Model Accuracy and Runtime Tradeoff in Distributed Deep Learning:A Systematic Study
This paper presents Rudra, a parameter server based distributed computing framework tuned for training large-scale deep neural networks. Using variants of the asynchronous stochastic gradient descent algorithm we study the impact of synchronization protocol, stale gradient updates, minibatch size, learning rates, and number of learners on runtime performance and model accuracy. We introduce a new learning rate modulation strategy to counter the effect of stale gradients and propose a new synchronization protocol that can effectively bound the staleness in gradients, improve runtime performance and achieve good model accuracy. Our empirical investigation reveals a principled approach for distributed training of neural networks: the mini-batch size per learner should be reduced as more learners are added to the system to preserve the model accuracy. We validate this approach using commonly-used image classification benchmarks: CIFAR10 and ImageNet.
💡 Research Summary
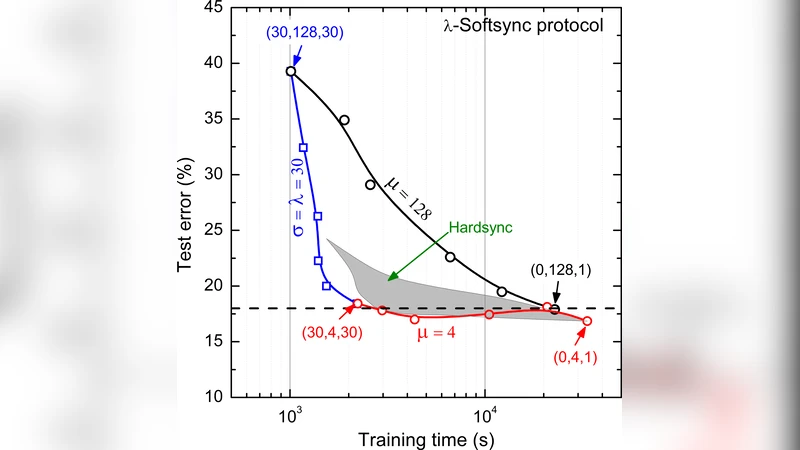
The paper introduces Rudra, a parameter‑server based distributed deep‑learning framework designed to study the trade‑off between model accuracy and runtime when scaling stochastic gradient descent (SGD). Three synchronization protocols are implemented: HardSync (zero staleness but high communication cost), Async (low latency but potentially large gradient staleness), and the newly proposed n‑softsync, which updates the model after collecting a configurable number of gradients (c = b·λ/n). By bounding the average staleness to ≤ 2·n, n‑softsync offers a middle ground between speed and accuracy.
A key contribution is a “staleness‑aware learning‑rate” scheme that scales the learning rate inversely with the measured staleness σ (α ← α/σ). Experiments show that this adjustment dramatically restores accuracy for asynchronous updates. The authors also discover a practical scaling rule: as the number of learners λ grows, the per‑learner mini‑batch size µ must be reduced proportionally to preserve a given accuracy level. This reveals a hard limit on parallelism for a fixed model and dataset.
To handle large models (≈ 300 MB) and very small µ, the authors extend Rudra‑base with two advanced variants. Rudra‑adv builds a hierarchical tree of parameter‑server nodes, each aggregating gradients locally before forwarding them upward, thereby reducing network contention. Rudra‑adv* adds a learner‑side broadcast tree and dedicated communication threads for asynchronous push/pull, achieving > 99 % overlap between computation and communication.
Empirical evaluation on CIFAR‑10 and ImageNet validates the approach. On CIFAR‑10, with µ = 4 and λ = 60, Rudra‑adv* reaches > 92 % accuracy while cutting training time by more than half compared to traditional Downpour SGD. On ImageNet, µ = 8 and λ = 48 yield a Top‑1 accuracy of 71 % with a 1.8× speed‑up. The results confirm that n‑softsync combined with staleness‑aware learning rates can achieve near‑synchronous accuracy while retaining the scalability benefits of asynchronous execution.
Overall, the study provides a systematic methodology for quantifying gradient staleness, demonstrates how hyper‑parameters and system‑level choices interact, and offers concrete engineering solutions (n‑softsync, hierarchical parameter servers, staleness‑aware learning rates) that enable efficient, accurate large‑scale distributed deep‑learning training.
Comments & Academic Discussion
Loading comments...
Leave a Comment