Building a robust sentiment lexicon with (almost) no resource
Creating sentiment polarity lexicons is labor intensive. Automatically translating them from resourceful languages requires in-domain machine translation systems, which rely on large quantities of bi-texts. In this paper, we propose to replace machine translation by transferring words from the lexicon through word embeddings aligned across languages with a simple linear transform. The approach leads to no degradation, compared to machine translation, when tested on sentiment polarity classification on tweets from four languages.
💡 Research Summary
The paper addresses the costly and labor‑intensive process of building sentiment polarity lexicons for multiple languages. Traditional approaches either expand existing lexicons using seed words or translate English lexicons with statistical machine translation (SMT). The latter requires large parallel corpora and in‑domain bilingual data, and it struggles with out‑of‑vocabulary items such as misspellings, slang, and morphological variants that are common in social media. To overcome these limitations, the authors propose a resource‑light method that leverages bilingual word embeddings aligned through a simple linear transformation.
First, monolingual word2vec skip‑gram embeddings (200 dimensions, window size 7, 5 iterations) are trained on the Wikipedia dumps of English and each target language (French, Italian, Spanish, German). Second, a small bilingual dictionary consisting of the most frequent word pairs (up to 50 000 entries) is used to learn a transformation matrix W that minimizes the squared Euclidean distance between mapped source vectors and their target counterparts. This is a classic least‑squares problem, solved analytically. At inference time, any English word vector x is projected into the target language space via ŷ = W x, and the nearest target‑language words (cosine similarity ≥ 0.65) are taken as translations. The method thus produces a translated sentiment lexicon without any explicit machine‑translation system.
The authors evaluate the approach on three‑class sentiment classification (positive, negative, neutral) of tweets in four languages. Datasets come from DEFT’15 (French), SentiPOLC’14 (Italian), TASS’15 (Spanish), and a multilingual sentiment dataset (German). Features include word n‑grams, all‑caps counts, hashtags, punctuation patterns, emoticon presence, and counts of words found in each lexicon. An SVM with a linear kernel serves as the classifier. Four well‑known English sentiment lexicons—MPQA, BingLiu, Harvard General Inquirer (HGI), and NRC—are translated using three strategies: (1) no lexicon (baseline), (2) SMT via Moses trained on Europarl, (3) the proposed bilingual word embedding (BWE) method, and (4) a combination of SMT and BWE.
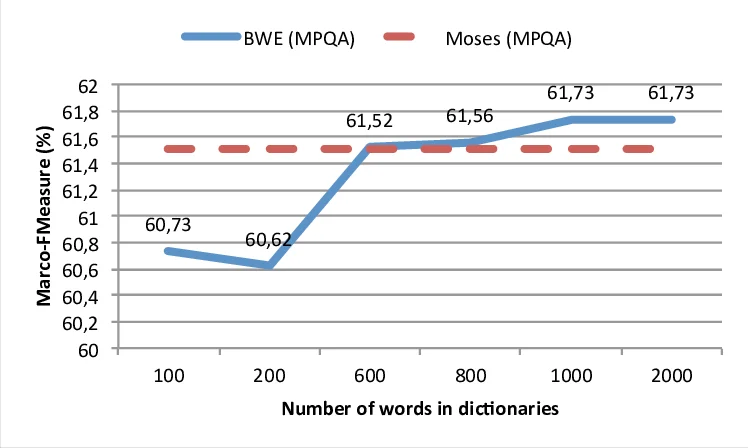
Results show that adding any lexicon improves macro‑F1 over the baseline (60.65%). SMT yields gains of roughly +1 to +1.5 points, while BWE achieves comparable improvements (+0.6 to +0.9 points). The combination of both methods consistently outperforms each individually, reaching an average macro‑F1 of 61.93% across languages. Importantly, performance plateaus after using about 50 000 frequent word pairs to train W; even 1 000 pairs provide a noticeable boost. Moreover, manually translating as few as 600 words from the MPQA lexicon and using them as the bilingual seed already surpasses SMT performance, demonstrating that a tiny amount of human effort can replace large parallel corpora.
The study acknowledges that the linear mapping assumes a roughly isomorphic semantic space between languages, which holds for relatively close Indo‑European languages but may break down for typologically distant languages. Future work is suggested to explore non‑linear mappings, joint multilingual embedding training, and domain‑specific corpora (e.g., Twitter) to further reduce the resource gap.
In summary, the paper presents a simple yet effective technique for cross‑lingual sentiment lexicon construction that requires only monolingual corpora and a modest bilingual dictionary. It matches or exceeds the performance of traditional SMT‑based translation while being far less dependent on scarce bilingual resources, thereby offering a practical solution for multilingual sentiment analysis in low‑resource settings.
Comments & Academic Discussion
Loading comments...
Leave a Comment