Towards End-to-End Speech Recognition with Deep Convolutional Neural Networks
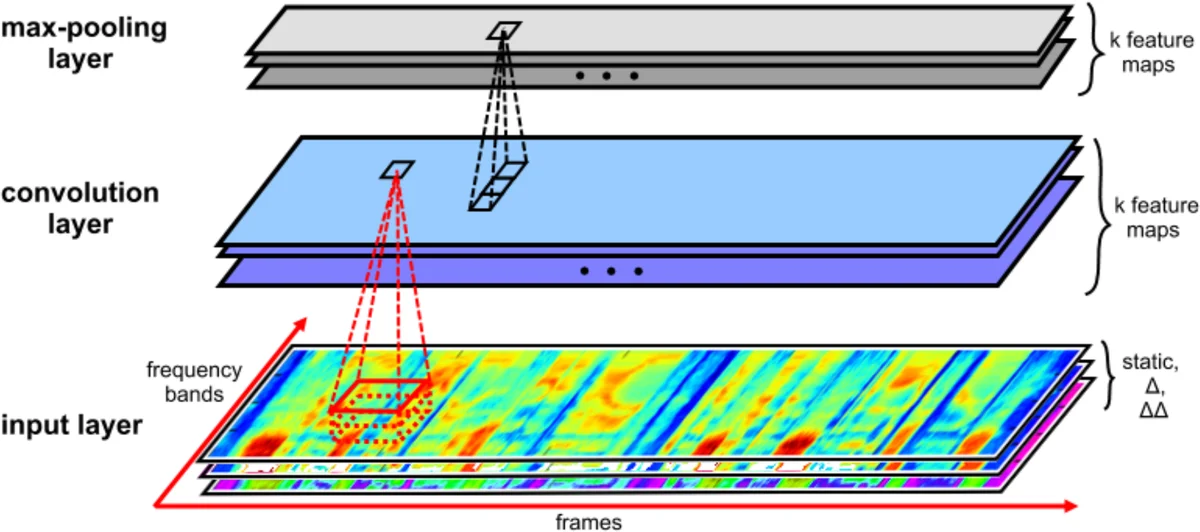
Convolutional Neural Networks (CNNs) are effective models for reducing spectral variations and modeling spectral correlations in acoustic features for automatic speech recognition (ASR). Hybrid speech recognition systems incorporating CNNs with Hidden Markov Models/Gaussian Mixture Models (HMMs/GMMs) have achieved the state-of-the-art in various benchmarks. Meanwhile, Connectionist Temporal Classification (CTC) with Recurrent Neural Networks (RNNs), which is proposed for labeling unsegmented sequences, makes it feasible to train an end-to-end speech recognition system instead of hybrid settings. However, RNNs are computationally expensive and sometimes difficult to train. In this paper, inspired by the advantages of both CNNs and the CTC approach, we propose an end-to-end speech framework for sequence labeling, by combining hierarchical CNNs with CTC directly without recurrent connections. By evaluating the approach on the TIMIT phoneme recognition task, we show that the proposed model is not only computationally efficient, but also competitive with the existing baseline systems. Moreover, we argue that CNNs have the capability to model temporal correlations with appropriate context information.
💡 Research Summary
The paper addresses the growing demand for end‑to‑end speech recognition systems that avoid the complexities of hybrid HMM‑GMM‑CNN pipelines and the computational burdens of recurrent neural networks (RNNs). While hybrid systems require separate training stages for acoustic models and language models, and RNN‑based Connectionist Temporal Classification (CTC) models suffer from slow training due to sequential processing and gradient instability, the authors propose a purely convolutional architecture combined directly with the CTC loss.
The proposed model processes raw audio into 40‑dimensional log‑mel filter‑bank features augmented with energy, first‑order (delta) and second‑order (delta‑delta) derivatives, yielding 123‑dimensional vectors that are mean‑variance normalized. The network consists of ten 2‑D convolutional layers followed by three fully‑connected layers. All convolutions use small 3×5 kernels; the first layer is followed by a 3×1 max‑pooling operation applied only along the frequency axis, preserving temporal resolution while reducing spectral variability. The first four convolutional layers have 128 feature maps each, and the remaining six have 256 maps, providing a deep hierarchy that expands the receptive field both in time and frequency. Non‑linearities are implemented with Maxout units (two linear pieces), which the authors demonstrate to be more expressive and easier to optimize than standard ReLU or parametric ReLU. After the convolutional stack, three dense layers of 1024 units each further transform the representation before a final softmax layer that feeds into the CTC loss.
Training proceeds in two stages: an initial phase with the Adam optimizer (learning rate 1e‑4) to quickly reach a reasonable region of the parameter space, followed by fine‑tuning with stochastic gradient descent (learning rate 1e‑5). Mini‑batches of size 20 are used, weights are initialized uniformly in
Comments & Academic Discussion
Loading comments...
Leave a Comment