MCMC Louvain for Online Community Detection
We introduce a novel algorithm of community detection that maintains dynamically a community structure of a large network that evolves with time. The algorithm maximizes the modularity index thanks to the construction of a randomized hierarchical clu…
Authors: Yves Darmaillac, Sebastien Loustau
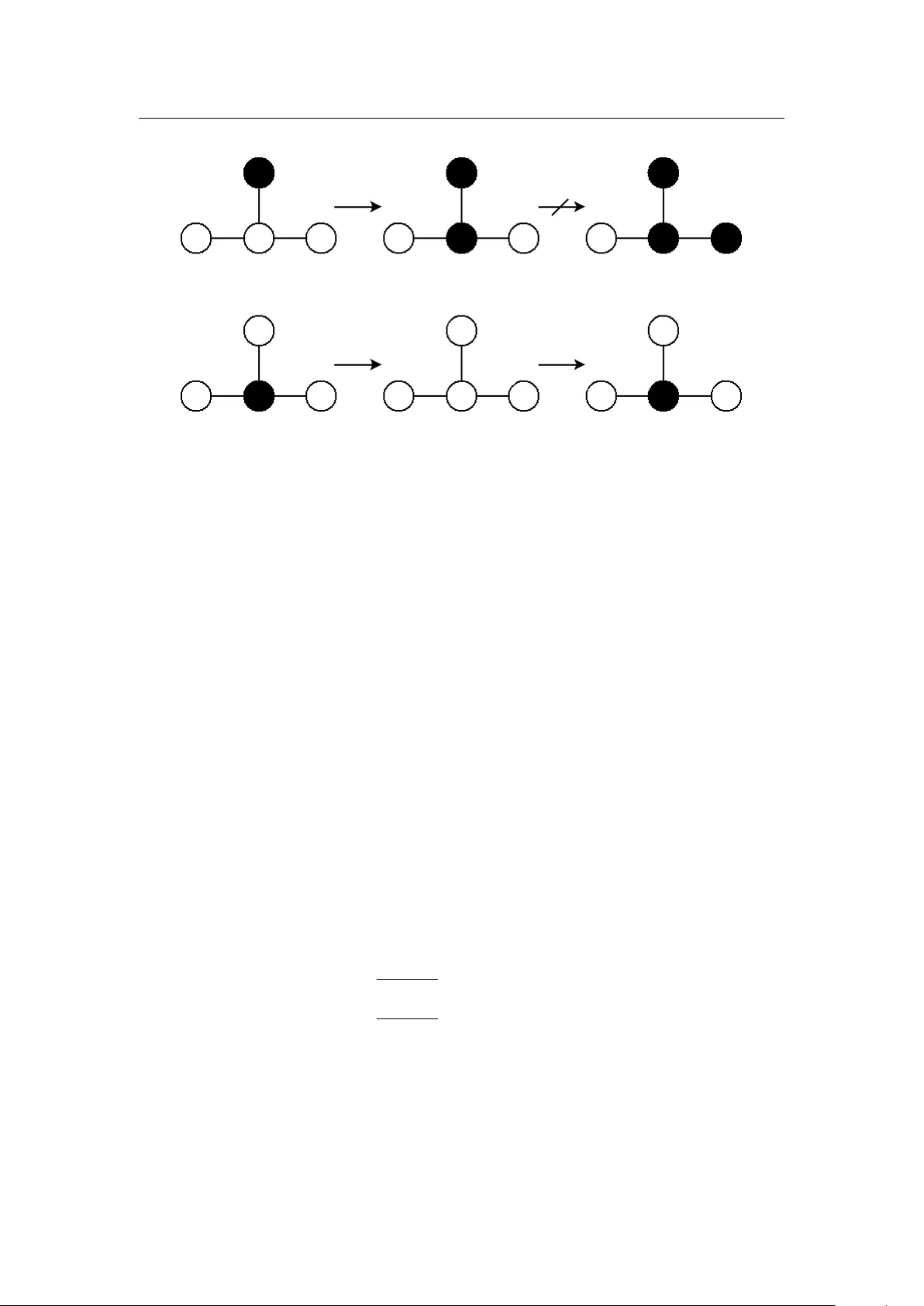
MCMC Louv ain for Online Comm unit y Detection Y v es Darmaillac ∗ 1,3 and Sébastien Loustau † 2,4 1 Lab oratoire de Mathématiques et de leurs Applications - UMR CNRS 5142, A v enue de l’Univ ersité, 64013 Pau cedex, F rance 3 Fluen t Data, 9 A v enue P asteur, 64260 Louvie Juzon, T witter : @fluen tdata 2 Lab oratoire Angevin de Rec herche en Mathématiques - UMR CNRS 6093, 2 Boulev ard Lav oisier, 49045 Angers Cedex 4 Artfact, T ec hnop ole Hélioparc, 2 A v enue du Presiden t Pierre Angot, 64000 Pau, T witter : @artfact64 Decem b er 6, 2016 Abstract W e in troduce a nov el algorithm of comm unity detection that maintains dynamically a comm unity structure of a large netw ork that ev olves with time. The algorithm maximizes the mo dularit y index thanks to the construction of a randomized hierarchical clustering based on a Mon te Carlo Mark ov Chain (MCMC) method. Interestingly , it could be seen as a dynamization of Louv ain algorithm (see [ 1 ]) where the aggregation step is replaced by the hierarc hical instrumen tal probabilit y . Con ten ts 1 In tro duction 2 2 Notations and preliminary study 2 2.1 Notations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 2.2 Metrop olis Hasting Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 2.3 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 3 Impro ved prop osal 5 3.1 Prop osal definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 3.2 Conditional probabilities . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 4 Aggregation 7 4.1 Metrop olis Hasting Algorithm with Hierarchical prior . . . . . . . . . . . . . 8 4.2 Mo dularit y gain . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9 4.3 Conditional probabilities . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10 5 Dynamic Metrop olis Hasting graph clustering 10 6 Conclusion and Ac kno wledge 11 ∗ yves.darmaillac@fluen tdata.info † artfact64@gmail.com 2016 Fluen t Data & Artfact 1 2 NOT A TIONS AND PRELIMINAR Y STUDY 1 In tro duction Comm unity detection has b ecome very p opular in netw ork analysis the last decades. Its range of applications include so cial sciences, biology and complex systems, such as the w orld- wide-w eb, protein-protein interactions, or social net works (see [ 5 ] for a thorough exp osition of the topic). T o tackle this problem, sp ectral approaches ha ve b een in tro duced in [ 12 ] or [ 18 ], inspired from the so-called sp ectral clustering problem (see [ 10 ]). How ever, the treatmen t of larger and larger graphs has b een inv estigated and mo dularit y-based algorithms has b een prop osed. This class of algorithms maximize a qualit y index called modularity , in tro duced in [ 13 ]. Unfortunately , exact mo dularit y optimization is NP-hard (see [ 2 ]) and b ecomes computationaly intractable for large net works. With this in min d, appro ximated solutions based on greedy searc h has been in tro duced, such as for instance [ 4 ], or more recently [ 1 ]. F or a complete comparison of recent methods against a benchmarks of graphs, w e refer to [ 6 ]. In this pap er, we introduce a mo dularit y-based algorithm that pro vides a clustering of a dynamic graph. Dynamic graph clustering is a difficult problem which consists in main taining dynamically a communit y structure suc h that at an y time, there is higher densit y of edges whithin groups than b et w een them. As far as w e know, this problem has b een p o orly treaten in the literature. [ 8 ] is the most serious attempt (see also the references therein), which pro vides dynamization of greedy search algorithms in tro duced in [ 4 , 1 ]. In the supervised case, [ 16 ] in vestigate online no des classification where lab els are correlated with the graph structure. It leads to algorithms based on p enalized empirical risks and