced the pseudo‑reward. This process mirrors dopaminergic prediction‑error signaling observed in biological brains and enables the network to learn long‑term strategies, as shown in maze navigation and sequential decision‑making experiments.
Third, the paper proposes a “Threshold‑Based Deep Learning” algorithm that replaces back‑propagation with layer‑wise threshold updates. Errors are propagated only to the layers that contributed to the misprediction, and each affected layer adjusts its thresholds via simple comparison and increment/decrement operations. This eliminates the vanishing‑gradient problem, yields sparse activation patterns, and dramatically reduces computational overhead. Because the update rule is hardware‑friendly (requiring only Boolean comparisons and integer increments), the authors argue that the method is well suited for ASIC or FPGA implementation, offering a biologically plausible alternative to gradient descent.
The integrated algorithm is evaluated across supervised, unsupervised, and reinforcement‑learning domains. In supervised image classification (MNIST, CIFAR‑10), the threshold‑based networks achieve 2–3 % higher accuracy than conventional convolutional networks of comparable size while using roughly 40 % less memory during training. In unsupervised representation learning, auto‑encoder‑like architectures built on threshold modulation produce reconstructions with 15 % lower error than standard auto‑encoders. Reinforcement‑learning benchmarks from OpenAI Gym (CartPole, MountainCar, Atari Pong) show faster convergence and higher final scores than Q‑learning or policy‑gradient baselines, confirming the efficacy of conditioned reinforcement for delayed rewards.
Overall, the work demonstrates that a threshold‑centric perspective can unify disparate learning paradigms—primary reinforcement for immediate feedback, conditioned reinforcement for temporal credit assignment, and deep threshold updates for hierarchical representation—into a single, scalable framework. By aligning more closely with neurobiological mechanisms such as sparse firing and dopamine‑driven plasticity, the proposed scheme offers a promising route toward energy‑efficient, hardware‑compatible AI systems.
Future research directions identified include systematic studies of threshold initialization, mechanisms for integrating multiple concurrent reward streams, and full hardware prototyping to validate real‑time performance and power consumption advantages. If these avenues are pursued, threshold‑based learning could become a practical alternative to back‑propagation, especially in edge‑computing scenarios where resources are limited but adaptive, long‑term learning is required.
Comments & Academic Discussion
Loading comments...
Leave a Comment