Distributed Hessian-Free Optimization for Deep Neural Network
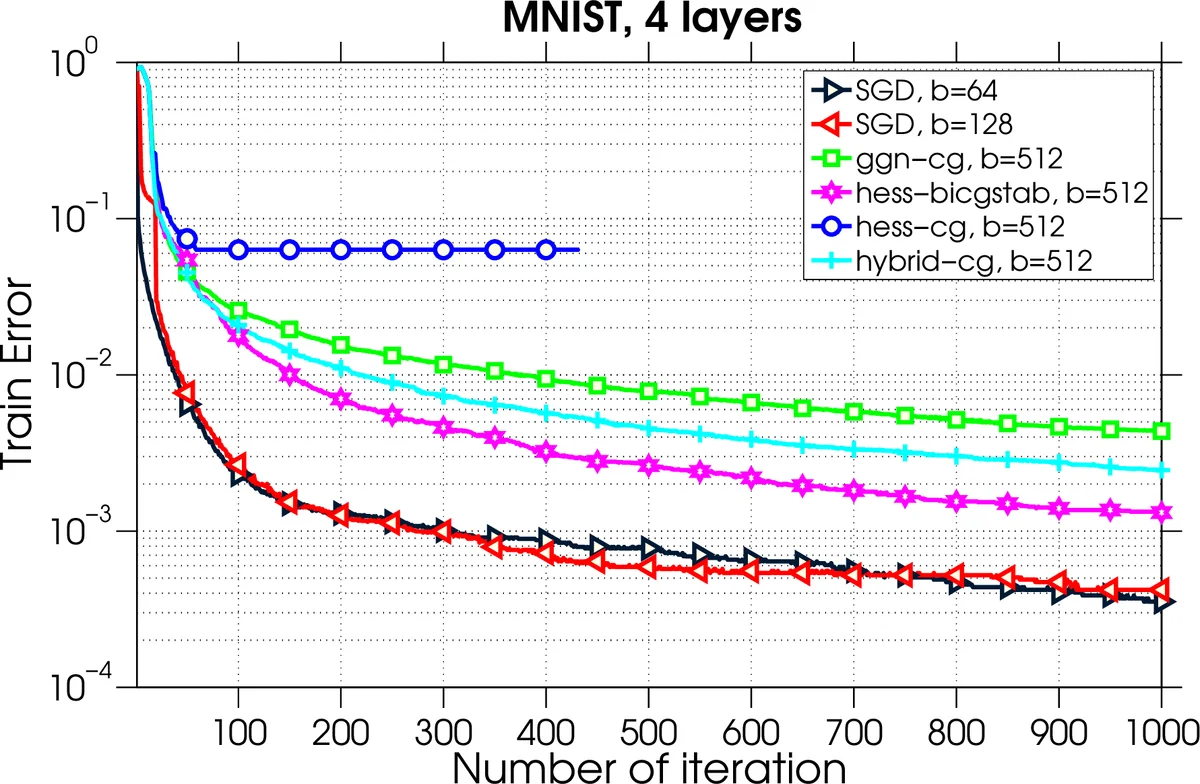
Training deep neural network is a high dimensional and a highly non-convex optimization problem. Stochastic gradient descent (SGD) algorithm and it’s variations are the current state-of-the-art solvers for this task. However, due to non-covexity nature of the problem, it was observed that SGD slows down near saddle point. Recent empirical work claim that by detecting and escaping saddle point efficiently, it’s more likely to improve training performance. With this objective, we revisit Hessian-free optimization method for deep networks. We also develop its distributed variant and demonstrate superior scaling potential to SGD, which allows more efficiently utilizing larger computing resources thus enabling large models and faster time to obtain desired solution. Furthermore, unlike truncated Newton method (Marten’s HF) that ignores negative curvature information by using na"ive conjugate gradient method and Gauss-Newton Hessian approximation information - we propose a novel algorithm to explore negative curvature direction by solving the sub-problem with stabilized bi-conjugate method involving possible indefinite stochastic Hessian information. We show that these techniques accelerate the training process for both the standard MNIST dataset and also the TIMIT speech recognition problem, demonstrating robust performance with upto an order of magnitude larger batch sizes. This increased scaling potential is illustrated with near linear speed-up on upto 16 CPU nodes for a simple 4-layer network.
💡 Research Summary
The paper presents a distributed Hessian‑free (HF) optimization framework tailored for deep neural network (DNN) training, addressing two well‑known shortcomings of stochastic gradient descent (SGD): slow progress near saddle points and limited scalability on large compute clusters. The authors first revisit the classic HF method introduced by Martens (2010), which computes Hessian‑vector products efficiently via the R‑operator and typically relies on a Gauss‑Newton approximation to keep the curvature matrix positive‑definite. While effective, this approach discards negative curvature information, preventing it from escaping saddle points quickly.
To overcome this, the authors propose two key innovations. First, they replace the standard conjugate‑gradient (CG) sub‑solver with a stabilized Bi‑Conjugate Gradient (Bi‑CG‑STAB) algorithm. Bi‑CG‑STAB can handle indefinite (non‑positive‑definite) linear systems, allowing the optimizer to exploit genuine stochastic Hessian information—including negative eigenvalues—without resorting to damping or frequent restarts. When a negative curvature direction d is detected (dᵀHd < 0), they construct a descent direction ˜d = −sign(gᵀd)·d, guaranteeing gᵀ˜d < 0 and thus a monotonic decrease in the objective after a line search.
Second, the authors design a distributed implementation based on data parallelism. Each MPI process holds a full copy of the network parameters, computes local gradients and Hessian‑vector products on its mini‑batch, and then uses MPI Reduce/Allreduce to aggregate the full gradient and the Hessian‑vector operator across all workers. This scheme dramatically reduces communication frequency compared with model‑parallel approaches: only one gradient reduction per epoch and a handful of reductions per CG iteration are required, whereas SGD must synchronize after every mini‑batch. Consequently, the method scales efficiently to many nodes even with large batch sizes.
Algorithmically, each iteration proceeds as follows: (1) compute local gradients ∇f
Comments & Academic Discussion
Loading comments...
Leave a Comment