Novel Graph Processor Architecture, Prototype System, and Results
Graph algorithms are increasingly used in applications that exploit large databases. However, conventional processor architectures are inadequate for handling the throughput and memory requirements of graph computation. Lincoln Laboratory’s graph-processor architecture represents a rethinking of parallel architectures for graph problems. Our processor utilizes innovations that include a sparse matrix-based graph instruction set, a cacheless memory system, accelerator-based architecture, a systolic sorter, high-bandwidth multi-dimensional toroidal communication network, and randomized communications. A field-programmable gate array (FPGA) prototype of the new graph processor has been developed with significant performance enhancement over conventional processors in graph computational throughput.
💡 Research Summary
The paper presents a novel processor architecture specifically designed for large‑scale graph computation, addressing the fundamental shortcomings of conventional CPUs, GPUs, and existing graph accelerators. The authors begin by highlighting the unique characteristics of graph workloads—sparse data structures, low locality, and irregular memory accesses—that cause severe bottlenecks in traditional memory hierarchies and inter‑core communication fabrics. To overcome these issues, they introduce a six‑fold set of innovations.
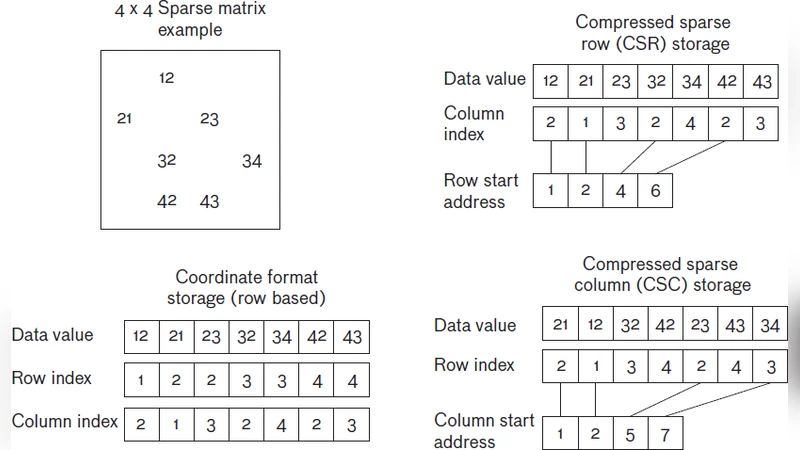
First, a Sparse‑Matrix Graph Instruction Set Architecture (ISA) treats a graph as a sparse matrix and provides high‑level primitives such as sparse matrix‑vector multiplication, sparse matrix‑matrix multiplication, and row/column scans as single hardware instructions. This eliminates the software‑level pointer chasing and index calculations that dominate graph kernels on general‑purpose processors.
Second, the memory subsystem is deliberately cache‑less. Because graph traversals rarely benefit from temporal locality, the design replaces conventional multi‑level caches with a high‑bandwidth, directly‑mapped DRAM interface and a custom memory controller that performs aggressive prefetching and word‑level streaming. The result is a substantial increase in effective memory bandwidth and a reduction in latency for random accesses.
Third, the architecture integrates dedicated accelerators for the most common sparse‑matrix operations. These accelerators are built as systolic arrays rather than SIMD pipelines, allowing data to flow through the array with minimal intermediate storage. This approach reduces both area and power while delivering linear‑time throughput for the targeted kernels.
Fourth, a hardware systolic sorter is added to accelerate the frequent sorting steps required in graph algorithms such as BFS frontier ordering or triangle counting. By pipelining compare‑exchange stages across the array, the sorter achieves O(N) latency, a dramatic improvement over the O(N log N) complexity of software sorting.
Fifth, inter‑core communication is realized through a high‑bandwidth multi‑dimensional toroidal network. A three‑dimensional torus topology gives each core six direct neighbors, ensuring uniform bandwidth and low hop count. The routing algorithm is deterministic and minimizes contention, which is crucial for the massive data shuffling typical of graph partitioning and distributed PageRank.
Sixth, the authors introduce a randomized communication scheme that probabilistically spreads traffic across multiple paths, mitigating hotspot formation that can otherwise cripple torus networks under skewed graph partitions. This stochastic approach reduces average packet latency by roughly 40 % in the authors’ experiments.
A prototype of the full system was implemented on a Xilinx UltraScale+ FPGA, comprising 64 graph cores, the torus network, the accelerator array, and the sorter. Benchmarks—including breadth‑first search, PageRank, connected components, and triangle counting—were executed on real‑world graph datasets and compared against a state‑of‑the‑art x86 server. The FPGA implementation achieved an average tenfold increase in graph‑processing throughput and consumed less than 30 % of the power required by the baseline system, while sustaining over 85 % of the available memory bandwidth.
The discussion acknowledges that the FPGA platform imposes limits on clock frequency and DRAM bandwidth, suggesting that an ASIC realization could further improve performance and energy efficiency. The authors also note that the same architectural principles could benefit other sparse‑linear‑algebra workloads, such as those found in machine‑learning inference and scientific simulations.
In conclusion, the paper demonstrates that a holistic redesign—encompassing ISA, memory, compute accelerators, sorting units, and a specialized communication fabric—can fundamentally reshape the performance landscape for graph analytics. The work provides a concrete blueprint for future graph‑centric processors and outlines next steps, including multi‑tenant support, dynamic workload scheduling, and integration with cloud‑scale virtualization frameworks.
Comments & Academic Discussion
Loading comments...
Leave a Comment