gradien t computations. The philosophy b ehind this pap er is to maintain dynamically a Marko v Chain of hierar- c hical graphs and partitions that optimize the mo dularit y index. F or this purp ose, we use the Metrop olis Hasting (MH) algorithm, named after [ 11 ] and [ 9 ]. MH algorithms is the simplest and more v ersatile solution to construct a Marko v c hain asso ciated with a station- ary distribution (see [ 17 ] for a self-contained introduction with R co des). MH is one of the most general MCMC algorithms. Given a target density probability f , it requires a working conditional probability q also called proposal. The transition from the v alue of the Mark o v c hain at time k and its v alue at time t + 1 pro ceeds via 2 steps : generate a prop osal with la w q , and accept this prop osal with a suitable c hosen acceptance ratio. The computation of this ratio preserves the stationary density f without any assumption, and do not dep end on the prop osal distribution q . How ev er, in practice, the p erformance of the algorithm strongly dep ends on the choice of the transition q , the real issue of MCMC algorithms since some c hoices see the c hain unables to con vergence in a reasonable time. The pap er is organized as follows. In Section 2 , we introduce the first notations and describ e the modularity-based algorithm proposed in [ 1 ]. A first static Metropolis-Hastings (MH) algorithm is derived. It gives similar results than in [ 1 ], where each no de is visited sev eral times. In Section 3 and Section 4 , we propose improv ed versions of this static MH algorithm which combines lo cal changes and includes aggregation, in order to speed up con vergence. These considerations allow to construct a new comp etitiv e algorithm for static comm unity detection. Section 5 is dedicated to the dynamic v ersion of this algorithm, where w e observe a sequence of graphs that evolv es with time. Section 6 concludes the pap er with a short discussion. 2 Notations and preliminary study 2.1 Notations Let G = ( V , E ) an undirected and -p ossibly- w eighted graph where V is the set of N vertices or nodes and E the set of edges ( i, j ) , for i, j ∈ { 1 , . . . , N } . W e denote b y A ∈ M N ( R ) the 2016 Fluen t Data & Artfact 2 2.2 Metrop olis Hasting Algorithm 2 NOT A TIONS AND PRELIMINAR Y STUDY corresp onding symmetric adjacency matrix where entry A ij denotes the weigh t assigned to edge ( i, j ) . The degree of a no de i is denoted k i and m := | E | = 1 2 P i k i . W e call C ∈ C a c olor ation of graph ( V , E ) an y partition C = { c 1 , . . . , c k } of V where for any i = 1 , . . . , k , c i ⊆ V is a set of no des of G . Moreo ver, with a slight abuse of notation, C ( i ) ∈ { 1 , . . . , k } denotes the comm unity of v ertex i based on partition C . With thess notations, the mo dularit y C 7→ Q C of a giv en graph ( V , E ) is given by : Q C = 1 2 m X i,j ∈ V 2 A ij − k i k j 2 m δ C ( i ) , C ( j ) (1) where δ is the Kroneck er delta. Roughly speaking, mo dularit y compares fraction of edges that falls in to comm unities of C with its expected counterpart, given a purely random rewiring of edges which respect to nodes degrees ( k i ) i ∈ V . Maximization of ( 1 ) is NP-hard (see [ 2 ]), and heuristic appro ximation such as greedy search ma y suffer from local optima. Ho wev er, the v ariation of mo dularit y induced by lo cal mo o ve (suc h as moving an isolated no de into an existing communit y , or remov e one no de in an existing communit y to a single no de comm unity) can be easily computed. This fact is at the core of Louv ain algorithm (see [ 1 ]) and provides very fast graph clustering metho d. This algorithm iterates tw o phases : an optimization phase lets each no de moving to one of its neigh b ors’clusters, in order to maximize the mo dularit y index, whereas in the aggregation phase, each cluster is contracted to one node and edges w eights are summed. These t wo phases are iterated several times un til a stop criterion, and rev eal a hierarchical structure usefull in practice where natural organization are observed. 2.2 Metrop olis Hasting Algorithm In this subsection, instead of choosing the lo cal mo o v e which maximizes the modularity gain as in [ 1 ], we use the MH algorithm describ ed in Algorithm 1 below. Algorithm 1 MH for Communit y Detection 1: Initialization λ > 0 , C (0) . 2: F or k = 1 , . . . , N : 3: Draw C 0 ∼ p ( ·| C ( k − 1) ) where p ( ·| C ( k − 1) ) ∈ P ( N C ( k − 1) ) is the proposal distribution ov er N C ( k − 1) , a neighborho od of C ( k − 1) . 4: Update C ( k ) = C 0 with acceptance ratio : ρ = 1 ∧ r C ( k − 1) → C 0 exp λQ C 0 exp λQ C ( k − 1) , where r C → C 0 := p ( C ( k − 1) | C 0 ) /p ( C 0 | C ( k − 1) ) . (2) Algorithm 1 ab o ve satisfies the so-called detailed balance condition for an y prop osal p and then pro duces a Marko v c hain with inv arian t probability density f such that: f ( C ) dC ≈ exp λQ C dC. The ma jor issue is then to define a particular neighborho od N C and an idoine prop osal p ( ·| C ) in order to achiev e con vergence in a manageable time. In this section, w e prop ose a first attempt where neigh b orhoo d are local mo o ve inspired from [ 1 ] whereas the prop osal distribution takes adv antages of the edges structure of the observ ed graph. 2016 Fluen t Data & Artfact 3 2.2 Metrop olis Hasting Algorithm 2 NOT A TIONS AND PRELIMINAR Y STUDY Neigh b orho od definition In what follows, given C ∈ C , the neigh b orhoo d N C consists of all coloration C 0 equals to C except for one node i ∈ V . Then t wo cases arises: • i joins an existing communit y c ∈ C such that c 6 = C ( i ) , • a new single node comm unit y c new is created b y i . Prop osal distribution The construction of the prop osal distribution p ( ·| C ) ∈ P ( N C ) is based on t wo random choices : the c hoice of a node i ∈ V and the c hoice of a communit y c ∈ C thanks to an application Φ C : V × C → N C suc h that C 0 = Φ C ( i, c ) means that: • i joins an existing communit y c if ( i, c ) is such that c 6 = C ( i ) , • a new single node comm unit y is created b y node i if ( i, c ) is such that c = C ( i ) . In Algorithm 1 , the proposal distribution is then based on the previous mapping as follows: • W e first choose a no de i with discrete uniform probability ov er the set of no des V ; • Then w e c ho ose c = C ( j ) where j is c hosen with la w prop ortional to A ij , excluding the case j = i . T o deriv e C 0 , we use the application Φ C and state C 0 = Φ C ( i, C ( j )) . It is important to note that we exclude j = i ab o v e in order to a void iden tity mov e in Algorithm 1 . Indeed, if i = j and i is a single no de communit y , then C 0 ( i ) = C ( i ) and C 0 = C . W e are now on time to define prop erly the proposal distribution. Let us fixed a coloration C ∈ C . The proposal distribution is defined as follo ws: p ( C 0 | C ) = k C i,C ( i ) − A ii ( k i − A ii ) N if C 0 = Φ C ( i, C ( i )) , k C i,c ( k i − A ii ) N otherwise, (3) where for any no de i , w e denote by k C i,c the total weigh t of edges from no de i to communit y c as follo ws: k C i,c := X j ∈ V A ij 1 C ( j )= c . A cceptance ratio T o compute the acceptance ratio in ( 2 ), w e need to calculate the probabilit y p ( C | C 0 ) to come back. W e hav e: p ( C | C 0 ) = k C i,C 0 ( i ) ( k i − A ii ) N if C = Φ C 0 ( i, C 0 ( i )) , k C i,C ( i ) − A ii ( k i − A ii ) N otherwise (4) The first case corresp onds to the situation where i was initially isolated in a single node comm unity of C . Th us, the quantit y r C → C 0 in ( 2 ) is given by dividing ( 3 ) b y ( 4 ): r C → C 0 = p ( C | C 0 ) p ( C 0 | C ) = 1 if C 0 = Φ C ( i, C ( i )) or C = Φ C 0 ( i, C 0 ( i )) , k C i,C ( i ) − A ii k C i,c otherwise. 2016 Fluen t Data & Artfact 4 2.3 Results 3 IMPR OVED PR OPOSAL Change of modularity Last step is to compute the likelihoo d in ( 2 ). F or this purp ose, w e in tro duce the quan tity: ∆ Q C → C 0 := Q C 0 − Q C . It’s easy to see from ( 1 ) that when an isolated no de i joins an existing comm unity c ∈ C , w e ha ve: ∆ Q C → C 0 = ∆ Q C → C 0 + := 1 m X j ∈ V A ij − k i k j 2 m δ ( C ( j ) , c ) = 1 m k C i,c − k i k C c 2 m , (5) where k C c = P j ∈ V k j δ ( C ( j ) , c ) is the total weigh t of comm unity c ∈ C . Symmetrically , when a n ode i leav es its communit y C ( i ) to form a new single node comm unity: ∆ Q C → C 0 = ∆ Q C → C 0 − : = − 1 m X j ∈ V A ij − k i k j 2 m δ ( C ( j ) , C ( i )) = − 1 m k C i,C ( i ) − A ii − k i 2 m ( k C C ( i ) − k i ) (6) Note that in ( 1 ) every term is summed twice due to the symmetry of the adjacency matrix. This explains the 1 /m factor instead of 1 / 2 m in ( 5 ) and ( 6 ). Next, the c hange of mo dularit y incurred by our proposal is : ∆ Q C → C 0 = ( ∆ Q C → C 0 − if C 0 = Φ C ( i, C ( i )) ∆ Q C → C 0 − + ∆ Q C → C 0 + otherwise, (7) where we use in ( 7 ) the fact that if i joins an existing communit y , the change of modularity is equiv alent to adding a new single no de communit y with i and then mov e this single node comm unity to an existing communit y . This process has b een in tro duced in [ 1 ] and allows a faster computation and the treatmen t of large graphs. 2.3 Results Algorithm 1 with previous proposal and acceptance ratio achiev es the same kind of results than Louv ain, where the num b er of prop osals is roughly equals to the total num b er of inner lo op iterations ( b y testing mo dularit y gain for each edge) in [ 1 ]. The mo dularit y gain is sligh tly less and the num b er of comm unities is also sligh tly less than Louv ain. F or instance, w e ha ve tested our algorithm on arxiv data and obtained an a verage of 55 comm unities and a mo dularit y av erage of 0.810678. Standard Louv ain ([ 1 ]) ac hieves sligh tly b etter results with an av erage of 58 comm unities and a modularity av erage of 0.820934. 3 Impro v ed prop osal A ctually the prior prop osed in the previous section has tw o serious drawbac ks (see figure 1 ) : • in the situation describ ed by figure 1 upp er part, the second mov e will nev er be accepted b ecause the back prop osal has a probability of zero, • as communities grow and b ecome bigger, more prop ositions of new single node com- m unities that decrease modularity will occur, as shown in figure 1 lo wer part. 2016 Fluen t Data & Artfact 5 3.1 Prop osal definition 3 IMPR OVED PR OPOSAL Figure 1: T w o serious dra wbacks These considerations show slo w conv ergence of the Marko v c hain and motiv ate the in- tro duction of a b etter instrumen tal distribution. Indeed, to ov ercome the first drawbac k, the prop osal should b e able to allow a no de to join a communit y p oten tially far from it. T o o vercome the second one, it should hav e higher probability to explores node at the boundary of the current state C . F or that purp ose, given C ∈ C , we define a subset of V made of no des that hav e at least one edge in another comm unity as follo ws: F C := { i ∈ V : ∃ j ∈ V suc h that A ij > 0 and C ( j ) 6 = C ( i ) } . This subset of V is of particular in terest and our prop osition is to use a prop osal distribution based on a mixture of a fully randomized distribution and a well-c hosen distribution o ver the set F C . 3.1 Prop osal definition The prior p ( ·| C ) is defined as : p ( ·| C ) = αp 1 ( ·| C ) + (1 − α ) p 2 ( ·| C ) , (8) where α ∈ (0 , 1) and p 1 ( ·| C ) and p 2 ( ·| C ) are defined as follows : 1. p 1 ( ·| C ) is equiv alent to draw a first node i uniformly o v er V and a second one j uniformly among the others, 2. p 2 ( ·| C ) is equiv alent to draw a first no de i uniformly ov er F C and a second one j prop ortionally to k C i,C ( j ) with the constrain t C ( i ) 6 = C ( j ) . In b oth cases, to derive C 0 , we use the mapping Φ C and state C 0 = Φ C ( i, C ( j )) . In the sequel we denote by | c | the cardinality of communit y c based on coloration C (w e omit the dependence in C for ease of exp osition). Then, for any i ∈ V and any c ∈ C we ha ve for p 1 : p 1 ( C 0 | C ) = | C ( i ) | − 1 N ( N − 1) if C 0 = Φ C ( i, C ( i )) , | c | N ( N − 1) if C 0 = Φ C ( i, c ) for c 6 = C ( i ) , 2016 Fluen t Data & Artfact 6 3.2 Conditional probabilities 4 A GGREGA TION whereas for p 2 : p 2 ( C 0 | C ) = k C i,c |F C |K C ( i ) if K C ( i ) > 0 and c 6 = C ( i ) 0 otherwise where K C ( i ) = P ˜ c ∈ C k C i, ˜ c 1 C ( i ) 6 =˜ c . The addition of p 1 in ( 8 ) allows to construct a b etter mixing strategy and derive a more efficien t MH algorithm. Last step is to compute the conditional probabilities. 3.2 Conditional probabilities W e will no w compute p ( C 0 | C ) and p ( C | C 0 ) from ( 8 ). Given no de i ∈ V and a coloration C ∈ C , let us fix a coloration C 0 ∈ C and write c = C 0 ( i ) . Then w e ha ve: 1. If C ( i ) and c are not single node comm unities: p C 0 | C = α | c | C N ( N − 1) + (1 − α ) k C i,c |F C |K C ( i ) , p C | C 0 = α | C ( i ) | C 0 N ( N − 1) + (1 − α ) k C 0 i,C ( i ) |F C |K C 0 ( i ) = α | C ( i ) | C − 1 N ( N − 1) + (1 − α )( k C i,C ( i ) − A ii ) |F C | ( k i − k C i,c − A ii ) . (9) 2. If c is a single node comm unit y : p C 0 | C = α ( | C ( i ) | C − 1) N ( N − 1) , p C | C 0 = α | C ( i ) | C 0 N ( N − 1) + (1 − α ) k C 0 i,C ( i ) |F C |K C 0 ( i ) = α | C ( i ) | C − 1 N ( N − 1) + (1 − α )( k C i,C ( i ) − A ii ) |F C | ( k i − A ii ) . (10) 3. If C ( i ) is a single node comm unity : p C 0 | C = α | c | C N ( N − 1) + (1 − α ) k C i,c |F C |K C ( i ) , p C | C 0 = α ( | c | C 0 − 1) N ( N − 1) = α | c | C N ( N − 1) . (11) Finally we are able to compute r C → C 0 in ( 2 ). 4 Aggregation Aggregation ma y accelerate conv ergence when communities are "big", i.e. when there is notably less communities than nodes. Aggregation consists of building a new graph which no des are the comm unities of the former graph. This principle is adopted in [ 1 ] in the second phase of eac h pass after the optimization step as described in Section 2 . In what follo ws, we prop ose to construct a MH type algorithm as in Section 3 , where aggregation is included in the prop osal distribution in order to accelerate con vergence. 2016 Fluen t Data & Artfact 7 4.1 Metrop olis Hasting Algorithm with Hierarc hical prior 4 A GGREGA TION 4.1 Metrop olis Hasting Algorithm with Hierarc hical prior In our framework, w e prop ose to use the same kind of prior than ( 8 ) to a family of aggregated graphs in order to mov e entire communities rather than a single no de. T o ac hiev e this, we in tro duce a set of hierarc hical graphs and hierarc hical priors as follo ws. Let G = ( V , E ) an undirected and -possibly- weigh ted graph where V = { 1 , . . . , N } is the set of N vertices or no des and E is the set of edges ( i, j ) , for i, j ∈ { 1 , . . . , N } . Let L ≥ 1 an in teger. The construction of a family of aggregated graphs ( E l , V l ) L l =1 is done iteratively as follo ws. Let G 1 := ( E 1 , V 1 ) = ( E , V ) . Then, given G l for 1 ≤ l ≤ L − 1 , we define a ( l + 1) th aggregated graph as G l +1 = ( E l +1 , V l +1 ) where V l +1 := { v ( l +1) 1 , . . . , v ( l +1) N l +1 } is a partition of V l and E l +1 is computed thanks to G l as the follo wing aggregation step: 1. if i 6 = j , the edge betw een v ( l +1) i and v ( l +1) j in G l +1 is equal to the sum of all edges b et w een nodes of G l con tained in v ( l +1) i and no des of G l con tained in v ( l +1) j , 2. if i = j , loop i in E l +1 is equal to the sum of all edges b et w een nodes of G l con tained in v ( l +1) i . Moreo ver, W e denote by A ( l ) ∈ M | V l | ( R ) the corresp onding symmetric adjacency matrix where entry A ( l ) ij denotes the w eight assigned betw een v ertices v ( l ) i and v ( l ) j in G l . The degree of a no de i is denoted k ( l ) i and m l := | E l | = 1 2 P i k ( l ) i . W e call C l ∈ C l a c olor ation of lev el l of graph G l an y partition C l = { c 1 ,l , . . . , c k,l } of V l where for any i = 1 , . . . , k , c i,l ⊆ V l is a set of no des of G l . Moreo ver, C l ( i ) denotes the communit y of vertex i based on C l . Moreo ver, we denote b y map C l : V ( l ) → V ( l +1) the mapping of all nodes of G l in G l +1 that groups all nodes of a same communit y according to C l in a single no de of G l +1 . F or instance, if for some i w e ha ve c i,l = { v ( l ) 1 , . . . , v ( l ) r } , then map C l ( v ) = map C l ( v 0 ) for an y v , v 0 ∈ c i,l . Finally , the decision to find the communit y of i ∈ V thanks to ( C l , G l ) L l =1 is made of the follo wing computation: C ( i ) := C L map C L − 1 ◦ · · · ◦ map C 1 ( i ) , where C L ( v ) stands for the comm unity of v ∈ V ( L ) . Under these notations, we can define the family of priors ( p ( l ) ( ·| C l , G l )) L l =1 where each p ( l ) ( ·| C l , G l ) is defined in ( 8 ) and acts on the graph of level l from l = 1 (the original graph) to l = L (the highest level of aggregation). Endow ed with this family of hierarchical priors, the prop osal distribution is defined on P ( ⊗ L l =1 C l ) as follo ws: p ( C 0 | C ) = L X l =1 α l p ( l ) ( C 0 l | C l , G l ) , for an y C 0 = ( C 1 , . . . , C l ) ∈ ⊗ L l =1 C l , (12) where P l α l = 1 whereas C = ( C 1 , . . . , C L ) and C 0 = ( C 0 1 , . . . , C 0 L ) con tain colorations of graphs at differen t lev els. The principle of this new MH algorithm is illustrated in Algorithm 2 and maintain the family ( C l , G l ) L l =1 thanks to ( 12 ). In 5: ab o ve, if C 0 has used the l th prior p ( l ) for some l = 1 , . . . , L , we up date graphs G ( k ) k 0 , k 0 = l + 1 , . . . , L as follows: 1. if i and j b elong to differen t communities in C ( k ) l , i is re-mapp ed to the same no de than j in G ( k ) k 0 , k 0 = l + 1 , . . . , L . 2. if i and j b elong to the same comm unity in C ( k ) l , i is re-mapp ed to a new single no de comm unity in G ( k ) k 0 , k 0 = l + 1 , . . . , L . 2016 Fluen t Data & Artfact 8 4.2 Mo dularit y gain 4 A GGREGA TION Algorithm 2 Hierarchical MH Comm unity Detection 1: Initialization λ > 0 , L ≥ 1 , ( G (0) l , C (0) l ) L l =1 . 2: F or k = 1 , . . . , N : 3: Draw C 0 ∼ p where p ( ·| C ( k − 1) l , G ( k − 1) l ) ∈ P ( ⊗ L l =1 C l ) is defined in ( 12 ). 4: If C 0 has b een prop osed by the l th prior p ( l ) for some l = 1 , . . . , L update C ( k ) = C 0 with Metrop olis ratio : ρ = 1 ∧ r C ( k − 1) → C 0 exp λQ C 0 l exp λQ C ( k − 1) l , where r C ( k − 1) → C 0 := p ( C ( k − 1) l | C 0 l ) /p ( C 0 l | C ( k − 1) l ) . (13) 5: If C 0 has b een accepted and has used the l th prior p ( l ) for some l = 1 , . . . , L , maintain ( G k 0 ) L k 0 = l +1 as follows: 6: F or k 0 = l, . . . , L − 1 7: Update V k 0 +1 thanks to map C ( k ) k 0 , 8: Update E k 0 +1 thanks to the aggregation step define ab o ve. 4.2 Mo dularit y gain In Algorithm 2 , sev eral states of prop osals C 0 lead to the same coloration { C 0 ( i ) , i ∈ V 1 } . The choice of C 0 based on p ( l ) ma y lead to the situation where C 0 k = C k for k = l ∗ , . . . , L for some l < l ∗ ≤ L and this results in C ( i ) = C 0 ( i ) for an y i ∈ V 1 . F or instance this happens if C k is a single communit y that con tains all nodes for k = l ∗ , . . . , L and if the p roposal at lev el l doesn’t create a new communit y . As a consequence, if for C = ( C 1 , . . . , C L ) and C 0 = ( C 0 1 , . . . , C 0 L ) w e ha ve C L = C 0 L , the real mo dularit y gain for this mo ve is actually 0. If l = L then 5 , 6 and 7 apply . If l < L and C L 6 = C 0 L the mo dularit y c hange by moving no de i is given by the following form ulas. First, let us introduce the following notation : C L,l ( i ) := C L map C L − 1 ◦ · · · ◦ map C l ( i ) If l < L and C L 6 = C 0 L the mo dularit y gain by moving no de i is given by : • If no de i joins an existing communit y at lev el l then at level L the mo dularit y held by the communit y c = C 0 L,l ( i ) will b e mo dified b y the following quantit y : ∆ Q C → C 0 + = 1 m X j ∈ V A ( l ) ij δ ( C L,l ( j ) , c ) ! − k ( l ) i k C L c + 1 2 k ( l ) i 2 m . The same formula applies if i joins a new single no de communit y at level l whic h implies the creation of a new no de in its o wn comm unity c at level L . • When i leav es its communit y at level l , the mo dularit y held by the communit y C L,l ( i ) will b e mo dified by the follo wing quan tity : ∆ Q C → C 0 − = − 1 m X j ∈ V A ( l ) ij δ ( C L,l ( j ) , C L,l ( i )) ! − k ( l ) i k C L C L,l ( i ) − 1 2 k ( l ) i 2 m Finally we use the formula ∆ Q C → C 0 = ∆ Q C → C 0 + + ∆ Q C → C 0 − . 2016 Fluen t Data & Artfact 9 4.3 Conditional probabilities 5 D YNAMIC METROPOLIS HASTING GRAPH CLUSTERING 4.3 Conditional probabilities The calculus of r C → C 0 in ( 14 ) follows Section 3 . The only difference is the hierarchical prior defined in ( 12 ). Then, given a state C = ( C 1 , . . . , C L ) and a proposal C 0 = ( C 0 1 , . . . , C 0 L ) , the probability to come back is giv en b y: p ( C | C 0 ) = α l 0 p ( l 0 ) ( C l 0 | C 0 l 0 , G l 0 ) , where l 0 is the lev el c hosen b y C 0 and p ( l 0 ) ( C l 0 | C 0 l 0 , G l 0 ) is defined in subsection 3.2 applied to the aggregated graph G l 0 . 5 Dynamic Metrop olis Hasting graph clustering The purp ose of this section is to adapt the previous algorithm to the dynamic graph clus- tering problem. The c hallenge is to main tain a clustering for a sequence of graphs ( G t ) t ≥ 1 , where G t is deriv ed from G t − 1 b y applying a small n umber of lo cal changes. This problem has b een prov en to b e NP-hard (see[ 8 ]) and several authors has tried to prop ose dynamic clustering algorithms. [ 7 ] prop oses a dynamization of the minimum-cut trees algorithm and allo ws to k eep consecutiv e clustering similar. More recen tly , [ 8 ] proposes heuristics for dynamization of greedy search algorithms of [ 2 ] and [ 1 ], where at eac h time t , a so-called preclustering decision is passed to the static algorithm. In a prediction framework, [ 16 ] prop oses to deriv e online no des classification algorithms based on a general minimax analysis of the so-called regret (see also [ 14 ]). In this problem, no des hav e asso ciated lab els that could be correlated with the topology of the graph edges. Sev eral techniques are prop osed, based on a con vex relaxation of the problem and also the use of surrogate losses (see [ 15 ]). Algorithm 3 describes the online procedure. Coarselly sp eaking, the principle of the algorithm is to run at each new observ ation t Algorithm 2 from the endpoint of step t − 1 . The choice of N ( t ) dep ends on the frequency of the sequence ( G t ) t ≥ 1 and the execution time of Algorithm 2 . W e recommend to run Algorithm 2 until a new incoming observ ation arriv es. Algorithm 3 Online MH Communit y Detection 1: Initialization λ > 0 , L ≥ 1 , ( G (0 , 0) l , C (0 , 0) l ) L l =1 , N (0) = 0 . 2: F or t = 1 , . . . , T : 3: ( C ( t, 0) , G ( t, 0) ) := ( C ( t − 1 ,N ( t − 1)) , G ( t − 1 ,N ( t − 1)) ) 4: F or k = 1 , . . . , N ( t ) : 5: Draw C 0 ∼ p where p ( ·| C ( t,k − 1) l , G ( t ) l ) ∈ P ( ⊗ L l =1 C l ) is defined in ( 12 ). 6: If C 0 has b een prop osed by the l th prior p ( l ) for some l = 1 , . . . , L update C ( t,k ) = C 0 with Metrop olis ratio : ρ = 1 ∧ r C ( t,k − 1) → C 0 exp λQ C 0 l exp λQ C ( t,k − 1) l , where r C ( t,k − 1) → C 0 := p ( C ( t,k − 1) l | C 0 l ) /p ( C 0 l | C ( t,k − 1) l ) . (14) 7: If C 0 has b een accepted and has used the l th prior p ( l ) for some l = 1 , → , L , maintain ( G k 0 ) L k 0 = l +1 as follows: 8: F or k 0 = l, . . . , L − 1 9: Update V k 0 +1 thanks to map C ( t,k ) k 0 , 10: Update E k 0 +1 thanks to the aggregation step define ab o ve. In 7: ab o ve, if C 0 has used the l th prior p ( l ) for some l = 1 , → , L , we up date graphs G ( t,k ) k 0 , k 0 = l + 1 , . . . , L as follows: 2016 Fluen t Data & Artfact 10 REFERENCES 1. if i and j b elong to differen t communities in C ( t,k ) l , i is re-mapp ed to the same no de than j in G ( t,k ) k 0 , k 0 = l + 1 , . . . , L . 2. if i and j b elong to the same communit y in C ( t,k ) l , i is re-mapp ed to a new single no de comm unity in G ( t,k ) k 0 , k 0 = l + 1 , . . . , L . 6 Conclusion and A c knowledge In this pap er, we prop ose an online communit y detection algorithm based on a dynamic optimization of the modularity . Our metho d appears to be a dynamization of [ 1 ] and uses a Metrop olis Hasting form ulation. In a batc h setting, the giv en algorithm shows practical results comparable to the so-called Louv ain algorithm introduced in [ 1 ]. How ever, we omit arbitrary decisions suc h as the time to aggregate, the num b er of aggregations or the order of observ ations of the no des in the first pass of Louv ain. More precisely , we introduce a well-c hosen instrumental measure in the MH paradigm in order to include aggregation in the prop osal moov es. A precise calculation of the conditional probabilities, as well as mo dularit y deviations, allows to construct a suitable Mark ov chain with ergodic properties. Finally , this MCMC version of Louv ain allows to build coarselly an online version where comm unities are constructed in an online fashion. Exp erimen ts ov er simulated graphs (such as preferen tial attac hment models P A( n ), or preferen tial attac hment mo del with seeds, see [ 3 ]) as w ell as real-world graph databases ( see The Koblenz Netw ork Collection for instance) are in progress. A dynamic and interactiv e visualization using a recent ja v ascript framework D3.js is also coming up to illustrate the output of the algorithm in real time. This w ork falls into a pro ject of open innov ation betw een tw o french startups Fluent Data and Artfact, and is supp orted b y the F rench go vernmen t under the lab el Jeune En treprise Inno v ante (J.E.I.). References [1] Vincent D Blondel, Jean-Loup Guil la ume, Renaud Lambiotte, and Etienne Lefebvre. F ast unfolding of comm unities in large netw orks. Journal of statistic al me chanics: the ory and exp eriment , 2008(10):P10008, 2008. [2] Ulrik Brandes, Daniel Delling, Marco Gaertler, Rob ert Gork e, Martin Ho efer, Zoran Nik oloski, and Dorothea W agner. On mo dularit y clustering. IEEE T r ans. on Know l. and Data Eng. , 20(2):172–188, F ebruary 2008. [3] Sébastien Bubeck, Elc hanan Mossel, and Miklós Z Rácz. On the influence of the seed graph in the preferen tial attachmen t mo del. IEEE T r ansactions on Network Scienc e and Engine ering , 2(1):30–39, 2015. [4] Aaron Clauset, M. E. J. Newman, and Cristopher Mo ore. Finding communit y structure in very large net works. Phys. R ev. E , 70:066111, Dec 2004. [5] S. F ortunato. Communit y detection in graphs. Physics R ep orts , 486 (3):75–174, 2010. [6] Santo F ortunato and Andrea Lancic hinetti. Communit y detection algorithms: A com- parativ e analysis: Invited presentation, extended abstract. In Pr o c e e dings of the F ourth International ICST Confer enc e on Performanc e Evaluation Metho dolo gies and T o ols , V ALUETOOLS ’09, pages 27:1–27:2, ICST, Brussels, Belgium, Belgium, 2009. ICST (Institute for Computer Sciences, So cial-Informatics and T elecomm unications Engineer- ing). 2016 Fluen t Data & Artfact 11 REFERENCES REFERENCES [7] Rob ert Görke, T anja Hartmann, and Dorothea W agner. Dynamic Gr aph Clustering Using Minimum-Cut T r e es , pages 339–350. Springer Berlin Heidelberg, Berlin, Heidel- b erg, 2009. [8] Rob ert Görke, P ascal Maillard, Christian Staudt, and Dorothea W agner. Mo dularit y- driv en clustering of dynamic graphs. In Pr o c e e dings of the 9th International Confer- enc e on Experimental Algorithms , SEA’10, pages 436–448, Berlin, Heidelberg, 2010. Springer-V erlag. [9] W Keith Hastings. Mon te carlo sampling methods using mark ov c hains and their applications. Biometrika , 57(1):97–109, 1970. [10] Ulrike Luxburg. A tutorial on sp ectral clustering. Statistics and Computing , 17(4):395– 416, December 2007. [11] Nicholas Metrop olis, Arianna W Rosen bluth, Marshall N Rosen bluth, Augusta H T eller, and Edw ard T eller. Equation of state calculations by fast computing machines. The journal of chemic al physics , 21(6):1087–1092, 1953. [12] M. E. J. Newman. Finding communit y structure in net works using the eigenv ectors of matrices. Phys. R ev. E (3) , 74(3):036104, 19, 2006. [13] Mark EJ Newman and Michelle Girv an. Finding and ev aluating communit y structure in netw orks. Physic al r eview E , 69(2):026113, 2004. [14] Alexander Rakhlin, Ohad Shamir, and Karthik Sridharan. Relax and randomize: F rom v alue to algorithms. In A dvanc es in Neur al Information Pr o c essing Systems , pages 2141–2149, 2012. [15] Alexander Rakhlin and Karthik Sridharan. Efficien t multiclass prediction on graphs via surrogate losses. 2016. [16] Alexander Rakhlin and Karthik Sridharan. A tutorial on online sup ervised learning with applications to node classification in social net works. CoRR , abs/1608.09014, 2016. [17] Christian P Rob ert. The metrop olis–hastings algorithm. Wiley StatsR ef: Statistics R efer enc e Online . [18] Scott White and P adhraic Smyth. A sp ectral clustering approach to finding communi- ties in graphs. In In SIAM International Confer enc e on Data Mining , 2005. 2016 Fluen t Data & Artfact 12
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment