A natural language interface to a graph-based bibliographic information retrieval system
With the ever-increasing scientific literature, there is a need on a natural language interface to bibliographic information retrieval systems to retrieve related information effectively. In this paper, we propose a natural language interface, NLI-GIBIR, to a graph-based bibliographic information retrieval system. In designing NLI-GIBIR, we developed a novel framework that can be applicable to graph-based bibliographic information retrieval systems. Our framework integrates algorithms/heuristics for interpreting and analyzing natural language bibliographic queries. NLI-GIBIR allows users to search for a variety of bibliographic data through natural language. A series of text- and linguistic-based techniques are used to analyze and answer natural language queries, including tokenization, named entity recognition, and syntactic analysis. We find that our framework can effectively represents and addresses complex bibliographic information needs. Thus, the contributions of this paper are as follows: First, to our knowledge, it is the first attempt to propose a natural language interface to graph-based bibliographic information retrieval. Second, we propose a novel customized natural language processing framework that integrates a few original algorithms/heuristics for interpreting and analyzing natural language bibliographic queries. Third, we show that the proposed framework and natural language interface provide a practical solution in building real-world natural language interface-based bibliographic information retrieval systems. Our experimental results show that the presented system can correctly answer 39 out of 40 example natural language queries with varying lengths and complexities.
💡 Research Summary
The paper addresses the growing difficulty of retrieving bibliographic information from massive scientific literature collections by introducing a natural language interface (NLI‑GIBIR) for a graph‑based bibliographic information retrieval system (GIBIR). Traditional bibliographic search tools such as Web of Science, Scopus, and Google Scholar rely on form‑based or keyword‑based interfaces. Form‑based interfaces require users to select predefined fields (author, title, venue, etc.) and fill them in, which works well for simple queries but becomes cumbersome for complex information needs. Keyword‑based interfaces allow free‑text entry but often fail to capture the relationships among keywords, leading to ambiguous or incomplete results. The authors propose a controlled natural language (CNL) approach that lets users express complex queries as noun‑phrase constructions (e.g., “papers that were written by John”) and have those queries automatically translated into graph queries over a Neo4j‑style graph database.
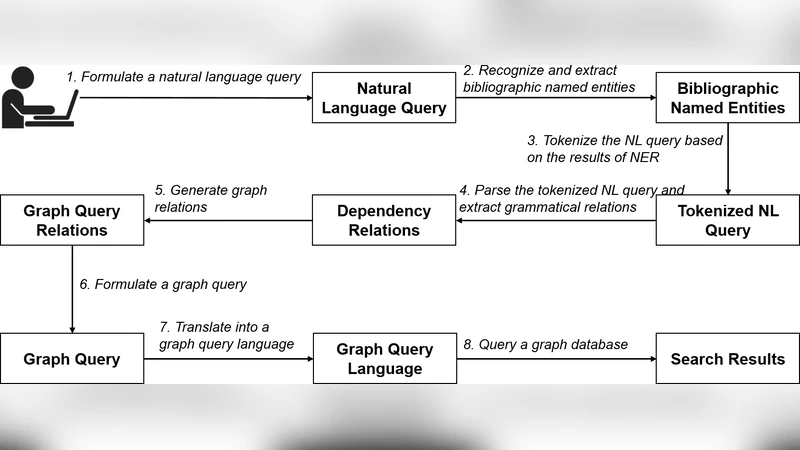
The core contribution is a full processing pipeline consisting of eight sequential steps: (1) user input of a natural‑language query, (2) dictionary‑based named entity recognition (NER) for five bibliographic entity types (Author, Paper, Term, Source, Organization), (3) tokenization that treats multi‑word entities as single tokens, (4) dependency parsing to extract grammatical relations such as “written by” or “published in,” (5) filtering of parsed relations and generation of corresponding graph edges, (6) construction of a graph query by combining entities and edges, (7) translation of this abstract query into a concrete graph query language (Cypher), and (8) execution of the query against the graph database. The NER component uses a modified Gusfield string‑matching algorithm with edit distance 1, allowing it to recognize plural/singular variations and minor spelling differences. Because the system relies on a pre‑compiled dictionary, it can quickly identify domain‑specific terms but does not perform disambiguation or handle out‑of‑vocabulary entities.
The authors evaluated the system with a set of 40 carefully crafted queries that vary in length and structural complexity. The system answered 39 of them correctly, achieving a 97.5 % success rate. The single failure was traced to a missing entry in the dictionary and a parsing error, highlighting the dependence on high‑quality lexical resources and robust syntactic analysis. The experimental results demonstrate that the pipeline can reliably translate controlled natural‑language bibliographic queries into accurate graph queries.
Despite its promising performance, the approach has several limitations. First, it only supports English noun‑phrase queries that explicitly include a relative pronoun (“that”) to aid the parser; full interrogative sentences are not accepted. Second, the reliance on a static dictionary means that new authors, venues, or terminology must be manually added, and the system lacks mechanisms for synonym handling or sense disambiguation. Third, the rule‑based query translation is not easily extensible to new relation types without additional hand‑crafted rules. Fourth, the system does not support logical operators (AND, OR, NOT) or nested queries, which restricts the expressiveness of user requests. Finally, the pipeline has been tested only on English; extending it to Korean, Chinese, or multilingual environments would require language‑specific tokenizers, parsers, and NER models.
In summary, the paper makes three notable contributions: (1) it is the first work to propose a natural‑language front‑end for a graph‑based bibliographic retrieval system, (2) it introduces a customized NLP framework that integrates dictionary‑based NER, tokenization, dependency parsing, and graph‑query generation, and (3) it provides empirical evidence that the framework can handle a wide range of realistic bibliographic queries with high accuracy. The authors suggest future work on automatic dictionary expansion, incorporation of statistical or neural NER for better coverage, support for multilingual queries, and the addition of logical operators and interactive query refinement to make the system more robust and user‑friendly.
Comments & Academic Discussion
Loading comments...
Leave a Comment