Distributed Gaussian Learning over Time-varying Directed Graphs
We present a distributed (non-Bayesian) learning algorithm for the problem of parameter estimation with Gaussian noise. The algorithm is expressed as explicit updates on the parameters of the Gaussian beliefs (i.e. means and precision). We show a con…
Authors: Angelia Nedic, Alex Olshevsky, Cesar A. Uribe
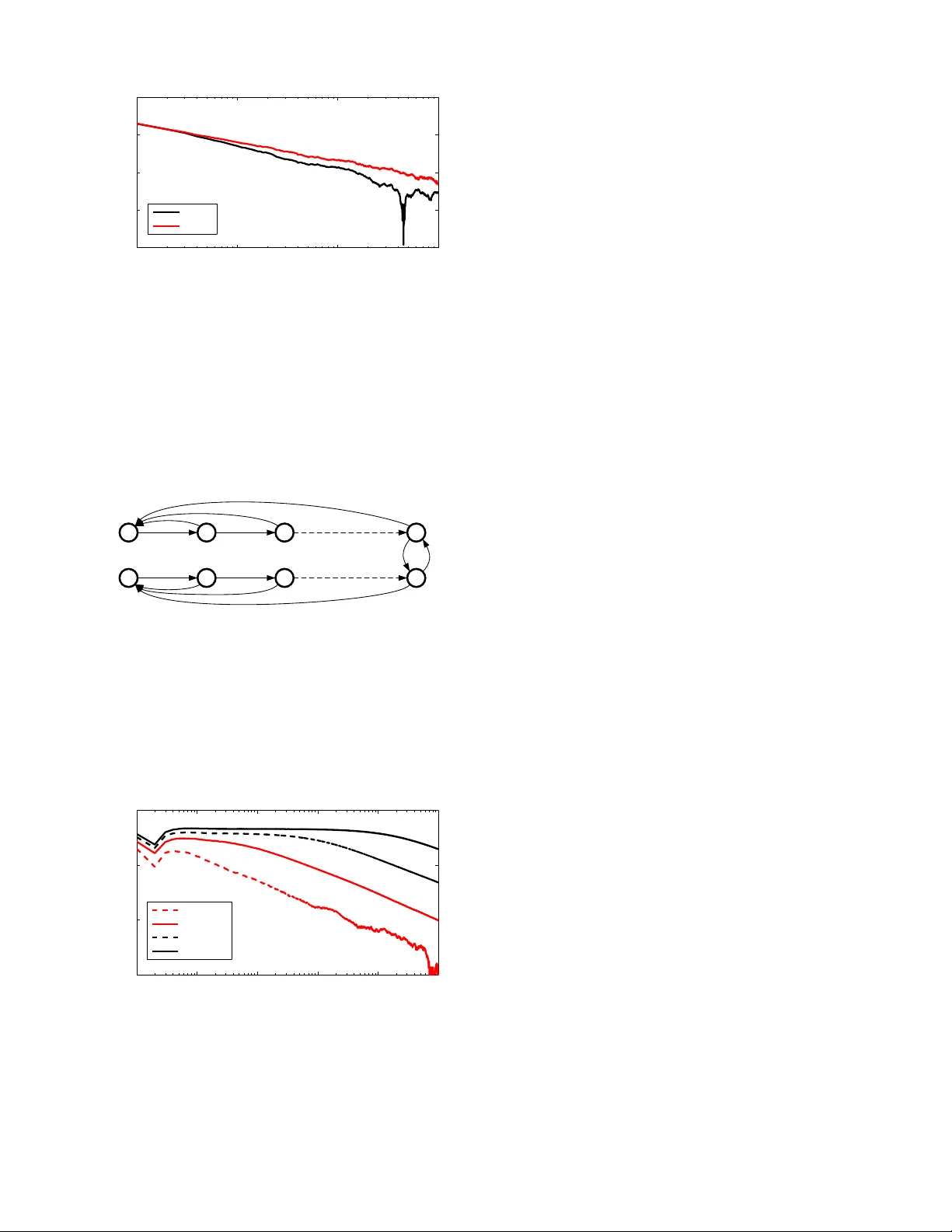
1 Distrib uted Gaussian Learnin g ov er T ime-v arying Directed Graphs Angelia Nedi ´ c, Alex Olshe vsky and C ´ esar A. Uribe Abstract — W e present a distributed (n on-Bay esian) learning algorithm f or the problem of p aram eter estimation with Gaus- sian noise. The algorithm i s expressed as ex plicit updates on the parameters of the Gaussian beliefs (i.e. means and precision). W e sh o w a con vergence rate of O ( 1 /k ) with the constant term dependin g on the number of age nts and the topology of the network. Mor eove r , we show almost sure conv ergence to the optimal solution of th e e stimation problem f or the general case of time-varying d irec ted graphs. I . I N T R O D U C T I O N The analysis of distrib uted (non-Bayesian) lear ning alg o- rithm gain ed p opularity since the seminal work of Jad babaie et al. [ 1]. The ability of no n-Bayesian upda tes to combine distributed op timization and learning alg orithms make them especially useful for the d esign of distributed estimation algorithm s with provable per formance. In the distributed learning setup, a group of agents re- peatedly receive signals about a certain unknown state of the world or parameter . No single ag ent has enough info r - mation to accurately estimate the unknown state and, thu s, interaction with other age nts is need ed. Se veral results are readily a vailable for perfo rmance ev a luation of distributed learning algorithms for a variety of scen arios. Asymp totic exponential co n vergen ce rates where de veloped in [2], [3], [4], no n-asymptotic bo unds in [5], time-varying directed graphs in [ 6], co nflicting hyp otheses and line ar rates in [7], no-reca ll a pproaches to belief sharin g in [ 8] and adversarial cases in [9], [10]. This list is ne cessarily inc omplete, an d th e reader is refe rred to [11] fo r an extended set of ref erences. Most of the previously propo sed m odels assume that the parameter space of the estimation process is finite. Initial approa ches to the study of contin uum sets of hy potheses were developed in [12], where explicit non-asym ptotic rates we re derived. A similar setup with Gau ssian noisy observations with n onlinear function o f the p arameter to be estimated h as been considered in [13], [14], where almost sure con vergence and asymptotic expo nential rates for fixed und irected graphs were established . Allowing the hypo theses set to b e infin ite (e.g. a c ompact sub set of R m ) enables the explor ation of traditional estimation problem s in a distributed mann er . On e of such prob lems is the param eter estimation with Gaussian noise, which is the m ain con cern of this man uscript. In particu lar , we focus on the Gaussian ca se o f the distributed (non-Bayesian) lea rning setup in [12]. W e analyze A. Nedi ´ c ( angelia.nedi ch@asu.edu ) is with the ECEE Department, Ari- zona Stat e Uni versity . A. Olshe vsky ( al exols@b u.edu ) is with th e ECE Departmen t, Boston Uni ver sity . C.A. Uri be ( caurib e2@illino is.edu ) is with the Coordinated Scie nce Laboratory , Uni versi ty of Illi nois. This research is support ed partially by the Nati onal Science Foundat ion under grants no. CNS 15-44953 and no. CMMI-1463 262, and by the Office of Na va l Researc h under grant no. N000 14-12-1-0998. the belief update algorithm where agents observe a parameter corrup ted by Gaussian noise and likelihood models are Gaus- sian functio ns, which results in Ga ussian b eliefs . W e presen t explicit updates for the beliefs’ mean and variances, thus providing an algorithm for the d istrib uted estimation pro cess. W e sho w almost sure con vergence to an op timal p arameter and establish a con vergence rate of O (1 /k ) . W e also p rovide simulation results for o ur algor ithm and co mpare it with two a pproaches p roposed in [1 5], [ 16 ]. Ou r results ho ld for the gen eral case of time-varying dire cted graphs, which are established b y using ideas from the push-sum a lgorithm in [6], [17]. This paper is organized a s follows. Section II describes the p roblem setup, as well as the proposed algo rithm and main results. Sec tion III provides a detailed comp arison with results f rom [15], [16] for the case o f identically distributed observations for all age nts. Section I V shows simu lation results and comp arison with other algorith ms. Finally , con- clusions and futu re work ar e p resented in Sectio n V. Notatio n : superscr ipts refer to agen ts wh ich are usually indexed b y th e letters i or j . Subscripts indicate instants of time wh ich are de noted by the letter k . Random variables are denoted by capital letters, e.g. S i k , and their co rresponding realizations b y lower ca se letters, e. g. s i k . Th e transpose of a vector x is deno ted as x ′ . The term [ A ] ij denotes th e en try of a matrix A at th e i - th row and the j -th colum n. For a se- quence { A k } o f ma trices we let A k : t = A k A k − 1 · · · A t +1 A t for k ≥ t . W e den ote the Gaussian fu nction by N ( θ, σ 2 ) = 1 √ 2 π σ 2 exp − ( x − θ ) 2 2 σ 2 . I I . P RO B L E M S E T U P , A L G O R I T H M A N D R E S U LT S Consider a group of n agents whose goal is to collectively solve the following op timization pro blem min θ ∈ Θ F ( θ ) , n X i =1 D K L f i k ℓ i ( ·| θ ) , (1) where D K L f i k ℓ i ( ·| θ ) is the Kullback- Leibler divergence between an un known distribution f i and a p arametrized distribution ℓ i ( ·| θ ) . Each agen t i has access to realizatio ns of a rand om variable S i k ∼ f i and a local family of parametrize d distributions { ℓ i ( ·| θ ) | θ ∈ Θ } , where Θ is a set of parameters. In other words, th e a gents want to determine a p arameter θ ∗ ∈ Θ correspo nding to a distribution Q n i =1 ℓ i ( ·| θ ∗ ) that is the closest to the distribution Q n i =1 f i in the sense of Kullback-Leib ler div ergence. Moreover , the agents a re allowed to interact over a sequ ence of time- varying d irected graph s {G k } , wher e G k = ( { 1 , . . . , n } , E k ) and E k is a set of edges such th at ( j, i ) ∈ E k indicates that agent j can com municate with agen t i at time k . 2 In [12], th e auth ors propo sed an alg orithm for solving the general pro blem of Eq. ( 1) for com pact sets Θ ⊂ R d . Th e algorithm generates no n-Bayesian posteriors beliefs b ased on local o bservations and shared beliefs fro m neighboring agents. Each ag ent i constru cts a sequence { µ i k } ∞ k =1 of be- liefs about the hypo thesis set Θ , where µ i k maps measurable subsets of Θ to real values indicating the belief that the unknown parameter θ ∗ is in the given subset. The algorithm propo sed in [12] is gi ven by ¯ µ i k +1 ∝ n Y j =1 ¯ µ j k a ij ℓ i ( s i k +1 |· ) , (2) where ¯ µ i k = dµ i k /d ¯ λ is a belief d ensity function , see [18], with respect to a refer ence measur e ¯ λ . Effecti vely , fo r a measurable su bset D ⊆ Θ , we have that the belief that θ ∗ is in D is giv en by µ i k ( D ) = R θ ∈ D ¯ µ i k ¯ λ ( θ ) . Addition ally , the scalar a ij is non negati ve and indicates how mu ch agen t i weights the belief s c oming from its neighbor j , with an understan ding that a ij = 0 if n o inter action between them occurs. In this manuscript, we assum e that the observations have Gaussian distribution and that th e likelihoods models are Gaussian, both with bo unded secon d o rder mo ments, i.e. S i k ∼ N ( θ i , ( σ i ) 2 ) and ℓ i ( ·| θ, σ i ) = N ( θ , ( σ i ) 2 ) wher e σ i > 0 f or e very i . This setting correspon ds to the case of having m easurements o f the true para meter θ ∗ corrup ted by som e Gaussian noise a nd the agents being infor med that the noise is Gaussian with a kn o wn variance. The Kullbac k-Leibler distance between two univ ariate Gaussian distributions p and q , wh ere p = N ( θ 1 , ( σ 1 ) 2 ) and q = N ( θ 2 , ( σ 2 ) 2 ) is given by D K L ( p k q ) = log σ 2 σ 1 + ( σ 1 ) 2 + ( θ 1 − θ 2 ) 2 ( σ 2 ) 2 − 1 2 . Thus, in this c ase, the p roblem in Eq. (1) is equ i valent to min θ ∈ Θ ˆ F ( θ ) , n X i =1 ( θ − θ i ) 2 2( σ i ) 2 , (3) which is conve x with a u nique solution θ ∗ = n X i =1 θ i / ( σ i ) 2 n P j =1 1 / ( σ j ) 2 . (4) Howe ver , the exact value o f θ i is u nknown and each agent i has access only to noisy observations o f the form S i k = θ i + ǫ i , where ǫ i ∼ N (0 , ( σ i ) 2 ) . Moreover , variances are only known loca lly , i.e. ag ent i o nly knows σ i . W e pr opose the follo wing distributed algorithm for solving the pro blem in Eq. (3) over time- v arying d irected grap hs τ i k +1 = n X j =1 [ A k ] ij τ j k + τ i (5a) θ i k +1 = n P j =1 [ A k ] ij τ j k θ j k + s i k +1 τ i τ i k +1 (5b) where τ i = 1 / ( σ i ) 2 is refereed as the precision of the observations. The weigh ts [ A k ] ij are chosen as [ A k ] ij = ( 1 d j k +1 if ( j, i ) ∈ E k , 0 otherwise (6) where d j k is the out-degree of n ode j at time k . W itho ut loss of generality , we assume th at τ i 0 = τ i for all i . Remark 1 It is not necessary for each agent to h ave some form o f informative observations. In deed, ther e might be agents with no observation s working as buffer s for informa- tion for which we a lso e xpect correct estimates of θ ∗ . These “blind” agents depend on co mmunicating with othe r agents to construct its estimates. Remark 2 While our fo cus is in on the univariate Gaussian case, extensions to the mu ltivariate ar e similarly possible us- ing the r esults of con jugate priors for multivariate Gau ssian distributions. The next prop osition shows that the algor ithm in E q. (5) is a specific realization of Eq. (2) for the case of Gaussian distributions in the priors and likelihoo d models. Proposition 1 Let the prior belief density ¯ µ i 0 of every agent be a Gaussian fu nction, i.e. ¯ µ i 0 ( θ ; θ i 0 , σ i ) = N ( θ i 0 , ( σ i ) 2 ) and let th e p arametric fa mily o f distributions fo r the likeli- hood models be Ga ussian fun ctions, i.e. ℓ i ( s | θ ; ( σ i ) 2 ) = N ( θ , ( σ i ) 2 ) . Then, for any k ≥ 1 , the po sterior belief d ensity ¯ µ i k , given by Eq. ( 2) , is also a Ga ussian function. Mor eover , if the weights a ij ar e chosen to be 1 / ( d j k + 1) , th en th e mea n and the standa r d deviation o f the p osterior follow Eq. (5) . Before pr esenting our main results, we state two au xiliary lemmas f rom [17] that describe the g eometric convergence for the prod uct of column stochastic m atrices. Lemma 2 [Cor o llary 2.a in [17]] Let the gr aph sequence {G k } be B-str ongly conn ected 1 . Then , ther e is a sequ ence { φ k } o f stochastic vectors such that | [ A k : t ] ij − φ i k | ≤ C λ k − t for all k ≥ t ≥ 0 wher e { A k } is as in Eq. (6) and the constants C and λ satisfy the following relations: (1) F or general B -str on gly co nnected graph seque nces { G k } C = 4 , λ = 1 − 1 n nB 1 B . (2) If every graph G k is r e gular with B = 1 C = √ 2 , λ = 1 − 1 / 4 n 3 . 1 There is an inte ger B ≥ 1 such that the graph V , S ( k +1) B − 1 i = kB E i is strongly connec ted for all k ≥ 0 3 Lemma 3 [Cor o llary 2.b in [17]] Let the gr aph sequence {G k } b e B -str ongly con nected, and defin e δ , inf k ≥ 0 min 1 ≤ i ≤ n [ A k :0 1 n ] i . Then, δ ≥ 1 /n nB . Moreover , if every G k is re gula r and str ong ly connecte d (i.e. B = 1 ), the n δ = 1 . Fu rthermor e, the sequence { φ k } fr om Lemma 2 satisfies φ j k ≥ δ /n for all k ≥ 0 a nd j = 1 , . . . , n . Now , we p roceed to state our two main r esults showing the convergence proper ties o f the a lgorithm in Eq. (5 ). Lemma 4 The e xpected mean pr ocess { E [ θ i k ] } co n ver ges to θ ∗ for all i with a con ve r gence rate o f O (1 /k ) . Moreo ver , the co nstant terms depend on the topology o f the network, the precision of the ob servations and the initial guess. Pr oo f: In fact, we will p rove the bo und E [ θ i k +1 ] − θ ∗ ≤ τ max τ min k δ k θ 0 − θ ∗ 1 k 1 + 2 C k θ − θ ∗ 1 k 1 1 − λ (7) with τ max = max j τ j , and τ min is th e smallest non-zero precision among all a gents. First, define a new variable as x i k = τ i k θ i k , then fr om Eq. (5b) it f ollo ws that x k +1 = A k x k + diag ( τ ) s k +1 = A k :0 x 0 + k X t =1 A k : t diag ( τ ) s t + diag ( τ ) s k +1 where diag ( τ ) is a diago nal matrix with [ diag ( τ )] ii = τ i and x k = [ x 1 k , . . . , x n k ] ′ , τ = [ τ 1 , . . . , τ n ] ′ , s k = [ s 1 k , . . . , s n k ] ′ . Adding and subtracting P k t =1 φ k τ ′ s t from the preced ing relation we ob tain x k +1 = A k :0 x 0 + k X t =1 D k : t diag ( τ ) s t + diag ( τ ) s k +1 + k X t =1 φ k τ ′ s t with D k : t = A k : t − φ k 1 ′ , and φ k is as in Lemm a 2. Follo wing a similar pro cedure, from Eq. (5a) it ho lds that τ k +1 = A k :0 τ 0 + k X t =1 D k : t τ + k φ k 1 ′ τ + τ . Going back to the original variable θ k , we have that E [ θ i k +1 ] = [ A k :0 diag ( τ ) θ 0 ] i + P k t =1 [ D k : t diag ( τ ) θ ] i + τ i θ i + k φ i k τ ′ θ [ A k :0 τ 0 ] i + P k t =1 [ D k : t τ ] i + k φ i k 1 ′ τ + τ i By subtracting θ ∗ on bo th sides of the previous relation an d taking the absolu te value, we obta in E [ θ i k +1 ] − θ ∗ ≤ [ A k :0 diag ( τ 0 ) ( θ 0 − θ ∗ 1 )] i P k t =1 [ D k : t τ ] i + k φ i k 1 ′ τ + τ i θ i − θ ∗ P k t =1 [ D k : t τ ] i + k φ i k 1 ′ τ + P k t =1 [ D k : t diag ( τ ) ( θ − θ ∗ 1 )] i P k t =1 [ D k : t τ ] i + k φ i k 1 ′ τ where the terms in volving k φ i k τ ′ θ cancel out an d the fol- lowing positive terms are re moved from the denomin ator [ A k :0 τ 0 ] i + τ i > 0 . Then b y the fact that [ D k : t 1 ] i + φ i k n > δ on the deno mi- nator and using L emma 2 on th e third term it fo llo ws th at E [ θ i k +1 ] − θ ∗ ≤ [ A k :0 diag ( τ 0 ) ( θ 0 − θ ∗ 1 )] i k δ τ min + τ i | θ i − θ ∗ | k δ τ min + C τ max k θ − θ ∗ 1 k 1 k δ τ min (1 − λ ) . Finally , the desired result follows by H ¨ o lders ineq uality in the first term with k [ A k :0 diag ( τ )] i k ∞ = τ max and g rouping the second and thir d terms since C 1 − λ > 1 . E [ θ i k +1 ] − θ ∗ ≤ max j [ A k :0 ] ij τ j k θ 0 − θ ∗ 1 k 1 k δ τ min + + 2 C τ max k θ − θ ∗ 1 k 1 k δ τ min (1 − λ ) . The first term in Eq. ( 7) shows th e dep endency on the initial estimates θ 0 while th e secon d term shows d epends on the hetero geneity of mean of local observations. The network topolog y and the numbe r of agents is charac terized by λ an d δ . W e are now ready to state ou r main result about the a lmost sure conv ergence of the pr oposed algorith m. Theorem 5 Let the graph sequence of interactions {G k } ∞ k =1 be B-str on gly connected . Mor eover , assume S i k ∼ N ( θ i , ( σ i ) 2 ) an d ℓ i ( ·| θ ) = N ( θ , ( σ i ) 2 ) for a ll i . Then, the sequence { θ i k } generated by Eq. (5) conver ges almost sur ely to θ ∗ , i.e. lim k →∞ θ i k = θ ∗ a.s. ∀ i A proof o f Theorem 5 is not shown due to space constraints. Noneth eless, its r esult follo ws by the boun ded variance assumptio n of the ob servations and the weighted law o f large nu mbers in [1 9]. Remark 3 The spe cific selec tion of weights as 1 / ( d j k + 1 ) is a design choice. Theor em 5 st ill h olds for a ny sequence of column stochastic ma trices { A k } with every non-zer o entry bou nded fr om be llow away fr om zer o, and with po sitive diagonal entries. I I I . I D E N T I C A L D I S T R I B U T I O N S F O R A L L AG E N T S A specific version of the pr oposed pro blem is the case when all agents o bserve independent realizations of the same random variable, i.e. S i k ∼ N ( θ ∗ , ( σ 2 ) ∗ ) . Recently , autho rs in [1 5], [16] hav e explored this case. Specifically , in [16] the au thors are concerned with the effects of the netw ork topolog y on the conver gence rate o f the distrib uted mean estimation prob lem. They show me an square consistency o f the following algorith m θ i k +1 = k k + 1 n X j =1 a ij θ j k + 1 k + 1 s i k +1 , (8) and provide explicit rates for different netw ork topologies. Note that the algorithm in Eq. (8 ) re duces to Eq. (5) when 4 τ i = 1 in such a way that τ i k = k for all i , and the grap h is static with a do ubly stocha stic weight matrix. In [15], the autho rs p roposed a new distributed Gaussian learning algo rithm wh ere com munication between agents is noisy . Follo wing the non-Bayesian learning without recall approa ch pro posed in [8] they dev elop the specific realization for Gaussian random variables. Add itionally , they consider the seq uence of observations { s i k } as coming fr om an agen t, denoted as n + 1 , an d thus a different weightin g strategy is propo sed. T heir algo rithm is τ i k +1 = τ i k + d j k τ (9a) θ i k +1 = P n +1 j =1 τ j k a j k τ i k +1 (9b) with the specific condition that τ j k = τ fo r all j 6 = i , a j k = θ i k for j = i and a j k = θ j k + ǫ with ǫ ∼ N (0 , τ ) , with a n +1 k = s i k . The authors showed a lmost sure con vergenc e of the algorithm . Mo reover , a c on vergence rate of O ( k − γ 2 d ) was d eri ved, wher e γ is a bound o n th e un iform conn ecti vity to the truth ob serv ations and d is th e maximal degree over all the network s. One par ticular characteristic of the alg orithm propo sed in [15] is that, apart fro m traditional literature on distrib uted learning, th e authors d o not assume age nts communica te over a sufficiently connected network ( B -strong conn ecti vity in Theor em 5). They r eplace th is assumption by a so- called truth-hearing assumption which w orks as a 1 /γ -stron g connectivity with the n + 1 no de that provides direct noisy observations o f θ ∗ . Th us, it is r equired that every no de receives signals fro m n ode n + 1 a t least once in ev ery time interval of length 1 / γ . If all ag ents r ecei ve in dependent observations fr om iden tical distributions, connectivity of the network and tr uth hearing assumption s bo th serve the same purpo se of guara ntying th e diffusion of the inf ormation over the n etwork, o therwise some f orm of con necti vity between agents is nee ded. In addition to dif feren t conne cti vity assump tions, one m ain characteristic of the algorithm in Eq. (9 ) is tha t a gents do not differentiate the signal S i k coming from the ob servations of the parameter, and the signals { a j k } coming from other agents. Every agent tre ats both signals similarly . The weig hts for ob servati ons of S i k and ne ighbors signals { θ i k } n i =1 decay . Whereas in ou r appr oach in Eq. (5) the weight for S i k decays to zero an d th e weigh t fo r the conv ex combinatio n of { θ i k } n i =1 goes to on e. This in deed shows that we d o requir e th e identification of signals coming from either agents or the noisy par ameter observations. This extra inf ormation could explain why o ur app roach has better perfo rmance in terms of conv ergence rates. I V . S I M U L AT I O N S In this section, we provide simulation results f or o ur propo sed algorithm and we comp are its p erformance with results in [15], [16]. Initially , we will co nsider the same scenario as in [15], [16] with static undirec ted grap hs with all agents having identical distributions in their no iseless beliefs sharing . W e will ev aluate th e pe rformance of the algorithms for two d if ferent gra phs topolog ies, namely: p ath/line graph and a lattice/grid g raph. 10 0 10 1 10 2 10 3 10 4 10 5 10 −6 10 −4 10 −2 10 0 10 2 k | θ k i − θ * | Eq. (5) O(1/k 1/d ) O(1/k) Eq. (9) Fig. 1. Simulati ons results of algorit hms in Eq. (5) and Eq. (9) for a latti ce/grid graph of 25 node s for an av erage be havior over 500 Monte Carlo simulati ons. Figure 1 shows th e ab solute erro r o f th e estimated value θ ∗ for the lattice/grid grap h with 25 agents. It is assumed that S i k ∼ N (4 , 1) . An a verag e over 500 M onte C arlo simulation s is shown for one arbitrary ag ent. In a ddition, the theoretical conv ergence r ates are also shown fo r comp arison purp oses. No simu lation of th e algorith m in Eq. (8) is shown since it reduces to the same algo rithm as in Eq. (5) for the simula ted scenario. Figure 2 s hows the simulation results for th e sam e scen ario as in Figure 1 but now for a path/line gra ph of 15 agents. As predicted by the theoretical convergence rate bou nds, the propo sed algor ithm in Eq. (5) de cays as O (1 / k ) wh ere the topolog y of the network affects on ly th e constant whereas the p roposal in E q. (9) d epends explicitly on the maxim um degree amo ng all grap hs as O (1 /k 1 /d ) . 10 0 10 1 10 2 10 3 10 4 10 5 10 −6 10 −4 10 −2 10 0 10 2 k | θ k i − θ * | Eq. (5) O(1/k 1/d ) O(1/k) Eq. (9) Fig. 2. Simulati ons results of algori thms in Eq. (5) and Eq. (9) for a path graph of 25 nodes. A ver age behavio r over 500 Monte Carlo simulations. Next, we will sh o w that f or the case o f e ach agent having noise with d if ferent standard d e viations, by u sing informa tion about the curren t estimate precision (i.e. τ i k ) a better pe rformance is achieved. Figu re 3 shows the abso lute error on the e stimation of θ ∗ for the algorithm in Eq . (5) that uses pre cision in formation and the prop osal in Eq. (8) that assumes uniform precision. In this simulation, agents have heteroge neous pr ecisions such th at S i k ∼ N (4 , i ) . Tha t is, in the path graph , th e first a gent has τ 1 = 1 , th e last agent, on the o ther hand, h as τ n = n . This implies that agent 1 has the highest v ariance in its observations. W e have ch osen to show the results f or agent 1 o nly . 5 10 0 10 1 10 2 10 3 10 −6 10 −4 10 −2 10 0 10 2 k | θ 1 k − θ * | Eq. (5) Eq. (8) Fig. 3. Simulati ons results of algorit hms in Eq. (5) and Eq. (8) for a path graph of 25 nodes with heterogeneous precisions (i.e. τ ′ s ). A verage beha vior over 500 Monte Carlo simulations. Finally , we will present the simulatio n results for a di- rected static graph which has been sho wn t o be a pathological case fo r the p ush-sum algorithm , see Figure 4. Each agent receives si gnals of the form S i k ∼ N ( i, n − i + 1) . Thus every agent has different m easurement precisions an d d if ferent θ i . The optimal θ ∗ as defin ed in Eq. (4). Fig. 4. Dire cted graph for simulatio n of the algori thm in Eq. (5). Figure 5 shows the simulation results for the algo- rithm i n Eq. ( 5) to the specific set of observations S i k ∼ N ( i, n − i + 1) on the graph in Figur e 4. The av erage over 10 Monte Carlo simulatio n is shown. The p redicted O (1 / k ) behavior is o bserved, after a tran sition time that depend s on the n umber o f agents in the network, (i.e. the effects on n and λ in Lem ma 4). 10 0 10 1 10 2 10 3 10 4 10 5 10 −4 10 −2 10 0 10 2 k | θ k 1 − θ * | 10 Agents 20 Agents 30 Agents 40 Agents Fig. 5. Simulatio ns results of algorithms in Eq. (5) for the graph depicte d in Figure 4. Four dif ferent result s are sho wn, for 10 , 20 , 30 and 40 agent s respect iv ely . V . C O N C L U S I O N S W e d e veloped an a lgorithm fo r distributed parameter estimation with Gaussian noise over time-varying directed graphs. The proposed algo rithm is sh o wn to be a s pecific case of a m ore g eneral class of distributed (n on-Bayesian) learning methods. Almost sure conver ge as well as an explicit conv ergence rate is shown in terms of the network topol- ogy and the number of agents. Comparisons with recently propo sed approach es are presented . Future work sho uld consider no nlinear o bservations of the p arameter θ , that is S i k ∼ N ( g i ( θ ) , ( σ i ) 2 ) for some f unction g : Θ → R . Ongoing work develops similar par ameter estimation ap - proach es f or the larger case of the exponential family of distributions on the n atural parameter space. A particularly interesting case is wh en th e parameter θ ∗ is chang ing with time, either arbitrarily , on som e f orm o f Ma rkov p rocess or other d ependencies. This case r enders observations to be not identically distributed no r indep endent. R E F E R E N C E S [1] A. Jadbabaie , P . Molavi, A. Sandroni, and A. T ahbaz-Sale hi, “Non- bayesia n soci al learning, ” Games and Economic B ehav ior , vol. 76, no. 1, pp. 210–225, 2012. [2] S. Shahrampour and A. Jadbabaie, “Exponentia lly fast parameter esti- mation in netw orks using distribu ted dual averagi ng, ” in Pr oceedin gs of the IEEE Confere nce on Decision and Contr ol , 2013, pp. 6196– 6201. [3] A. Lalith a, T . Javidi, and A. S arw ate, “Social learning and distribute d hypothesi s testi ng, ” pre print arXiv:1410.4307 , 2015. [4] S. Shahrampour , A. Rakhlin, and A. Jadbabaie, “Distribute d detecti on: Finite- time anal ysis and impact of network topology , ” IEEE T ransac- tions on Automatic Contr ol , vol. 61, no. 11, pp. 3256–3268, Nov 2016. [5] A. Nedi ´ c, A. Olshe vsky , and C. A. Uribe, “Nona symptotic con vergen ce rates for cooperat iv e learning ove r time-v arying direc ted graphs, ” in Pr oceeding s of the American Contr ol Confer ence , 2015, pp. 5884– 5889. [6] ——, “Network independent rates in distribut ed learning, ” in P r oceed- ings of the American Contr ol Confer ence , 2016, pp. 1072–1077. [7] ——, “Fast con verg ence rates for distrib uted non-bayesian learn ing, ” pre print arXiv:1508.05161 , Aug. 2015. [8] M. A. Rahimian, S. Shahrampour , and A. Jadbabai e, “Learning without recall by random walks on directed graphs, ” prepri nt arXiv:1509.04332 , 2015. [9] L . Su and N. H. V aidya, “Non-bayesian learnin g in th e presence of byzantine agents, ” in Internatio nal Symposium on Distribute d Computing . S prin ger , 2016, pp. 414–427. [10] ——, “Defending non-ba yesian learning against adversarial attac ks, ” arXiv pr eprint arXiv:1606 .08883 , 2016. [11] A. Nedi ´ c, A. Olshev sky , and C. A. Uribe, “ A tutorial on distrib uted (non-baye sian) learning : Problem, algorithms and results, ” arX iv pre print arXiv:1609.07537 , 2016. [12] ——, “Distr ibuted learning w it h infinite ly many hypothese s, ” arXiv pre print arXiv:1605.02105 , 2016. [13] A. K. Sahu, S. Kar , J. M. F . Moura, and H. V . Poor , “Distrib uted constrai ned recursi ve nonline ar least-squ ares estimation: Algori thms and asymptoti cs, ” IEEE T ransact ions on Signal and Information Pr ocessing over Networks , vol. 2, no. 4, pp. 426–441, Dec 2016. [14] A. K. Sahu and S. Kar , “Distrib uted recursiv e composite hypothesis testing : Imperfect communication , ” in 2016 IEEE Internation al Sym- posium on Informati on Theory (ISIT) , July 2016, pp. 2679–2683 . [15] C. W ang and B. Chazelle, “Gaussia n learni ng-without-r ecall in a dynamic social network, ” arX iv preprin t arXiv:1609.05990 , 2016. [16] G. Biau, K. Bleakle y , and B. Cadre, “The statistica l performance of colla borati ve inference , ” J . Mach. Learn. Res. , vol. 17, no. 1, pp. 2200– 2228, 2016. [17] A. Nedi´ c and A. Olshe vsky , “ Distribut ed optimiza tion ove r ti me- v arying direc ted graphs, ” IEEE T ransactions on Automatic Contr ol , vol. 60, no. 3, pp. 601–615, 2015. [18] P . S mets, “Belief functions on real numbers, ” Internatio nal journal of appr oximate reasoning , vol. 40, no. 3, pp. 181–223, 2005. [19] W . E. Pruitt, “Summability of independ ent random varia bles, ” J ournal of Mathema tical and Mechanics , vol. 15, pp. 769–776, 1966.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment