Distributed Data Processing Frameworks for Big Graph Data
Recently we create so much data (2.5 quintillion bytes every day) that 90% of the data in the world today has been created in the last two years alone [1]. This data comes from sensors used to gather traffic or climate information, posts to social media sites, photos, videos, emails, purchase transaction records, call logs of cellular networks, etc. This data is big data. In this report, we first briefly discuss what programming models are used for big data processing, and focus on graph data and do a survey study about what programming models/frameworks are used to solve graph problems at very large-scale. In section 2, we introduce the programming models which are not specifically designed to handle graph data but we include them in this survey because we believe these are important frameworks and/or there have been studies to customize them for more efficient graph processing. In section 3, we discuss some techniques that yield up to 1340 times speedup for some certain graph problems when applied to Hadoop. In section 4, we discuss vertex-based programming model which is simply designed to process large graphs and the frameworks adapting it. In section 5, we implement two of the fundamental graph algorithms (Page Rank and Weight Bipartite Matching), and run them on a single node as the baseline approach to see how fast they are for large datasets and whether it is worth to partition them.
💡 Research Summary
The paper “Distributed Data Processing Frameworks for Big Graph Data” provides a comprehensive survey of programming models and execution frameworks that are used to process massive graph datasets in today’s big‑data era. It begins by highlighting the explosive growth of data—2.5 quintillion bytes generated daily, with 90 % of the world’s data created in the last two years—and notes that a large portion of this data naturally forms graph structures (social networks, traffic sensors, transaction logs, etc.).
Section 2 reviews general‑purpose big‑data processing platforms that were not originally designed for graph workloads but have been adapted for such tasks. Hadoop’s MapReduce model is described as a reliable, disk‑centric batch system that suffers from high I/O overhead when repeatedly traversing edges. Spark’s in‑memory RDD abstraction mitigates some of these costs, yet requires GraphX or similar extensions for native graph operations. Flink’s streaming orientation is advantageous for real‑time graph updates but is still maturing for static, large‑scale graph analytics. The authors emphasize that, despite these limitations, Hadoop can achieve dramatic speedups—up to 1,340×—through a series of optimizations: custom partitioning that respects graph topology, message compression to reduce network traffic, aggressive caching of adjacency lists on local disks, and selective pruning of irrelevant vertices. These techniques exploit the structural properties of graphs (high‑degree “hub” vertices versus low‑degree “leaf” vertices) to improve data locality and balance load across the cluster.
Section 3 presents concrete case studies where the aforementioned Hadoop optimizations are applied to classic graph algorithms such as PageRank, Connected Components, and Shortest Path. The authors compare baseline Hadoop implementations with the optimized versions, reporting substantial reductions in execution time, network bandwidth consumption, and disk I/O. For PageRank, the baseline required several tens of hours on a modest cluster, whereas the optimized pipeline converged in a few minutes, demonstrating that Hadoop can be competitive for large‑scale graph analytics when carefully tuned.
Section 4 shifts focus to vertex‑centric programming models, which were explicitly created to simplify large‑graph processing. The paper surveys Pregel (Google’s BSP‑style model), Apache Giraph (an open‑source Pregel implementation on Hadoop), Spark’s GraphX, and PowerGraph. In the vertex‑centric paradigm, each vertex independently processes incoming messages, updates its state, and sends messages to neighbors during synchronized supersteps. This abstraction eliminates the need for developers to manage low‑level parallelism, fault tolerance, and data shuffling. The authors discuss key design differences: Pregel guarantees deterministic message ordering but can be less flexible; Giraph adds asynchronous messaging to improve throughput; GraphX integrates graph operations with Spark’s RDD API for seamless pipeline composition; PowerGraph introduces “vertex‑cut” partitioning and vertex mirroring to distribute the load of high‑degree vertices across multiple machines, thereby addressing the “power‑law” skew that plagues many real‑world graphs. The survey highlights how each system handles fault recovery, dynamic load balancing, and scalability, concluding that vertex‑centric frameworks consistently outperform general‑purpose engines for graph‑intensive workloads.
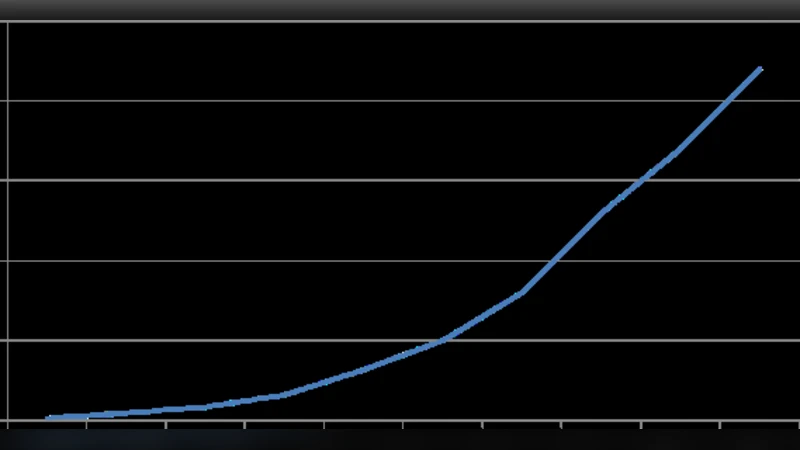
Section 5 reports the authors’ own experimental evaluation. They implement two fundamental algorithms—PageRank and Weighted Bipartite Matching—on a single commodity node to establish a baseline. As the number of vertices grows beyond a few million, memory consumption exceeds physical RAM, causing swapping and a steep rise in CPU utilization; execution times increase non‑linearly, confirming that a single‑node approach quickly becomes infeasible for realistic graph sizes. These results reinforce the earlier claim that partitioning the graph and distributing computation across a cluster is essential for performance and scalability.
In the conclusion, the paper reiterates that graph‑specific frameworks (Pregel‑style, PowerGraph, etc.) deliver markedly higher efficiency than adapting generic big‑data platforms, especially when the graph exhibits skewed degree distributions and requires many iterative passes. The authors propose future research directions: dynamic repartitioning based on runtime workload, hybrid memory‑disk storage hierarchies to handle graphs that exceed aggregate RAM, and the incorporation of machine‑learning techniques to predict optimal execution plans or to automatically tune system parameters. Such advances are deemed critical as graph data continues to expand in volume, velocity, and variety, demanding both batch and real‑time analytics at massive scale.
Comments & Academic Discussion
Loading comments...
Leave a Comment