Invariant Representations for Noisy Speech Recognition
Modern automatic speech recognition (ASR) systems need to be robust under acoustic variability arising from environmental, speaker, channel, and recording conditions. Ensuring such robustness to variability is a challenge in modern day neural network…
Authors: Dmitriy Serdyuk, Kartik Audhkhasi, Philemon Brakel
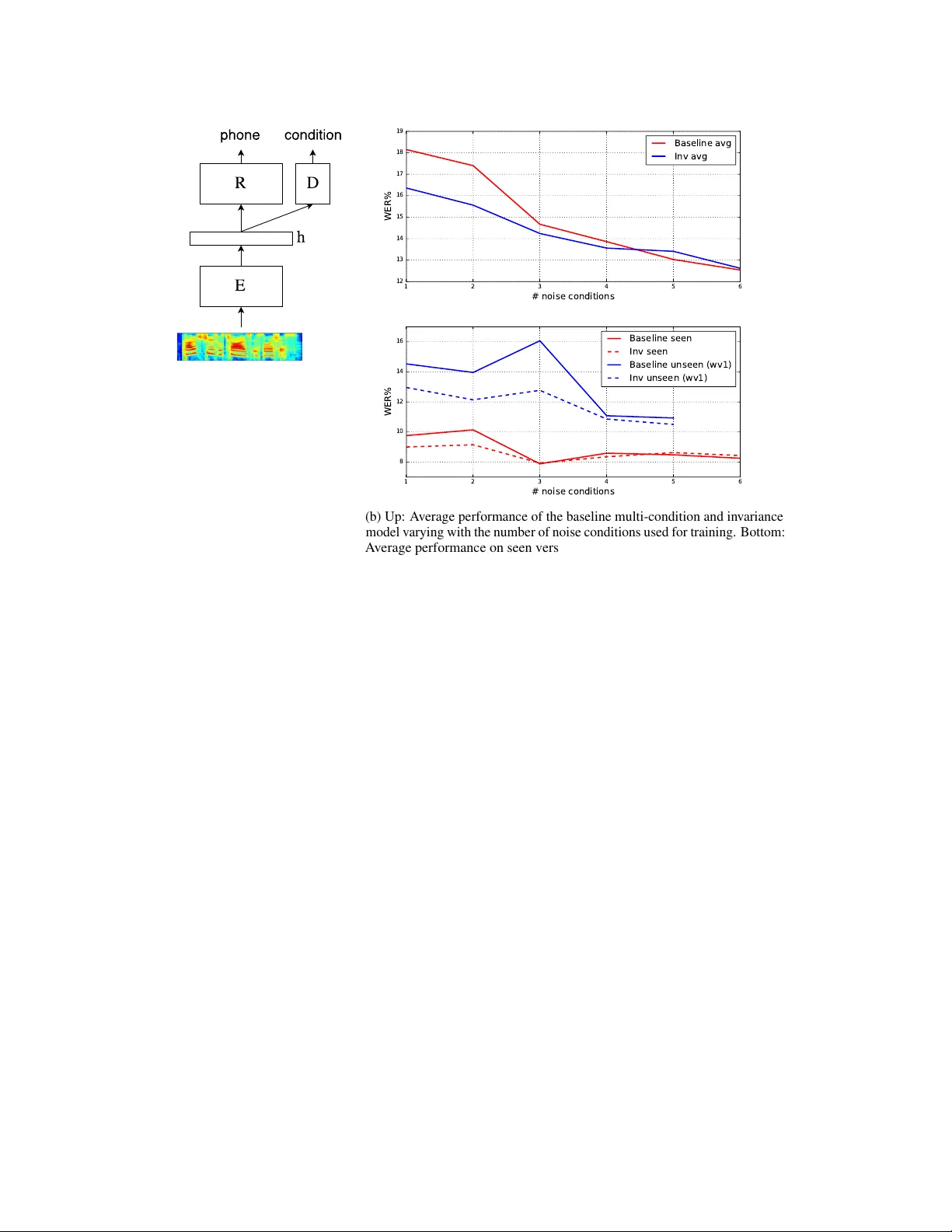
In variant Repr esentations f or Noisy Speech Recognition Dmitriy Serdyuk ∗ MILA, Univ ersité de Montréal Montréal, QC H3T 1J4 serdyuk@iro.umontreal.ca Kartik A udhkhasi IBM W atson, Y orktown Heights, NY Philémon Brakel MILA Univ ersité de Montréal Bhuvana Ramabhadran IBM W atson, Y orkto wn Heights, NY Samuel Thomas IBM W atson, Y orkto wn Heights, NY Y oshua Bengio MILA, CIF AR Fello w , Univ ersité de Montréal Abstract Modern automatic speech recognition (ASR) systems need to be robust under acoustic variability arising from en vironmental, speaker , channel, and recording conditions. Ensuring such robustness to variability is a challenge in modern day neural network-based ASR systems, especially when all types of variability are not seen during training. W e attempt to address this problem by encouraging the neural network acoustic model to learn in v ariant feature representations. W e use ideas from recent research on image generation using Generativ e Adversarial Netw orks and domain adaptation ideas extending adversarial gradient-based training. A recent work from Ganin et al. proposes to use adv ersarial training for image domain adaptation by using an intermediate representation from the main target classification network to deteriorate the domain classifier performance through a separate neural network. Our work focuses on in vestigating neural architectures which produce representations in v ariant to noise conditions for ASR. W e e v aluate the proposed architecture on the Aurora-4 task, a popular benchmark for noise robust ASR. W e show that our method generalizes better than the standard multi- condition training especially when only a few noise categories are seen during training. 1 Introduction One of the most challenging aspects of automatic speech recognition (ASR) is the mismatch between the training and testing acoustic conditions. During testing, a system may encounter new recording conditions, microphone types, speakers, accents and types of background noises. Furthermore, even if the test scenarios are seen during training, there can be significant variability in their statistics. Thus, its important to dev elop ASR systems that are in v ariant to unseen acoustic conditions. Sev eral model and feature based adaptation methods such as Maximum Likelihood Linear Regression (MLLR), feature-based MLLR and iV ectors (Saon et al. , 2013) hav e been proposed to handle speaker variability; and Noise Adapti ve T raining (N A T ; Kalinli et al. , 2010) and V ector T aylor Series (VTS; Un et al. , 1998) to handle environment variability . W ith the increasing success of Deep Neural Network (DNN) acoustic models for ASR (Hinton et al. , 2012; Seide et al. , 2011; Sainath et al. , ∗ Dmitriy Serdyuk performed the work during an internship at IBM W atson. 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain. 2011), end-to-end systems are being proposed (Miao et al. , 2015; Sainath et al. , 2015) for modeling the acoustic conditions within a single network. This allows us to take advant age of the network’ s ability to learn highly non-linear feature transformations, with greater flexibility in constructing training objecti ve functions that promote learning of noise in v ariant representations. The main idea of this work is to force the acoustic model to learn a representation in v ariant to noise conditions, instead of explicitly using noise robust acoustic features (Section 3). This type of noise-inv ariant training requires noise-condition labels during training only . It is related to the idea of generativ e adversarial networks (GAN) and the gradient reverse method proposed in Goodfello w et al. (2014) and Ganin & Lempitsky (2014) respecti vely (Section 2). W e present results on the Aurora-4 speech recognition task in Section 4 and summarize our findings in Section 5. 2 Related W ork Generative Adver sarial Networks consist of two netw orks: generator and discriminator . The generator network G has an input of randomly-generated feature vectors and is asked to produce a sample, e.g. an image, similar to the images in the training set. The discriminator network D can either receiv e a generated image from the generator G or an image from the training set. Its task is to distinguish between the “fak e” generated image and the “real” image tak en from the dataset. Thus, the discriminator is just a classifier network with a sigmoid output layer and can be trained with gradient backpropagation. This gradient can be propagated further to the generator network. T wo netw orks in the GAN setup are competing with each other: the generator is trying to decei ve the discriminator network, while the discriminator tries to do its best to recognize if there was a deception, similar to adversarial game-theoretic settings. Formally , the objectiv e function of GAN training is min G max D V ( D , G ) = E x ∼ p data ( x ) [log D ( x )] + E z ∼ p z ( z ) [log(1 − D ( G ( z )))] . The maximization ov er the discriminator D forms a usual cross-entropy objecti ve, the gradients are computed with respect to the parameters of D . The parameters of G are minimized using the gradients propagated through the second term. The minimization ov er G makes it to produce examples which D classifiers as the training ones. Se veral practical guidelines were proposed for optimizing GANs in Radford et al. (2015) and further explored in Salimans et al. (2016). Prior work by Ganin & Lempitsky (2014) proposed a method of training a network which can be adapted to new domains. The training data consists of the images labeled with classes of interest and separate domain (image background) labels. The network has a Y -like structure: the image is fed to the first network which produces a hidden representation h . Then this representation h is input to two separate networks: a domain classifier network (D) and a target classifier network (R). The goal of training is to learn the hidden representation that is in variant to the domain labels and performs well on the target classification task, so that the domain information doesn’ t interfere with the target classifier at test time. Similar to the GAN objecti ve, which forces the generation distribution be close to the data distribution, the gradient re verse method makes domain distributions similar to each other . The network is trained with three goals: the hidden representation h should be helpful for the target classifier , harmful for the domain classifier , and the domain classifier should ha ve a good classification accuracy . More formally , the authors define the loss function as L = L 1 ( ˆ y , y ; θ R , θ E ) + αL 2 ( ˆ d, d ; θ D ) − β L 3 ( ˆ d, d ; θ E ) , (1) where y is the ground truth class, d is the domain label, corresponding hat variables are the network predictions, and θ E , θ R and θ D are the subsets of parameters for the encoder, recognizer and the domain classifier networks respecti vely . The hyper-parameters α and β denote the relativ e influence of the loss functions terms. The influence of representations produced by a neural network to internal noise reduction is discussed in Y u et al. (2013) and this work sets a baseline for experiments on Aurora-4 dataset. Recently , in Shunohara (2016) a multilayer sigmoidal network is trained in an adversarial fashion on an in-house transcription task corrupted by noise. 2 (a) The model consists of three neural networks. The encoder E produces the intermediate representation h which used in the recognizer R and in the do- main discriminator D . The hid- den representation h is trained to improv e the recognition and minimize the domain discrimi- nator accuracy . The domain dis- criminator is a classifier trained to maximize its accuracy on the noise type classification task. 1 2 3 4 5 6 # noise conditions 12 13 14 15 16 17 18 19 WER% Baseline avg Inv avg 1 2 3 4 5 6 # noise conditions 8 10 12 14 16 WER% Baseline seen Inv seen Baseline unseen (wv1) Inv unseen (wv1) (b) Up: A verage performance of the baseline multi-condition and inv ariance model varying with the number of noise conditions used for training. Bottom: A verage performance on seen v ersus unseen noise conditions. T esting was performed on all wv1 conditions (Sennheiser microphone). Figure 1: Model structure for in v ariant training and ASR results. 3 In variant Repr esentations for Speech Recognition Most ASR systems are DNN-HMM hybrid systems. The context dependent (CD) HMM states (acoustic model) are the class labels of interest. The recording conditions, speaker identity , or gender represent the domains in GANs. The task is to make the hidden layer representations of the HMM state classifier network in variant with respect to these domains. W e hypothesize that this adv ersarial method of training helps the HMM state classifier to generalize better to unseen domain conditions and requires only a small additional amount of supervision, i.e. the domain labels. Figure 1a depicts the model, which is same as the model for the gradient rev erse method. It is a feed-forward neural netw ork trained to predict the CD HMM state, with a branch that predicts the domain (noise condition). This branch is discarded in the testing phase. In our experiments we used the noise condition as the domain label merging all noise types into one label and clean as the other label. Our training loss function is Eq. 1 with L 3 set to d log(1 − ˆ d ) + (1 − d ) log ( ˆ d ) for stability during training. L 3 term maximizes the probability of an incorrect domain classification in contrast to the gradient re verse where the correct classification is minimized. The terms L 1 and L 2 are regular cross-entropies which are minimized with corresponding parameters θ E and θ D . For simplicity , we use only a single hyper-parameter – the weight of the third term. 4 Experiments W e experimentally ev aluate our approach on the well-benchmarked Aurora-4 (Parihar & Picone, 2002) noisy speech recognition task. Aurora-4 is based on the W all Street Journal corpus (WSJ0). It contains noises of six categories which w as added to clean data. Every clean and noisy utterance is filtered to simulate the frequenc y characteristics. The training data contains 4400 clean utterances and 446 utterances for each noise condition, i.e. a total of 2676 noisy utterances. The test set consists of clean data, data corrupted by 6 noise types, and data recorded with a different microphone for both clean and noisy cases. 3 T able 1: A verage word error rate (WER%) on Aurora-4 dataset on all test conditions, including seen and unseen noise and unseen microphone. First column is the number of noise conditions used for the training. The last ro w is a preliminary experiment with layer-wise pre-training close to state-of-the-art model and a corresponding in v ariance training starting with a pretrained model. Noise In v BL A B C D In v BL In v BL In v BL Inv BL 1 16.36 18.14 6.54 7.57 12.71 14.09 11.45 13.10 22.47 24.80 2 15.56 17.39 5.90 6.58 11.69 13.28 11.12 13.51 21.79 23.96 3 14.24 14.67 5.45 5.08 10.76 12.44 9.75 9.84 19.93 19.30 4 13.61 13.84 5.08 5.29 9.73 9.97 9.49 9.56 19.49 19.90 5 13.41 13.02 5.12 5.34 9.52 9.42 9.55 8.67 19.33 18.65 6 12.62 12.60 4.80 4.61 9.04 8.86 8.76 8.59 18.16 18.21 6* 11.85 11.99 4.52 4.76 8.76 8.76 7.79 8.57 16.84 16.99 For both clean and noisy data, we extract 40-dimensional Mel-filterbank features with their deltas and delta-deltas spliced ov er ± 5 frames, resulting in 1320 input features that are subsequently mean and v ariance normalized. The baseline acoustic model is a 6-layer DNN with 2048 rectified linear units at ev ery layer . It is trained using momentum-accelerated stochastic gradient descent for 15 epochs with new-bob annealing (as in Mor gan & Bourlard, 1995; Sainath et al. , 2011). In order to ev aluate the impact of our method on generalization to unseen noises, we performed 6 experiments with dif ferent set of seen noises. The networks are trained on clean data, with each noise condition added one-by-one in the follo wing order: airport, babble, car , restaurant, street, and train. The last training group includes all noises therefore matches the standard multi-condition training setup. For e very training group, we trained the baseline and the in variance model where we branch out at the 4 th layer to an binary classifier predicting clean versus noisy data. Due to the imbalance between amounts of clean and noisy utterances, we had to o versample noisy frames to ensure that ev ery mini-batch contained equal number of clean and noisy speech frames. T able 1 summarizes the results. Figure 1b visualizes the word error rate for the baseline multi- condition training and in variance training as the number of seen noise types v aries. W e conclude that the best performance gain is achie ved when a small number of noise types are av ailable during training. It can be seen that in variance training is able to generalize better to unseen noise types compared with multi-condition training. W e note that our experiments did not use layer -wise pre-training, commonly used for small datasets. The baseline WERs reported are very close to the state-of-the-art. Our preliminary experiments on a pre-trained network (better ov erall WER) when using all noise types (last row of T able 1) for training show the same trend as the non-pretrained netw orks. 5 Discussion This paper presents the application of generativ e adversarial networks and in v ariance training for noise rob ust speech recognition. W e sho w that in variance training helps the ASR system to generalize better to unseen noise conditions and impro ves word error rate when a small number of noise types are seen during training. Our experiments show that in contrast to the image recognition task, in speech recognition, the domain adaptation network suffers from underfitting. Therefore, the gradient of the L 3 term in Eq. 1 is unreliable and noisy . Future research includes enhancements to the domain adaptation network while e xploring alternativ e network architectures and in variance-promoting loss functions. Acknowledgments W e would like to thank Y aroslav Ganin, Da vid W arde-F arley for insightful discussions, dev elopers of Theano Theano Dev elopment T eam (2016), Blocks, and Fuel van Merriënboer et al. (2015) for great toolkits. 4 References Ganin, Y aroslav , & Lempitsky , V ictor . 2014. Unsupervised Domain Adaptation by Backpropagation. ArXiv e-prints , Sept. Goodfellow , Ian, Pouget-Abadie, Jean, Mirza, Mehdi, Xu, Bing, W arde-Farley , David, Ozair , Sherjil, Courville, Aaron, & Bengio, Y oshua. 2014. Generative Adv ersarial Nets. P ages 2672–2680 of: Ghahramani, Z., W elling, M., Cortes, C., La wrence, N. D., & W einberger , K. Q. (eds), Advances in Neural Information Pr ocessing Systems 27 . Curran Associates, Inc. Hinton, Geof frey , Deng, Li, Y u, Dong, Dahl, Geor ge E, Mohamed, Abdel-rahman, Jaitly , Na vdeep, Senior , Andre w , V anhoucke, V incent, Nguyen, Patrick, Sainath, T ara N, et al. . 2012. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Pr ocessing Magazine , 29 (6), 82–97. Kalinli, Ozlem, Seltzer, Michael L, Droppo, Jasha, & Acero, Alex. 2010. Noise adaptiv e training for robust automatic speech recognition. IEEE T ransactions on Audio, Speech, and Language Pr ocessing , 18 (8), 1889–1901. Miao, Y ajie, Gowayyed, Mohammad, & Metze, Florian. 2015. EESEN: End-to-end speech recogni- tion using deep RNN models and WFST -based decoding. P ages 167–174 of: 2015 IEEE W orkshop on Automatic Speech Recognition and Understanding (ASR U) . IEEE. Morgan, Nelson, & Bourlard, Herv e. 1995. Continuous speech recognition. IEEE signal pr ocessing magazine , 12 (3), 24–42. Parihar , N, & Picone, J. 2002. Aurora w orking group: DSR front end L VCSR e v aluation A U/385/02. Inst. for Signal and Information Pr ocess, Mississippi State University , T ech. Rep , 40 , 94. Radford, Alec, Metz, Luke, & Chintala, Soumith. 2015. Unsupervised representation learning with deep con v olutional generativ e adversarial netw orks. arXiv preprint . Sainath, T ara N, Kingsb ury , Brian, Ramabhadran, Bhuvana, F ousek, Petr , Nov ak, Petr , & Mohamed, Abdel-rahman. 2011. Making deep belief networks ef fectiv e for large vocabulary continuous speech recognition. P ages 30–35 of: Automatic Speech Recognition and Understanding (ASR U), 2011 IEEE W orkshop on . IEEE. Sainath, T ara N, W eiss, Ron J, Senior, Andre w , Wilson, K e vin W , & V inyals, Oriol. 2015. Learning the speech front-end with raw wa veform CLDNNs. In: Pr oc. Interspeech . Salimans, Tim, Goodfellow , Ian, Zaremba, W ojciech, Cheung, V icki, Radford, Alec, & Chen, Xi. 2016. Improved techniques for training GANs. arXiv pr eprint arXiv:1606.03498 . Saon, George, Soltau, Hagen, Nahamoo, Da vid, & Picheny , Michael. 2013. Speak er adaptation of neural network acoustic models using i-vectors. P ages 55–59 of: ASR U . Seide, Frank, Li, Gang, & Y u, Dong. 2011. Con versational Speech T ranscription Using Context- Dependent Deep Neural Networks. P ages 437–440 of: Interspeech . Shunohara, Y usuke. 2016. Adversarial Multi-task Learning of Deep Neural Networks for Robust Speech Recognition. Interspeech 2016 , 2369–2372. Theano Dev elopment T eam. 2016. Theano: A Python framework for fast computation of mathematical expressions. arXiv e-prints , abs/1605.02688 (May). Un, Chong Kwan, Kim, Nam Soo, et al. . 1998. Speech recognition in noisy en vironments using first-order vector T aylor series. Speec h Communication , 24 (1), 39–49. van Merriënboer , Bart, Bahdanau, Dzmitry , Dumoulin, V incent, Serdyuk, Dmitriy , W arde-Farle y , David, Choro wski, Jan, & Bengio, Y oshua. 2015. Blocks and Fuel: Frameworks for deep learning. CoRR , abs/1506.00619 . Y u, Dong, Seltzer , Michael L, Li, Jinyu, Huang, Jui-T ing, & Seide, Frank. 2013. Feature learning in deep neural networks – studies on speech recognition tasks. arXiv pr eprint arXiv:1301.3605 . 5
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment