A Multifaceted Evaluation of Neural versus Phrase-Based Machine Translation for 9 Language Directions
We aim to shed light on the strengths and weaknesses of the newly introduced neural machine translation paradigm. To that end, we conduct a multifaceted evaluation in which we compare outputs produced by state-of-the-art neural machine translation and phrase-based machine translation systems for 9 language directions across a number of dimensions. Specifically, we measure the similarity of the outputs, their fluency and amount of reordering, the effect of sentence length and performance across different error categories. We find out that translations produced by neural machine translation systems are considerably different, more fluent and more accurate in terms of word order compared to those produced by phrase-based systems. Neural machine translation systems are also more accurate at producing inflected forms, but they perform poorly when translating very long sentences.
💡 Research Summary
The paper presents a comprehensive, multilingual evaluation of state‑of‑the‑art neural machine translation (NMT) versus phrase‑based machine translation (PBMT) systems using the best submissions to the WMT16 news translation task. Nine language directions are examined (English↔Czech, German, Finnish, Romanian, Russian). The authors address six research questions: output similarity, fluency, monotonicity, word‑order quality, sentence‑length effects, and error‑type performance (inflectional, reordering, lexical).
First, output similarity is measured with the chrF1 metric across the top NMT and PBMT systems for each direction. Pairwise overlaps reveal that NMT outputs are considerably more variable than PBMT outputs (lower NMT‑NMT overlap) and that NMT‑PBMT overlap is the lowest of all, indicating that the two paradigms produce substantially different translations.
Second, fluency is assessed via perplexity on neural language models built with TheanoLM on a 4‑million‑sentence News Crawl sample. Across eight of nine directions, NMT outputs achieve significantly lower perplexities (average relative reduction of 10.45 %), confirming higher fluency. The only exception is English→Finnish, where PBMT benefits from a neural LM reranking step.
Third, word‑order reordering is quantified using Kendall’s τ distance between the word‑alignment permutation of each system’s output and a monotone baseline, as well as against the reference alignment. NMT systems consistently produce more reordering than PBMT (higher τ distance from monotone) while also achieving higher τ similarity to the reference, demonstrating superior word‑order modeling.
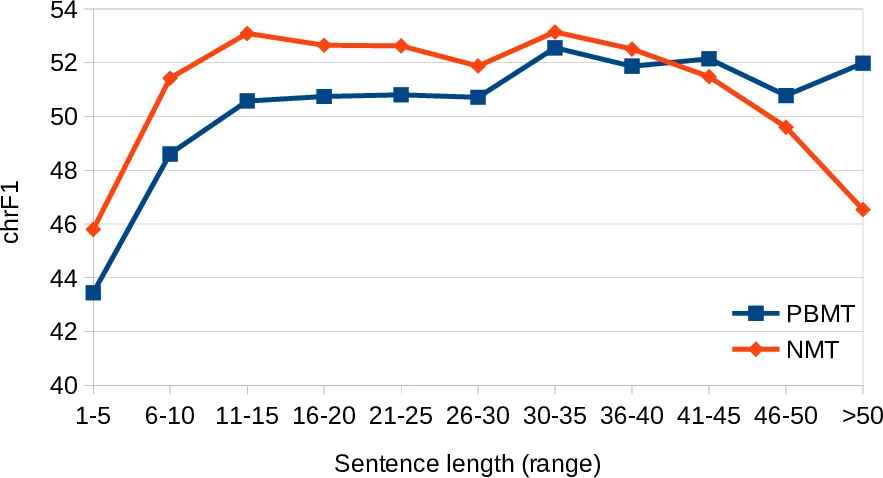
Fourth, the impact of sentence length is explored by binning test sentences and computing BLEU per bin. NMT shows steady gains for short and medium sentences but its advantage diminishes for sentences longer than about 30 tokens, where performance may even drop, highlighting a weakness in handling very long sequences.
Fifth, error analysis categorizes mismatches into inflectional, reordering, and lexical errors using automatic classifiers. NMT markedly reduces inflectional errors, confirming its strength in generating correct morphological forms. Reordering errors are also lower for NMT. However, lexical errors increase for very long sentences, suggesting that vocabulary selection remains a challenge for NMT in the long‑sentence regime.
Overall, the study confirms that NMT systems are generally more fluent, produce more diverse outputs, and handle word order better than PBMT systems, but they still struggle with very long sentences and occasional lexical choice errors. The authors conclude that while NMT has become the dominant paradigm, future work should focus on improving long‑range dependency modeling and lexical robustness, possibly through larger context windows, hierarchical architectures, or hybrid approaches that combine the strengths of both paradigms.
Comments & Academic Discussion
Loading comments...
Leave a Comment