Development of a hybrid learning system based on SVM, ANFIS and domain knowledge: DKFIS
This paper presents the development of a hybrid learning system based on Support Vector Machines (SVM), Adaptive Neuro-Fuzzy Inference System (ANFIS) and domain knowledge to solve prediction problem. The proposed two-stage Domain Knowledge based Fuzz…
Authors: Soumi Chaki, Aurobinda Routray, William K. Mohanty
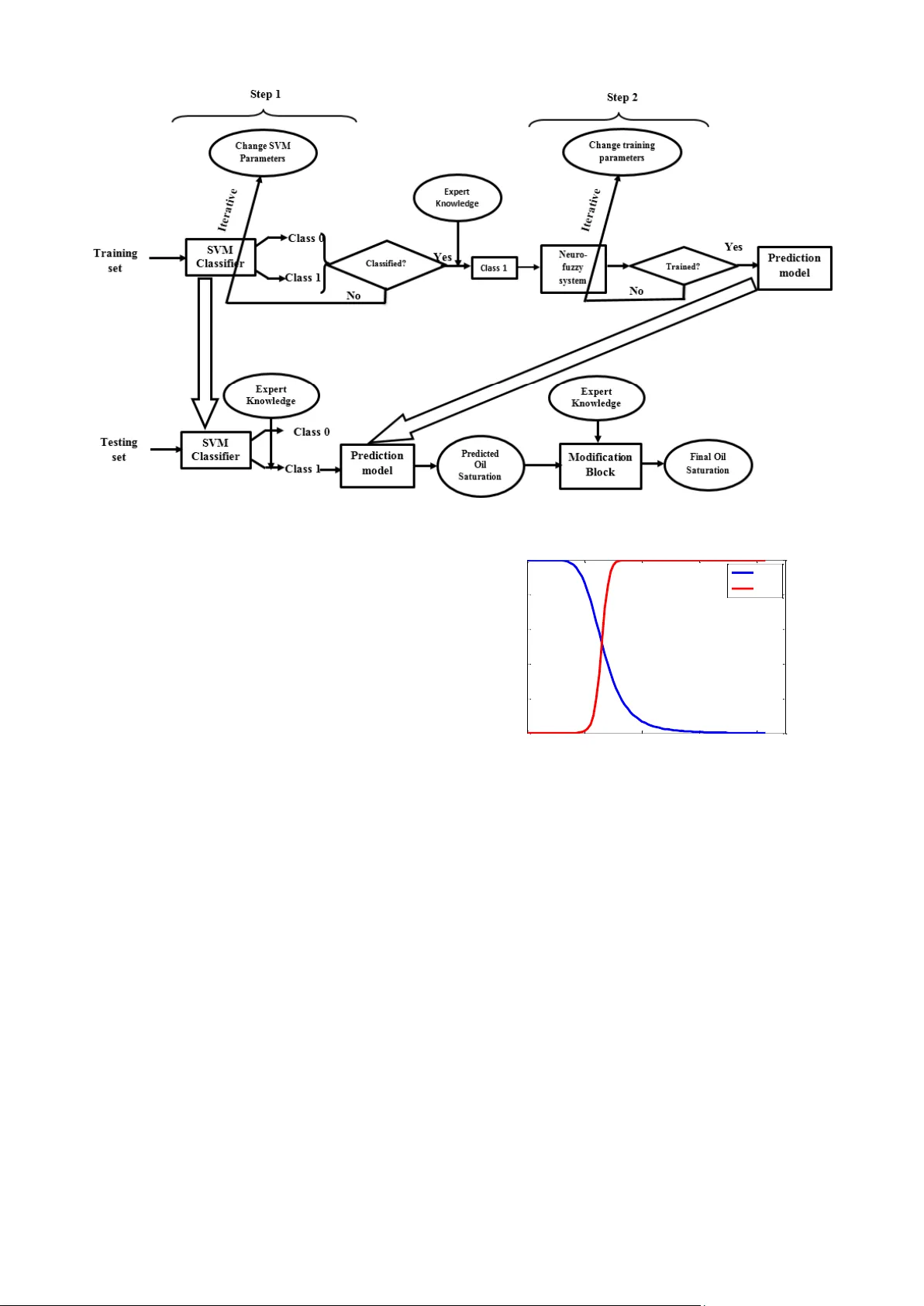
This paper was presented at Indicon 20 15 at New Delhi, India Development of a hybrid learning system based on SVM, ANFIS and domain knowledge: DKFIS Soumi Chak i 1 , Aurobinda Routray 1 , William K. Mohanty 2 , Mamata Jenam ani 3 1 Department of Electrical E ngineering, IIT Kharagpur, India soumibesu2008 @gmail.com aroutray@ee.iitkgp.ernet.i n 2 Department of Geolo gy and Geophysics, IIT Kharagpur, India wkmohanty@gg.iitkgp.er net.in 3 Department of Industrial and Systems Engineering, IIT Kharagpur, India mj@iem.iitkgp.ernet.in Abstract — This p aper presents the d evelopment of a h ybrid learning system based on Support Vector M achines (SVM) , Adaptive Neuro-Fuzzy In ference System (ANFIS) and domain knowledge to so lve prediction problem. The proposed tw o-stage Domain Knowledge b ased Fu zzy Inform ation System (DKFIS) improves the prediction ac curacy attained by ANFIS a lone. Th e proposed framework has been implemented on a noisy and incomplete dataset acquired from a hydrocarbon field located at western part o f India . Here, oil satura tion ha s be en predicted from f our differen t well logs i. e. gamm a ray, resistivity, density, and clay v olume. In the first stage, depending on zero or near zero and non-zero oil saturation levels the input vector is classified into two classes (Class 0 and Class 1) using SVM. The classification r esults have been fu rther fine-tuned a pplying expert knowledge based on the relationship among predictor variables i.e. well logs and target variable - oil saturation. Second, an ANFIS is designed to predict non-zero (Class 1) oil satur ation values fr om predictor logs . The predicted output has b een further refined based on expert knowledge. It is appa rent fro m the experimental results that the expert intervention with qualitative judgment at each stage has re nder ed the prediction into the feasible and realistic ranges. The perfor mance analysis of the p rediction in ter ms o f four p erformance metrics such as correlation coe fficient (CC), root m ean square error (RMSE), and absolute error mean (AEM), scatter index (SI) has established DKFIS as a useful tool for reservoir char acterization. Keywords — Support Vector Machine (SVM), Adaptive Neuro- fuzzy Inference S ystem (ANFIS), knowledge base, Domain Knowledge ba sed Fuzzy Information System (DKFIS) , qualitative learning, g-metric means, performance metrics. I. I NTRODUCTI ON The design of an appropriate framew ork includes the selection of appropriate pre-processin g and learning algorithm s. On the other hand, selection of relevant algorithm s requires inform ation on the dataset and domain knowledge related to the problem . Therefore, devising an efficient framew ork is a tw o-way pro cess. First, the algorithms are selected based on dataset characteris tics, literatu re review , and scope to inco rporate machine learning algorithm s to address the problem. Then, the parameters associated with the learning algorithm s can be tuned depending upon the perform ance obtained from the designed framew ork. Thus, the fram ework is finalized iterativ ely and a pplie d. This study reveals design steps of an advanced prediction framew ork namely DKFIS which is a fusion of SVM, ANFIS, and domain knowledge . Then, the designed framework is implem ented on a noisy and incomplete geologi cal dataset to solve a real-world problem i.e. prediction of oil saturati on fr om multiple well logs. T herefo re, knowledge on the reserv oir character ization domain such as inherent r elations hip betw een lithologi cal characte ristics and well logs has been utilized to assist th e predicti on alg orithms. Predicting reservoi r propertie s from well logs [1] – [4] and seismic att ributes [5] – [7] is a well-know n problem. The main target properti es includ e poro sity, permeability , oil saturati on etc. It has been found in existing literatu res that gamma ray , resistivity , density , and s onic logs have been u sed as predictor variables in [8] – [10]. However, the choice o f predictor variables also dep ends on av ailabilit y of th e dataset . The soluti on approach es for the prediction problem under considera tion include use of various soft-com puting tools such as Artificial N eural Netw ork (ANN), Fuzzy Logic and Genetic Algorithm s (GA) and several hybrid alg orithm s . Fo r exam ple, to predict pe rmeability Improved Fuzzy Neural Network (IFNN) based on a g radient descent Fuzzy algor ithm [11], and GA w ith Neuro-Fuzzy techniqu es [12], [13] have been used in the p ast. The perform ance of a particular technique depends on nature of the dataset. T hough, attempts have been made to use novel machine learning techniques in search of better solution, sometim es relatively older techniques produce better or comparable solut ion with redu ced com putational com plexity compared to their recent counterparts. For example, both ANN and ANFIS has been use d to estimate lithological properties from w ell logs in [14] – [ 16] yielding ac ceptable results. Apart from the commonly used approaches , sometim es relativ ely uncomm on methods are also selected to predict lith ologi cal properties . For example, the oil saturati on has been estimated from car bon/ oxy gen logs usin g Monte C arlo m ethod in [17] . The litera ture re ports con siderab le research in the applicati ons o f a w ide va riety of m ethods s tartin g f rom statistic al regression to soft computing for m odeling various paramete rs related to reservoir. Neur al Netw ork, Fuzzy Logic and Neur o-Fuzzy methods have been very popular in reservoi r character ization in presence of uncertain and inc omplete d ata. These methods predominantly use statisti cal and data intensive machin e learning tools. T ypic ally, these algorithm s suffer from This paper was presented at Indicon 20 15 at New Delhi, India the curse of dim ensionality . There are still lot of gap areas which needs immediate attention. In this p aper, we hav e taken up the foll owing research issu es. a. Learning in pres ence of s parse an d unevenly dist ributed data b. Inclusion of b oth quantitat ive and qualita tive domain knowledge The w ell log d ata are g enerated fr om a complex, heterogen eous and non-lin ear system . So metim es , measurem ent error and noise deteriorate the quality o f the dataset. The choice of machine learning method and thereby predicti on accur acy is gre atly dependent on the dat a-set. In most cases prepro cessing is carrie d o ut before using the predicti on model. T he sele ction of p roper p re-processin g algorithm s improv es the perform ance o f machin e learnin g algorithm s to a great exten t. Therefore, it is essentia l to analy ze the natur e of the workin g d ataset and carry out suitable pre - processing before ente ring in to pr ediction st age. For example, regulari zation schem e in pre-processing stage has improve d the predicti on capabili ty of ANN as in [18] . Simila rly, normaliz ation, relevant attribu te selecti ons have been carried out to improve the perf ormance of the classificat ion framew ork in [9] . In another domain [19], [20], band pass filtering has been used to remove artifacts from raw EE G data foll owed b y normaliz ation in pre-proces sing stage . The s election of ap propria te parameters of the pre-processin g techniques ar e dependent on the use r. Therefore, kn owledge on the d ataset character istics an d the proble m are essential t o select the pre- processing algorith ms and associated param eters wis ely; which in turn is vi tal for p erform ance of the learnin g framework. This realizati on has inspi red the inclusion o f expert know ledge explicitly in the process while designin g the framework in this study. Often the models gener ated using d ata-driven meth ods produce infeasi ble re sults when the trainin g set is not dense enough. Under such circumstan ces the model turns out to be ill -condi tioned and may yield unacceptab le and random results. Expert judg ment is necess ary to m ake qualitative assessmen t of the fidelity of the result and m odify them if necessary. Methods are availa ble to incorporat e domain know ledge into models generated primarily f rom d ata-driven methods. A concept of ‘Qfilt er’ to achieve ‘qualitative ly faithful numerical predicti on’ is sug gested by Suc et al . [21], [22] . In this paper, we propose a new approach to estimate oil saturati on u sing four pr edictor variables i.e. gamma ray, resistivity , density , and clay f raction. The d ataset under t he study area is highly skew ed in nature in the sense that around 93.55% of the patterns carry zero oil saturat ion level, which is quite comm on in fields producing depleting quantity of hydrocar bon. T his dataset is observed to be imprecise an d unreliable in the sense that alm ost all patte rns correspond to a particula r well in this datase t carry ze ro oil s aturati on level only, which makes it d ifficul t to solely depend on the result of predicti on model. To circum vent to this problem w e use a tw o stage model. In the 1st stage, a SVM based classif ier is trained to group the inputs that correspon ds to the zero and non-zero oil saturation values . In the 2nd stage, a c ontinuous Neuro - Fuzzy pre dictor w hich is used t o prec isely es timate only n on- zero oil-satu ration. We have used d omain kn owledge afte r each stage to fine tu ne the prediction results f or making them more realistic . Our approach is mostly suitable for sparse and unevenly distribute d datasets where the output is clustered around few classes. In this case the output, oil satura tion values are predomin antly zero. Thus there is a very small representa tive training sets from the non-zero class to build the predicti on model. Under these circumstances the dom ain knowledge is helpful in correcting the pred ictive m odels. The SV M is used to separate the pattern s into two classes zero (Cl ass 0) and non- zero (Class 1). The patterns corres ponding to non-zero oil saturati on values are used to train an A NFIS. A Fuzzy Inference System (FIS) is designed using the domain knowledge (say it Domain Knowledge based FIS ( DKFIS)) . DKFIS is ap plied to th e output s of both th e stag es to vali date or suitably modify them. The d ataset consists of well-logs such as gamm a ray, resistivity , density, clay fraction and the correspon ding oil- saturation. The contri bution of the p aper can be outlin ed as f ollow s: a) Design of a tw o stage machine learning sys tem for classify ing and th en predi cting th e oil satu ration values b) T he use of DKFIS to im prove the pr edicti on results The rest of th e paper is st ructured as follow s: we first give a brief description of the ANFIS; next an overview of classifi cation based on SVM is provide d; a brief discussion on the concept of qualitative learnin g and Qfilte r is given in the section follow ing. T hen, we d escribe the dataset and knowledge base used in this study . Next, the propos ed two-step methodology to model o il saturation from input logs and lithology log is describ ed. In the fol lowing secti on, experim ental r esults obtaine d by the proposed algorithm on current dataset is reported. Finally, the paper conclu des with future s cope of the cur rent stu dy. II. Q UALITA TIVE L EARNING The prediction accuracy o f numerical learning models should be c onsistent with qualit ative dom ain know ledge. A concept o f numeri cal regression meth od namely ‘Qfilte r’ as in [21], [22] is use d here to in tegr ate domain knowledge with predicti on accu racy. A set of qualita tive constrain ts de rived from dom ain know ledge of a specif ic applic ation is p rovided as input to ‘Qfilter’ along with numerical patterns. In contrast, ‘Qfilter’ c an be ap plied within ‘Q2’ l earning . F or the la tter case, no expert given qualita tive constraints is required. In case of ‘Qfilter’, a qualitative tree is d escribe d w hich represents the relation between input att ributes and class using Qualita tively Constraine d Functions (QCF). QCF is said to be co nsistent if it is consistent with all possible example pairs. It can be said that ‘Qfilter’ is a filter which filters the qualitative errors caused by measurem ent errors. ‘Qfilter’ obtains improved accuracy consistently over standard regression models such as Locally Weighted Regress ion (LWR) irrespectiv e of number o f available patterns and noise level in the dataset. I n this pa per, the Qfilter is implemente d as an FIS; thus the co mplete DKFIS framew ork is desig ned. This paper was presented at Indicon 20 15 at New Delhi, India III. D ESCRIPTI ON OF THE D ATASET In th is s tudy, w ell log data fr om f our clos ely spaced w ells placed in Indian onshore are used; henceforth these wells to be referre d as A, B, C, and D respectively . T he input logs used in this study are gamm a ray, resistivity , density , and clay volume. For this particul ar dataset, the target variable i.e. oil s aturati on value h as a rang e of 0 to 0.8 6 w ith m ean and variance o f 0.0391 and 0.0124 per un it respectively . Histog ram plot of oil saturati on is presented in Fig. 1. It can be ob serv ed that a large number of d ata points corres ponds to zero oil satura tion value. Therefore , the classific ation of dataset depending on zero (Class 0) and non-zero o il saturation level ( Class 1) is desirable . Table I represent s the expert knowledge base provided for this study analy zing the workin g datas et. Table I represents the expert know ledge base provided for this study analyzin g the workin g datase t. 0 0.2 0.4 0.6 0.8 0 2000 4000 6000 Oil-Sa turati on Number of Occurren ce Fig. 1. The range distribution of oil sa turation TABLE I . E XPERT KNOWLEDGE BASE R1 : if then R2 : if < gamma ray is high, resistivity is high, density is high, and clay vol ume is low > then R3 : if < gamma ray is low, resistivity is medium, density is low, and clay volume is low > then IV. M ETHODOL OGY First, the predicto r variables e.g. gamma ray, resistivity etc. are norm alized usin g z-score normaliz ation as: me an nor ma liz ed stan dar d de vi atio n GR - GR GR = GR (1) In contrast, the target varia ble is normalized in [0 1] range using m in-max normalizati on which ess entially performs a linear transform ation. T he relationships among the origin al data values are preserv ed in this normalizati on. For an instance, X min and X ma x are minim um and maximum values of attribute X . This data in terval [ X min , X ma x ] is to be m apped into a new interval [ X ne w _m in , X ne w_ m ax ]. Therefore, every value val from original data interval is m apped into value no rm al iz ed_ va l using the form ula : X XX XX X val-min normaliz ed_val= max -min *(new_m ax -new_m in ) +new_mi n (2) As mentioned earlier for step-1, a classific ation model based o n SVM has been constructed from the normaliz ed data. The classification result of t his stage h as been fu rther fine- tuned by DKFIS as will be discussed late r. In the step-2, a non- linear r elations hip betw een predict or var iables and target variable has been calibrated using Adaptive Neuro-Fuzzy Inference System (ANFIS). In order to train the ANFIS model, first, the norm alized in put v ariables have been f uzzifie d usi ng generaliz ed bell sh aped membership fu nctions (gbellm f) as: 2 1 ( ; , , ) 1 b f x a b c xc a (3) where ' c ' rep resents the ce nter of the corr esponding membership fu nction, ' a ' represent s half of the width; ' a ' and ' b ' together deter mine the slopes at the crossover points. T he bell function i s continuous and infinitely differentiable, which is required for gradient based learning. Fig . 2 r epresents bell shaped membership functio n wh ere y-a xis represe nts membership value o f the fuzzified p ara meter at the corresponding data points a nd x axis represents universe of discourse. The par ameters ca n be adjusted to tune the shape of the membership function. Fig. 2. B ell shaped me mbership functio n . The ANFIS has been initiali zed and a hy brid algo rithm combining least-squa res and gradient descent method with back-propag ation has been applied to train the paramete rs of FIS using a training dataset. T he training patterns are the oil saturati on values and assoc iated in puts fr om Class- 1. DKFIS FRAMEWORK The qualitativ e domain knowledg e as in T able I is coded into a FIS by fuzzyfy ing the o il s aturation values. Fig. 3 represents the proposed hybrid SVM and ANFIS based cascaded learning system i.e. the DKFIS fram ework. Two membership functi ons have been defined depending on the range of oil saturation value- NZS (Non-zero Small) and NZB (Non-zero B ig). Fig. 4 describes the plot o f these two membership functi ons along the unive rse of dis course. The cl assifie r an d the pre diction m odels have been tra ined and teste d using th e datas et. The train ing set has been cr eated This paper was presented at Indicon 20 15 at New Delhi, India Fig. 3. Propose d hybrid SVM, ANFI S and domain know ledge based cascade d learning syste m (DKFIS) by combinin g 70% patte rns from each of the w ells. The remainin g 30% patterns from each of the wells have been combined to create the testin g set. The predicto r and targ et variables have been norm alized using Z- score and min-m ax normaliz ation res pectively . For the particul ar dataset used in this study , the range of oil saturation value is from 0 to 0.86 with mean and variance of 0.0391 and 0.0124 per unit respective ly. T he mem bership functions NZS and NZB have been defined accordingly . As shown in Fig. 3, the outputs after Stage-1 as w ell as Stage- 2 have been modifie d with the domain know le dge using the DKFIS in the follow ing manner. Firs t, the de -normalize d predicti on o utput has been fuzzified using the defied Gaussian m embership fu nction s NZ B and NZS as in Fig . 4 . For example, a pattern belongs to NZS c ategory if fuzzifie d value of oil saturation by NZS membership functi on is more than the fuzzified value corresponding to NZB. Thus, the Class 1 p atterns have been again classifi ed into two categories- NZS (Non Ze ro Sm all) and NZB (Non Z ero Big ) . Subsequently the m embership grade of NZS an d NZB have been mod ified using the domain know ledge from Table I. For example, Rule-1, and Rule-2 correspon d to low oil saturati on values for a given input conditi on. Suppose with these input conditi o ns, the SVM categorizes the pattern as a Class 1 (which corresponds to high saturation values) sam ple instead of Class 0, then clearly the class label shoul d be modified to Class 0 and the inputs should not be passed to the subse quent steps for p redicti on. These rules have been applied to each and every outcome and the membershi p grades have b een changed as required . T he modified oil saturati on valu e has been obtained by d efuzzif ying the modified m embership grades. 0 0.2 0.4 0.6 0.8 0 0.2 0.4 0.6 0.8 1 Univer sal of d iscourse: Oil Saturation value Mem bership value NZ S NZ B Fig. 4. Plot of membership functions depending o n oil saturation v alue. V. E XPERIMENTA L R ESULTS First, the t raining and testing sets have b een prepared as shown in Fig. 3 follow ing the manner described in the previous section. T hen, a SVM classifier has been calibrated to classif y the patterns into Class 0 an d C lass 1 representing zero and non-zero oil saturation levels respectively using the training set. A fast alg orithm namely Sequenti al Minim al Optim ization (SMO) has been used to train the SVM m o del [23] . Then, t he classification result has been modified by the expert knowledge as report ed in T able I; follow ed by initializ ation and training of an ANFIS model using the training patterns belong to Class-1 resul ted in step 1. Here, the well logs and oil saturati on values have been used as predicto rs and target respectively . After completi on of successful train ing, testing has been carri ed out. First , testing patterns have beem classified into Class 0 and Class 1 by calibrate d SVM classifier follow ed b y modification as This paper was presented at Indicon 20 15 at New Delhi, India suggested by ex pert know ledge. Then, th e resul ting Class 1 patterns have been evaluated by the calibrat ed ANFIS paramete rs. Finally , the prediction results have also been modified based on experts’ knowledge. The improvem ent in the predicti o n has b een quantif ied in terms of four metrics such as CC , RMSE, AEM and SI. The classification performance of SVM classifier alone and including experts’ know ledge have been report ed in Table II in terms of g-metric means using the testing dataset . G-metric means is an appropriate parameter to quantify classifi cation r esult while working with an imbalanced dataset [24] . The first three rows o f Table II represent the perform ances of the sam e while working with different kernel functions e.g. Gaussi an radial basis (rbf), linear, multilay er perceptron (mlp) respectively [19]. Gaussian rbf kernel outperfo rms others obtaining maxim um g -metric means. T he width of the ke rnel param eter has been also crucial to obt ain high g-m etric mean s. Fig. 5 represents the variati on betw een g-metric m eans and rbf ke rnel parameter. It can be seen from Fig. 5 that the g-metric means is maximum while training the classifi er with Gaussian rb f kernel with width param eter one. In ea ch of th e three cases, the g-metric means increases while including expert knowledge after the SVM. Then, the trained ANFIS parameters have been used to obtain oil saturati on values from the predictor variables of the testing patterns belong to Class 1 category as an outcome of step 1 in testing. Even thoug h there seem s to be a good testing perf ormance in term s of the four metrics by ANFIS alone without including expert knowledge base as show n in Table III, th e DKF IS has bee n use d t o integ rate th e domain knowledge for realis tic predictions. TABLE II . T HE CLASSIFICATION PERFORMANCE OF SVM USING DIFFERENT KERNEL FUNCTION WITH THE TESTING P ATTERNS Expert Knowledge Kernel Function G-metric means Not Included rbf 0.9316 linear 0.9197 mlp 0.6293 Included rbf 0.9397 linear 0.9277 mlp 0.6383 Fig. 5. Plot of G-metric means vs. rbf kern el parameter TABLE III . S TATIST ICS OF TESTING PERFORMANC E IN PREDICTION Performance Indicators Excluding Expert Knowledge Including Expert Knowledge CC 0.91 0.95 RMSE 0.11 0.06 AEM 0.08 0.05 SI 0.48 0.21 These modifications u sing the DKFI S have been carried out by fuzzifying t he pred icted output using the Ga ussian membership functions NZS (Non -zero Small) and NZB (Non-zero Big). In the cases where there is a mismatch in the pred iction t he me mbership grades of the predic ted output have been m odified. Finall y, t he modified pred iction output ha s been achieved by d efuzzifying the modi fied membership grades. The performance indicator values reported in Table III confirms the improveme nt in prediction wh ile including expert op inions into consideration. Thus, the propo sed DKFIS ca n be used as a n efficient fra mework to p redict litholo gical prop erties from well logs. VI. C ONCLU SIONS The proposed two-stage methodology ca n be applie d to estimate lithologica l properties from input logs a nd litholog y log for incom plete an d impre cise datase t. In case of a good quality dataset also , the knowledge base learnin g would improve th e pre diction ac curacy . In future , an init iative can be taken to design a prediction model to estim ate petrophy sical properties from seismic attri butes using an expert defined kn owledge base. The proposed DKFIS has been implemented to solve a reservoi r charact erizati on problem efficient ly. Therefore, it can be expected to car ryout predicti on effective ly while workin g with dataset from other research areas. In those cases, the associated knowled ge base would be developed by a dom ain know ledge expert. R EFERENCES [1] S. Mohaghegh, R. Arefi, S. Ameri, K. Aminiand, and R. Nutter, “ Petrole um reservoir characterization w it h the aid of artifi cial neural netwo rks,” J. Pet. Sci. Eng. , vol . 16, pp. 263 – 274, 1996. [2] S. Mohaghe gh, R. Ar efi, S. Ame ri, and M. H. He fner, “A methodolog ical approach for reservoir heterogene ity characteriz ation using artificial neural n etworks,” in SPE Annual Technical Confer ence and Exhib ition, SPE 28394 , 1994, p p. 1 – 5. [3] M. Nikravesh, “Soft computing -based computational intelligent for reservoir characterizat ion,” Expert Syst. with Appl. , vol. 26, no. 1, pp. 19 – 38, Jan. 20 04. [4] M. Nikravesh and M. Hassib i, “ I ntelligent reservoir characteriz ation ( I RESC),” in Pr o c. IEEE Int. Conference on Ind. Informatics , 2003, pp. 369 – 373. [5] A. K. Verma, S. C haki, A. Routray, W. K. Mohanty, and M. Jenamani, “Quantificat ion of sand fraction from seismic attributes using Ne uro- Fuzzy approach,” J. Appl. Ge ophys. , vol . 111, pp. 141 – 155, De c. 2014. [6] S. C haki, A. K. Verma, A. R outray, W. K. Mohanty, and M. Jenamani, “Well tops guided prediction of reservoir properties using modular neural ne twork concept: a case study from western onshore, India,” J. Pet. Sci. E ng. , vol. 123, pp. 155 – 163, Jul. 2014. [7] S. C haki, A. K. Verma, A. R outray, W. K. Mohanty, and M. Jenamani, “A novel framewor k based on SVDD to c lassify water This paper was presented at Indicon 20 15 at New Delhi, India sat uration from seismic attributes,” in Proc. 4 th Int. Conf. Emerging Applic at. Inform. Tec hnology , 2014, pp. 64 – 69. [8] A. Bhatt and H. B. H elle, “Dete rmination of facies fro m well logs using mo dular neural netw orks,” Pet. Geos ci. , vol. 8, no. 3, pp. 217 – 228, Sep. 2002. [9] S. Chaki, A. K. Verma, A. R outray, W. K. Mohanty, and M. Jenamani, “A one - class classification framewor k using SVDD : application to a n im balanced geological d ataset,” in Proc. I EEE Students’ Tec hnology Symp. (Tec hSym) , 2014, pp. 76 – 81. [10] S. Chaki , A. K. Verma, A. Routray , M. Jenama ni, W. K. Mohanty, P. K. Chaudhuri, and S. K. Das, “Prediction of por osity and sand f raction from well log d ata using A NN and ANFIS : a comparative study,” in 10th Biennial International Conference & Exposition of SPG , 2013. [11] Y. Huang, P. Wong, and T. Gedeon, “An improve d fuzzy neural networ k for pe rmeability estimation from wirel ine logs in a petrole um reservoir,” in Proc. IEEE Region Ten Conf. (TENCON) on Digital Signal Proc essing Applicat. , 1996, pp. 9 12 – 917. [12] Y. Huang, T. D. Gedeo n, and P. M. Wong, “An integrated neural-fuzzy -genetic-algorithm using hyper-surface membership functions to predict pe rmeability in petroleum reser voirs,” Eng. Appl. Artif. I ntell. , vol. 14, pp. 15 – 21, 2001. [13] G. Haixi ang, L. Xiuwu, Z. Kejun, D. Chang, and G . Yanhui, “Optimizing reservo ir features i n oil exploration management based on fusion of soft computing,” Appli. Soft Comput. , vol. 1 1, no. 1, pp. 1144 – 11 55, Jan. 2011. [14] K. Aminian and S. Ameri, “Application of artificial neural networ ks for reservoir cha racte rization with limited data,” J. Pet. Sci. Eng. , vol . 49, no. 3 – 4, pp. 212 – 222, Dec. 2005. [15] W. E. Af ify and A. H . I . Hassan, “ Permeability and porosity prediction from wireline logs using Neuro-Fuzzy t ech nique,” Ozean J. Appl. S ci. , vol. 3, no. 1, p p. 157 – 175, 2010. [16] H. Jia, “The application of Adaptiv e Neuro -Fuzzy I nference Syste m in lithology identification,” in 2012 IEEE Fifth International Conference on Advanced Computational Intelligence (ICA CI) , 2012, pp. 966 – 968. [17] A. Badruzzaman, R. H. Skillin, T. A. Zalan, T. Badruzzaman, and P. T. Nguy en, “Accurate oil saturat ion determination using carbon oxygen logs i n three- phase reservoirs,” in 3 9th Annual Logging Sym posium , 1998. [18] S. Chaki, A. Rout ray , and W. K. M ohanty , “A novel preprocessing scheme to improve the prediction of sand fraction from seismic attributes using neural networks,” IEEE J . Sel. Top. Appl. Earth Obs. Remote S ens. , vol. 8, no. 4, pp. 1808 – 1820, 2015. [19] A. Chaudhuri, S. Naya k, and A. Routray , “Use of data driven optimal filter to obtain significant trend present in frequency domain parame ters for scalp EEG capture d during meditatio n,” in Proc. IEEE Students’ Technology Symp. (TechSym) , 2014, pp. 7 – 12. [20] A. Chaudhuri, B . Ba l, and A. Routray, “Correlation of estimated sources in human brai n obtained by source l ocalization method with w aves obtained by Teleg rapher ’ s e quation,” in Proc. 4 th Int. Conf. Emerging Applicat. Inform. Technology , 2014, pp. 93 – 98. [21] D. Suc and I . Bratko, “Impro ving numerical predictio ns with qualitative constraints,” in Proceedings of the 14th European Conference on M achine Learni ng , 2003, pp. 385 – 396. [22] D. Suc, D. Vladusic, and I. Bratko, “Qualitatively faithful quantitative prediction,” Artif. Intell. , vol. 158, no. 2, p p. 189 – 214, Oct. 2004. [23] J. C. Platt, “Fast training of support vector mac hines using sequential minimal optimization,” i n Advances in Kernel Methods-Support Vector Learnin g , MIT Pre ss, 1999, pp. 41 – 65. [24] M. Kubat and S. Matw in, “Addressing t he curse of imbalanced training sets: one- sided selection,” in Proc. 14th Int. Conference on Machine Le arning , 1997, pp. 1 79 – 186.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment