World Literature According to Wikipedia: Introduction to a DBpedia-Based Framework
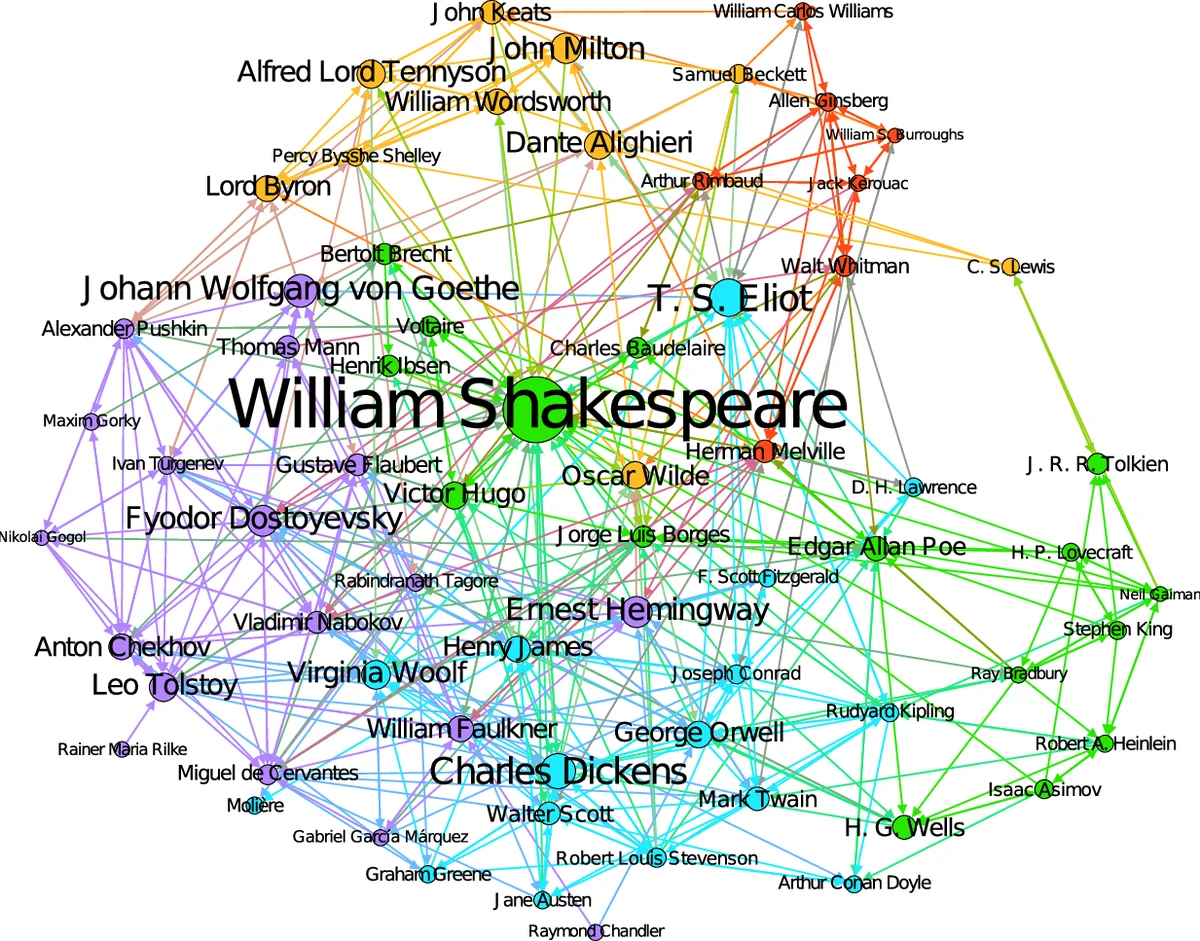
Among the manifold takes on world literature, it is our goal to contribute to the discussion from a digital point of view by analyzing the representation of world literature in Wikipedia with its millions of articles in hundreds of languages. As a preliminary, we introduce and compare three different approaches to identify writers on Wikipedia using data from DBpedia, a community project with the goal of extracting and providing structured information from Wikipedia. Equipped with our basic set of writers, we analyze how they are represented throughout the 15 biggest Wikipedia language versions. We combine intrinsic measures (mostly examining the connectedness of articles) with extrinsic ones (analyzing how often articles are frequented by readers) and develop methods to evaluate our results. The better part of our findings seems to convey a rather conservative, old-fashioned version of world literature, but a version derived from reproducible facts revealing an implicit literary canon based on the editing and reading behavior of millions of people. While still having to solve some known issues, the introduced methods will help us build an observatory of world literature to further investigate its representativeness and biases.
💡 Research Summary
This paper, titled “World Literature According to Wikipedia: Introduction to a DBpedia-Based Framework,” presents a digital humanities approach to studying the concept of world literature. It moves beyond traditional literary criticism by analyzing how world literature is represented within the massive, collaborative knowledge base of Wikipedia.
The core methodological challenge addressed is the reliable identification of “writers” across hundreds of different Wikipedia language editions, each with its own conventions. The authors propose and compare three distinct methods using data from DBpedia, a structured database extracted from Wikipedia: identifying articles using the “Writer” infobox template, those belonging to the “Writers” category, and those with a writer-related “Occupation” property. They find varying coverage and feasibility across languages, ultimately creating a combined set of approximately 35,000 candidate writers.
The analysis focuses on the 15 largest Wikipedia language editions, selected based on both article count and “article depth” (a measure of editing activity) to ensure data quality and minimize the influence of bot-generated content. The study employs a two-pronged evaluation strategy: “intrinsic measures” assess a writer’s structural importance within Wikipedia’s network using link analysis (e.g., PageRank within the hyperlink and category graphs), while “extrinsic measures” gauge popular interest using pageview statistics.
The results paint a picture of a “digital canon” as reflected by Wikipedia. The rankings, derived from the collective editing and reading behavior of millions of users, reveal a surprisingly conservative and Eurocentric landscape. Classical Western authors like Shakespeare, Goethe, and Dante dominate across multiple metrics and language versions. The analysis also uncovers language-specific biases, such as the elevated ranking of Hebrew-language writers in the German Wikipedia, suggesting cultural proximity effects, and cases where intense activity by single editors can skew representation.
The paper concludes that Wikipedia does not merely document world literature but actively constructs an implicit, data-driven canon through crowd-sourced processes. The introduced framework—combining multi-method writer identification, cross-lingual comparison, and multi-faceted ranking—serves as a foundation for building a sustainable “observatory” of world literature. This observatory would enable ongoing investigation into the representativeness and biases of digital literary discourse, offering a novel, empirical lens through which to study the evolving dynamics of world literature in the digital age.
Comments & Academic Discussion
Loading comments...
Leave a Comment