Playing Doom with SLAM-Augmented Deep Reinforcement Learning
A number of recent approaches to policy learning in 2D game domains have been successful going directly from raw input images to actions. However when employed in complex 3D environments, they typically suffer from challenges related to partial obser…
Authors: Shehroze Bhatti, Alban Desmaison, Ondrej Miksik
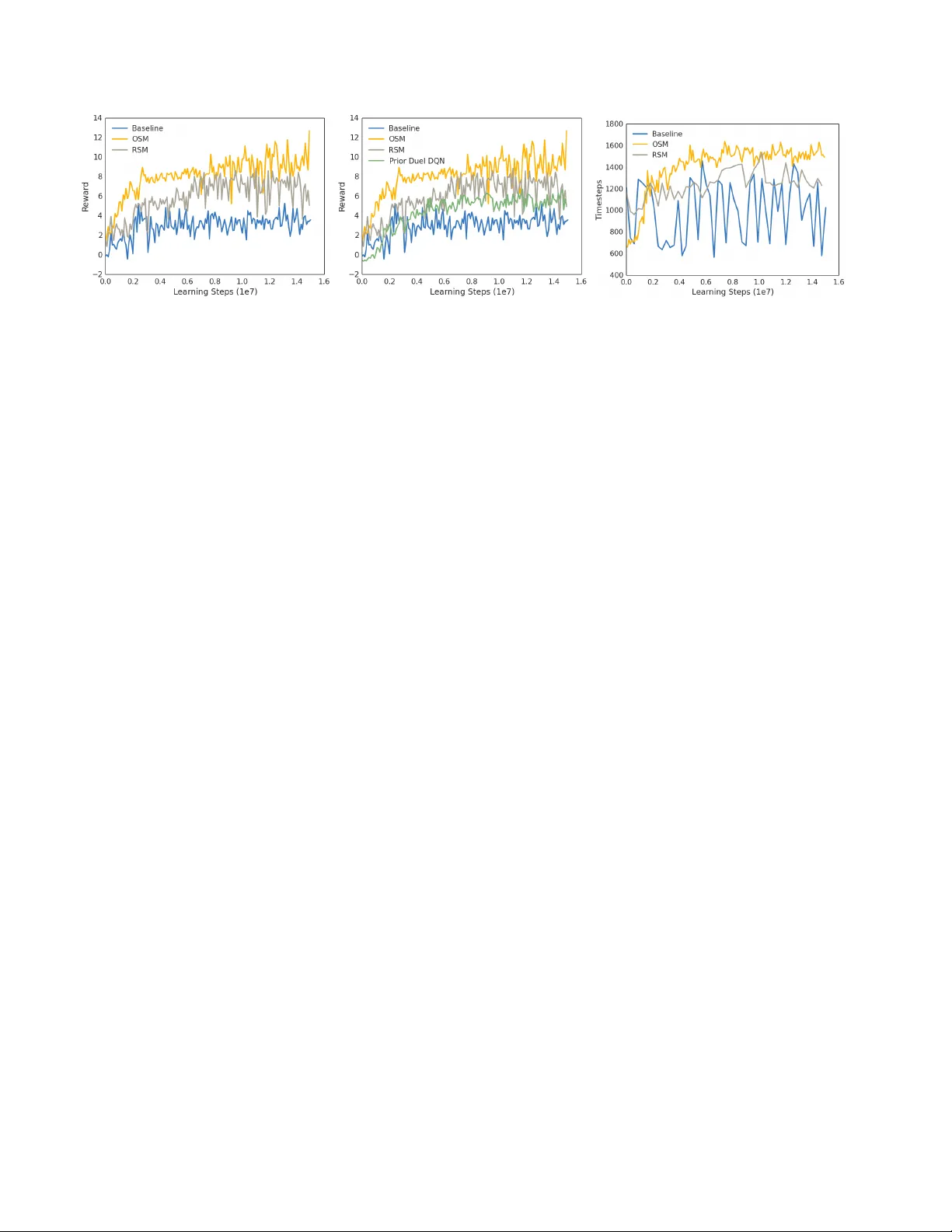
Playing Doom with SLAM-A ugmented Deep Reinf or cement Learning Shehroze Bhatti Alban Desmaison Ondrej Miksik Nantas Nardelli N. Siddharth Philip H. S. T orr Uni versity of Oxford Abstract A number of recent appr oaches to policy learning in 2D game domains have been successful going dir ectly fr om raw input images to actions. However when employed in complex 3D en vir onments, the y typically suffer fr om chal- lenges r elated to partial observability , combinatorial e xplo- ration spaces, path planning, and a scar city of r ewar ding scenarios. Inspir ed fr om prior work in human cognition that indicates how humans employ a variety of semantic concepts and abstractions (object cate gories, localisation, etc. ) to r eason about the world, we build an agent-model that incorporates such abstractions into its policy-learning frame work. W e augment the raw image input to a Deep Q- Learning Network (DQN), by adding details of objects and structural elements encounter ed, along with the agent’ s lo- calisation. The dif fer ent components are automatically ex- tracted and composed into a topological r epr esentation us- ing on-the-fly object detection and 3D-scene r econstruction. W e evaluate the efficacy of our appr oach in “Doom”, a 3D first-person combat game that exhibits a number of c hal- lenges discussed, and show that our augmented framework consistently learns better , mor e effective policies. 1. Introduction Recent approaches to polic y learning in games [ 30 , 29 ] hav e sho wn great promise and success over a number of different scenarios. A particular feature of such approaches is the ability to take the visual game state directly as input and learn a mapping to actions such that the agent effec- tiv ely explores the world and solves predetermined tasks. Their success has largely been made possible thanks to the ability of deep reinforcement learning (deepRL) networks, neural networks acting as function approximators within the reinforcement-learning frame work. A particular variant, Deep Q-Learning Networks (DQN), has been widely used in a range of different settings with e xcellent results. It em- ploys conv olutional neural networks (CNN) as a building block to ef fectiv ely e xtract features from the observed input images, subsequently learning policies using these features. Figure 1. Motiv ation: As the agent explores the environment, the first-person-view (top) only sees a restricted portion of the scene, whereas in the semantic map (bottom), the effect of exploration is cumulativ e, indicating both type and position . For the majority of scenarios that ha ve been tackled thus far , a common characteristic has been that the domain is 2-dimensional. Here, going directly from input image pix- els to learned policy works well due to two important fac- tors: i) a reasonable amount of the game’ s state is directly observable in the image, and ii) a combination of a lo wer - dimensional action space and smaller exploration require- ments result in a smaller search space. The former ensures that the feature e xtraction always has suf ficient information to influence policy learning, and the latter makes learning consistent features easier . Despite stellar success in the 2D domain, these models struggle in more complicated do- mains such as 3D games. 3D domains exhibit a multitude of challenges that cause the standard approaches discussed above to struggle. The introduction of an additional spatial dimension, first intro- duces notions of partial observability and occlusions, and secondly causes complications due to viewpoint variance. Not only is the agent vie wing a relatively smaller portion (volume) of the en vironment, it also must reconcile observ- ing a v ariety of other objects in different contexts under pro- jectiv e transformations. Furthermore, adding an extra di- mension also combinatorially complicates matters in terms of exploration of the en vironment. This typically manifests 1 itself in the form of sparse feedback in the learning process because the agent’ s inability to explore the en vironment di- rectly penalizes its learning capacity . Moreover , complica- tions in exploration directly af fect any planning that may be required for tasks and actions. Finally , with larger search and state spaces comes the likelihood that any rewards that might help mov e learning along are also harder to come by . Sutton et al. (1999) [ 42 ] propose an extension of the RL framew ork that can potentially learn hierarchical poli- cies. Howe ver this, and similar methods, have not been able to scale beyond small gridworld domains [ 1 ]. Kulka- rni et al. (2016) [ 24 ] proposes to tackle environments with delayed rewards by coupling options learning and intrinsi- cally driven exploration methods. Options are howe ver no- toriously hard to train, requiring a great deal of ef fort before intrinsically moti vated agents can safely deal with generic hierarchical spatial domains. Prior work in behavioural modelling and cognitive neu- roscience suggests that humans employ particular , highly specialised mechanisms to construct representations of, and reason about, the world. These typically take the form of semantic concepts and abstractions such as object identity , categories, and localisation. Freedman and Miller (2008) [ 14 ] revie w e vidence from neurophysiology that e xplore the learning and representation of object categories. Bur gess (2008) [ 4 ] discusses evidence from neuroscience for the presence and combination of different viewpoints ( e.g. , ego- centric) and the role of representing layouts ( e.g. , bound- aries and landmarks) in the spatial cognition process. Moser et al. (2008) [ 31 ] also discuss the presence of highly spe- cialised representation re gions in the brain that encode lo- calisation and spatial reasoning. Denis and Loomis (2007) [ 7 ] provide a re view from beha vioural psychology on the subject of spatial cognition and related topics. In this paper , we take inspiration from such work to pro- pose a system that explicitly constructs a joint semantic and topological representation of the state, and further aug- ment its input with this representation (Fig. 1 ) in an attempt to learn policies more effecti vely in such comple x 3D do- mains. T o this end, we construct a no vel model that incor- porates an automatic, on-the-fly scene reconstruction com- ponent into a standard deep-reinforcement learning frame- work. Our work provides a streamlined system to imme- diately enhance current state-of-the-art learning algorithms in 3D spatial domains, additionally obtaining insight on the efficac y of spatially enhanced representations against those learned in a purely bottom-up manner . 2. Related work 2.1. Deep Reinfor cement Learning Reinforcement Learning is a commonly employed set of techniques for learning agents that can execute generic and interactiv e decision making. Its mathematical framework is based on Markov Decision Processes (MDPs). An MPD is a tuple ( S, A, P, R , γ ) , where S is the set of states, A is the set of actions the agent can take at each time step t , P is the transition probability of going from state s to s 0 using action a , R is the re ward function defining the signal the agent receives after taking actions and changing states, and γ is a discount factor . The goal of Reinforcement Learning is to learn a policy π : s → a that maximises the expected discounted average re ward over the agent run. A commonly used technique to learn such a policy is to learn the action- value function Q π ( s, a ) iterati vely , so as to gradually ap- proximate the expected re ward in a model-free fashion. They have, howe ver , traditionally struggled to deal with high-dimensional en vironments, due in large part to the curse of dimensionality . Deep Reinforcement Learning al- gorithms such as Deep-Q Networks extend model-free RL algorithms like Q-Learning to use Deep Neural Networks as function approximators, implicitly capturing hierarchies in the state representation that make the RL problem scale ev en to visual input states. Unfortunately , they still suf fer from some of the problems that standard RL cannot deal with: • delayed re ward signals require non-stochastic explo- ration strategies [ 24 ]; • learning to abstract policies hierarchically is currently an unsolved but ke y problem to make RL scale to tasks requiring long-term planning [ 1 ]; • partial observ ability in state requires use of models that can encode at least short-term memory , specially when training end-to-end [ 17 ]. Some recent work has also explored ways to dev elop agents that can learn to play Doom. Lample and Chaplot (2016) [ 25 ] take the approach of using a variant of DRQN [ 18 ] together with some game features extracted directly from the game en vironment through its data structures. Our method is similar in the spirit, but can be applied to any en vironment with a significant 3D na vigation component, as our SLAM and object recognition pipeline is not intrin- sically dependent to the V izDoom platform. Another in- teresting approach is the one presented by Dosovitskiy and K oltun (2016) [ 8 ]. This approach, featured as the winner in the V izDoom competition [ 20 ], changed the supervision signal from a single scalar rew ard to a vector of measure- ments provided by the game engine. This is used to train a network that, given the visual input, the current measure- ments, and the goal, predicts future measurements. The ac- tion to perform is then chosen greedily according the pre- dicted future measurements. This is orthogonal to our ap- proach; both algorithms could benefit from the nov elties in- troduced by the other, howe ver we leave such an extension on our part for the future. 2.2. Simultaneous Localization and Mapping Early approaches to camera-pose estimation relied on matching a limited number of sparse feature points be- tween consecutiv e video frames [ 6 ]. A common draw- back of such solutions is relatively quick error accumula- tion which results in significant camera drift. This may be addressed with PT AM [ 22 ], which achiev ed globally op- timal solutions at real-time rates by running bundle adjust- ment in a background thread. Further improv ements include re-localization, loop-closure detection, and faster match- ing with binary features [ 5 , 32 , 23 ]. Recently , matching hand-crafted features has been replaced by semi-dense di- rect methods [ 10 ]. Ho wev er , these approaches only provide very limited information about the en vironment. A more complete map representation is provided by dense approaches [ 41 , 34 , 27 ]. They estimate dense depth from monocular camera input, but their use of a regu- lar v oxel grid limits reconstruction to small volumes due to memory requirements. KinectFusion-based approaches [ 33 ] sense depth measurements directly using acti ve sen- sors and fuse them o ver time to recover high-quality sur - faces, b ut the y too suffer from the same issue. This draw- back has since been removed by scalable approaches that allocate space only for those vox els that fall within a small distance of the perceived surfaces, to av oid storing unnec- essary data for free space [ 35 ]. All approaches mentioned abov e assume the observed scenes are static. This assump- tion can be relaxed by full SLAM with generalized (mov- ing) objects or some of its more efficient variants [ 45 , 3 ], but this is be yond the scope of this paper . Approaches such as RatSLAM [ 28 ] and its derivati ves propose instances of SLAM based on models inspired by bi- ological agents, sho wing promising results in en vironments where the navigation task requires some reasoning about landmarks and non-Cartesian grid representations. 2.3. Object detection Early approaches to object detection include constella- tion models and pictorial structures [ 13 ]. The very first object detector capable of real-time detection rates was [ 44 ], who solved an inherent problem of sliding-windo w approaches by learning a sequential decision process that rapidly rejects locations which are unlikely to contain any objects. This concept has since then ev olved into a dis- tinct set of algorithms called proposals , whose only goal is to quickly localize potential objects [ 19 ]. These loca- tions are then fed into more complex classifiers to determine the class label (or assign a background). Deformable part models [ 11 ] are a prominent example of such, being able to represent highly variable object classes. Recently , it has been shown that deformable part models can be interpreted as a con volutional network [ 16 ], which led to replacement of handcrafted features by con volutional feature maps [ 15 ]. Finally the Faster-RCNN [ 36 ] combines the region propos- als and object detector into a single unified network train- able end-to-end with shared con volutional features which leads to very fast detection rates. 3. Semantic Mapping In this paper, we introduce an algorithm based on the Deep Q Network (DQN) that has been successfully applied to man y Atari games [ 30 ]. Inspired by prior work in human cognition that indicates how humans emplo y a variety of se- mantic concepts and abstractions (object categories, local- ization, etc. ) to reason about the world, we build an agent- model that incorporates such abstractions into its policy- learning frame work. W e augment the first-person raw im- age input to a DQN by adding details about objects and structural elements encountered, along with the agents lo- calization to cope with complex 3D en vironments. This is represented as a 2D map (top-do wn view) encoding three distinct sources of information: i) positions of static struc- tures and obstacles such as walls, ii) position and orienta- tion of the agent, and iii) positions and class labels of im- portant objects such as health packs, weapons and enemies. Our representation is being updated ov er time as the agent explores the en vironment. This allo ws the agent to keep information about areas observed in the past and build an aggregated model of the 3D en vironment, as indicated in Fig. 1 . Such representation allo ws the agent to behave prop- erly ev en with respect to the elements no longer present in the first-person view . Semantic repr esentation. As the agent explores the en- vironment, we simultaneously estimate localization of the agent and obstacles ( e .g. , walls) in order to build the map of the surrounding 3D environment from the first-person-vie w at each frame. In parallel, we detect important objects in the scene such as weapons and ammunition. And since we want to minimize the dimensionality of the augmented rep- resentation to allo w more ef ficient learning, we project all semantic information onto a single common 2D map of a fixed size. Essentially a “floor -plan” with the positions of objects and agents. This is achiev ed by encoding different entities by dif ferent gray-scale values, in the form of heat- maps ( cf. , bottom right of Fig. 1 ). Our representation encodes position of walls and ob- stacles (white) extracted directly from the depth data pro- vided by the V izDoom API. Information about agent’ s po- sition and orientation on the 2D map is represented as a green directed arro w . W e also want to provide the agent semantic information about a v ariety of objects present in the en vironment. For Doom, we encode the follow- ing five object cate gories: monsters (red), health packs (purple), high-grade weapons (violet), high-grade ammuni- tion (blue), other weapons and other ammunition (yellow). Figure 2. System overvie w: (a) Observing image and depth from V izDoom. Running Faster -RCNN (b) for object detection and SLAM (c) for pose estimation. Doing the 3D reconstruction (d) using the pose and bounding boxes. Semantic maps are built (e) from projection and the DQN is trained (f) using these new inputs. Since these objects could either move or be picked up by another player ( e.g . , deathmatch scenario), we project only those objects that are visible in the current view onto the common map. This could be addressed by more adv anced data association techniques such as [ 45 , 3 ], but this is be- yond the scope of this paper . 4. Recognition and Reconstruction Here, we describe the process of automatically creating semantic maps on-the-fly . Fig. 2 depicts the architecture of our pipeline. As input, we use the image data pro vided by the V izDoom API, i.e. , RGB video frames visualizing the 3D en vironment from agents (first person) perspecti ve and a z-buf fer providing depth information of the observ ed scene. In order to build a map of the 3D en vironment, we need to detect and remove all objects from the z-buf fer since we want to i) provide e xplicit semantic information about vari- ous objects (monsters, weapons, etc. ) and ii) av oid nuisance visual events such as weapon discharges in the depth buf fer . W e also need to know the current pose of the camera, so we run a camera-pose track er in parallel with the object de- tector . Then, we project the observed scene on a common 3D map and provide its 2D visualization (top-do wn view) to the agent. Note, that the mapping system could work even without access to the z-b uffer , i.e. , using solely the RGB data [ 9 ]. W e no w describe the components of our pipeline (object detection, camera pose estimation and map fusion) in greater detail. 4.1. Object detection T o detect the objects, we use the Faster -RCNN object detector [ 36 ], which is a con volutional network that com- bines the attention mechanism (region proposals) and ob- ject detector into a single unified netw ork, trainable end-to- end. The first module is a deep fully-con volutional network that simultaneously predicts object bounds and objectness scores at each position, and the second module is the Fast R-CNN detector [ 15 ] that uses the proposed regions. Since both modules share the same features, it of fers v ery fast de- tection rates. As input, we use the RGB image resized to the standard resolution of 227 × 227 pixels. Next, the image is pushed through the network and a conv olutional feature map is ex- tracted. W e use the model of Zeiler and Fergus (2014) [ 47 ] to extract these feature maps. T o generate region pro- posals, this feature map is processed in a sliding-window manner with two fully-connected layers predicting position of the region proposal and a binary class label indicating “objectness”. For each region proposal, the corresponding (shared) feature maps are fed into 2 fully-connected layers with 2048 units that produce soft-max probabilities over K object classes (and background) and positions of bounding boxes of the detected objects. W e trained this object detec- tor on five classes corresponding to objects and monsters that are projected onto the common map. 4.2. Camera pose estimation Despite using ground-truth depth maps pro vided by the z-buf fer , ICP-like approaches [ 2 ] do not work well in game en vironments since such en vironments lack many geometri- cal features (the y are typically represented as te xtured pla- nar surfaces to allow fast rendering). Hence, we use the sparse feature-based ORB-SLAM2 for 6-DoF camera-pose estimation [ 32 ]. As input, we use RGB images down- sampled to 320 × 240 pix els and a z-buf fer . First, we build an eight-le vel image p yramid with a scale factor s f = 1 . 2 . Then, we extract a set of sparse local fea- tures representing corner-like structures. For this, we use oriented multi-scale F AST detector [ 37 ] with an adaptiv ely- chosen threshold to detect a suf ficient number of features. The feature extraction step is biased by buck eting to ensure features are uniformly distrib uted across space and scale (at least 5 corners per cell). A constant-velocity motion model predicting the camera pose is used to constrain matching onto local search windows. The e xtracted features are as- sociated with local binary-patterns (256 bits ORB [ 38 ]) and matched using a mutual-consistenc y check. A robust es- timate is performed by RANSAC [ 12 ] with least-squares refinement on the inliers. Robustness is further increased by keyframes that reduce drift when the camera viewpoint does not change signifi- cantly . If tracking is lost, the current frame is con verted into a bag-of-words and queried against the database of keyframe candidates for global re-localization. The camera is re-localized using the PnP algorithm [ 26 ] with RANSA C. Global consistency is achiev ed by loop-closing pose-graph optimization that distributes the loop-closing error along the graph in a background thread [ 23 ]. 4.3. Mapping Once we hav e the camera poses and a object-masked depth map, we can project the current frame on a common 3D map. At each frame k , we back-project all image pixels i into the current camera reference frame to obtain a vertex map V k i V k i = d k i K − 1 ˙ u i . (1) Here, K − 1 denotes the in verse of the camera calibration matrix (using parameters from the V izDoom configuration file), ˙ u i = [ u i , v i , 1] > denote image pixels in homogeneous coordinates, and d k i is depth. W e also want to maintain previously-visited areas in memory so we project the (ho- mogenized) vertex map ˙ V k i = [ X i , Y i , Z i , 1] > from cam- era to global reference frame as V g i = T g ,k ˙ V k i , where T g ,k = { R , t | R ∈ SO 3 , t ∈ R 3 } is a rigid body transfor- mation mapping the camera coordinate frame at time k into the global frame g . Since the fix ed volumetric 3D repre- sentation severely limits the reconstruction size that can be handled, we use the hash-based method of [ 35 ]. The resulting 2D map is generated by placing a virtual camera at the top-do wn view , ignoring all points above and below some height thresholds to remove areas that would otherwise occlude the map, such as ceilings and floors. 5. Experiments In this section, we demonstrate the advantage of adding the semantic map presented in Sec. 3 to the standard first- person view while working inside the “Doom” en viron- ment. Code and results for these experiments will be made av ailable online. W e use the V iZDoom [ 21 ] platform for all our e xperiments. It is built on top of the first person combat game “Doom”, and allo ws easy synchronous control of the original game, where execution is user-controlled, getting Settings Rew ards Random Play 0 . 00 NOSM (player/objects) 2 . 94 OSM (no FPV) 3 . 16 baseline 3 . 45 NOSM (objects) 3 . 53 NOSM (walls) 3 . 92 Prior Dueling DQN 5 . 69 RSM (localisation) 5 . 87 OSM (localisation) 6 . 62 RSM 6 . 91 OSM 9 . 50 Human Player 45 . 00 T able 1. Best mean test rewards for the different frameworks run. Note that our pipeline performs strongly in comparison to both the baselines, and to the ablated versions considered. Also note that although the OSM is the best of the artificial systems considered, our pipeline, with the RSM is a lot closer to it than the others. the first-person-view from the engine at the current step, and stepping forward by sending it keystrokes. The envi- ronment where the player performs is specified as scenario. In this paper , we focus on the deathmatch scenario, in which the map is a simple arena as can be seen in Fig. 1 and the goal is to eliminate as man y opponents as possible before being eliminated. A proficient agent for this scenario would be the one that is efficient at eliminating enemies whilst being able to both collect more effecti ve weapons and keep its own health as high as possible. This scenario was the basis of the CIG 2016 competition [ 20 ] where different autonomous agent competed in a deathmatch tournament. The quantitative results for all the experiments carried out are summarised in T ab . 1 . The individual features of the experiments run, and the insights obtained from these runs, are described in subsequent sections, follo wing detailed dis- cussion of the various components of our frame work. Recognition and Reconstruction. As described in Sec. 4.1 , we use the F aster-RCNN detector and feed it with the RGB image gi ven by the platform. W e use a net- work pre-trained on Imagenet [ 39 ] that we fine-tuned on a dataset consisting of 2000 training and 1000 v alidation examples extracted from the V iZDoom engine, performing 5-fold cross-v alidation. These images were manually anno- tated with ground-truth bounding boxes corresponding to 7 classes: monsters, health packs, high-grade weapons, high- grade ammunition, other weapons/ammunition, monsters’ ammunition, and agent’ s ammunition. After fine-tuning, the model achiev ed an average precision of 93 . 21% . The reconstruction system presented in Sec. 4.2 uses the RGB- D images provided by the V izDoom platform. Policy Learning. W e use the DQN frame work from [ 30 ] to perform policy learning with our augmented features. The only modification to the original algorithm is the CNN architecture that needs to be able to cope with the extended state. The first person view (FPV) images are resized to 84 × 84 pixel, con verted to grayscale and normalized. The semantic 2D map is represented as a single channel image of the same resolution. The dif ferent object categories are encoded by dif ferent grayscale values. For the experiments that use both the FPV and the 2D map, we concatenate them along the channel dimension. The Q network is composed of 3 con volutional layers ha ving respecti vely , 32, 64 and 64 output channels with filters of sizes 8 × 8 , 4 × 4 and 3 × 3 and 4, 2 and 1 strides. The fully-connected layer has 512 units and is follo wed by an output SoftMax layer . All hidden lay- ers are followed by rectified linear units (ReLU). Adding the 2D map associated to each FPV image changes input chan- nels from 4 to 8 for the first con volutional layer , and thus increase the number of parameters from 77824 to 86016 , a 10% increase. For training, we use the hyper -parameters from [ 29 ] and RMSProp for all experiments. Action Space. The action space for this en vironment is an order of magnitude larger than the Atari en vironment. Indeed, “Doom” accepts any combination of 43 unique keystrok es as input. Follo wing the observation that a hu- man player uses only a small subset of these combinations to play the game, we recorded actions performed by hu- mans and selected a representati ve subset. These actions can be di vided into three groups: i) actions corresponding to a single keystroke allo wing the agent to move and shoot, ii) combinations of two k eystrokes corresponding to mov- ing and shooting at the same time and iii) actions associated with switching weapons. W e arbitrarily chose the top 13 actions performed by humans, categorising them into the 3 groups mentioned abo ve. W e did so primarily to constrain the action space to a reasonably tractable size, while still maintaining richness of actions that could be performed in the en vironment. Reward Function. Our rew ard function is designed to capture the primary goal of the agent: to eliminate oppo- nents. W e represent this as ∆ k , an indicator variable for an opponent being eliminated since the last step. T o encour- age the agent to li ve longer , we also consider ∆ h , the health variation between the current step and the pre vious step. W e explicitly structure the health rew ard to be zero-sum in or- der to remove any biases to wards preserving health to the detriment of the primary goal. The re ward R incorporating both these terms is written as: R = ∆ h / 100 + ∆ k where ∆ h ∈ [ − 100; 100] and ∆ k ∈ { 0 , 1 } Evaluation Metrics. W e use two dif ferent scores to ev al- uate and compare different architectures. The main metric is the rew ard function as it allows observing the agent’ s be- haviour with respect to the primary objecti ve. The second reported metric is the number of steps the agent has li ved. This is important as living increases the agent’ s chance to kill opponents and increase its reward in the longer term. All reported metrics are mean values o ver 100 test games. Time Complexity . The complete framework has to be fast enough to allow playing at the game’ s native speed. T o do so, we run the object detector in parallel with the camera- pose estimation. On av erage, the detector requires 60 ms to process an image while camera-pose estimation and latency take 12 ms and 10 ms respectiv ely . Semantic map construc- tion takes 25 ms, and DQN training requires 18 ms to pro- cess a frame and perform one learning step. The complete pipeline is able to process, on a verage, 10 images per sec- ond. Given that inside the V iZDoom platform each step represents 4 frames of the game (as does the Atari emula- tor), our system plays at approximately 40 frames per sec- ond, which exceeds typical demands of gameplay . All ex- periments were run on a Intel Core i7-5930K machine with 32GB RAM and one NV idia Titan X GPU. Figure 3. (top) A verage re ward. (bottom) OSM vs. NOSM. 5.1. Oracle Semantic Maps (OSM) The first set of experiments allows us to ev aluate the ef- ficacy of our semantic representation. W e first isolate po- tential errors introduced by the recognition and reconstruc- tion pipeline by extracting ground-truth information about classes and positions of all objects that are used in the se- mantic map representation. In other words, this experiment presents the results we would get if we had perfect detection and reconstruction, and is used as an “oracle”. As the baseline, we use the standard DQN approach trained solely on the first person view images (referred to as baseline in the following). This baseline is compared to i) model trained with both, the first person view and the 2D map encoding ground-truth walls and player position (lo- calisation OSM) ii) model trained with both, the first per- son vie w augmented by the complete 2D maps containing ground-truth walls and positions of player and objects. As can be seen in Fig. 3 , the baseline is not able to learn as good policy as model with our semantic maps. Moreover , we see that the baseline model quickly reaches a plateau and does not impro ve afterwards. Adding a 2D map of the en- vironment ( i.e. , without objects) allows the agent to learn a significantly better policy as the rew ard is almost doubled compared to the baseline. Adding the objects seen by the agent onto this map giv es another significant improv ement leading to reward of 10 compared to the 3 − 4 achie ved by the baseline. Moreov er , we can see that the network pro- vided with the complete 2D map (including objects) is able to learn faster than the models provided with fewer infor- mation. This result pro ves that pro viding higher lev el, com- plex representation of the surrounding of the agent allows it to learn faster and con verge to a better polic y . Figure 4. The top maps for each column are all taken from the oracle. The maps on the bottom are (l) Oracle map with noise on player and objects’ positions. (m) Oracle map with noise on the walls. (r) Semantic map reconstructed, independent of the oracle, by our pipeline. 5.2. Noisy Oracle Semantic Maps (NOSM) Unfortunately , the detection and reconstruction pipelines are often imperfect in real world scenarios. Next, we study the impact of providing a very poor spatial representation to the agent. T o do that, we add a significant amount of noise to the ground-truth data extracted from the game to see how the DQN framew ork reacts. First, we consider the case where we add the same Gaus- sian noise to the agent’ s and all objects’ positions, refer- enced as NOSM (player/objects), meaning that these ele- ments are not properly positioned with respect to the static objects. Fig. 4 (l) sho ws the results of adding that noise. The OSM map is shown on top and its noisy version is shown below . One thing to note here is that these maps hav e gray scale pixel values to define different abstractions and objects. This gray scaled format was used for training as discussed in the previous sections. Next, we add Gaus- sian noise to the positions of walls, referenced as NOSM (walls), meaning that some element that appear accessible in the 2D map cannot be reached in the real environment. Fig. 4 (m) shows the results of adding that noise. As can be seen in Fig. 3 (bottom), this very high amount of noise in the 2D maps prevent the DQN framew ork to learn a good policy . Howe ver , it is important to note that in the worst case, the noisy version matches the performances of the baseline as the network learns to ignore it. 5.3. Reconstructed Semantic Maps (RSM) In Sec. 5.1 , we ha ve shown the efficac y of Q-learning with ground-truth version of our semantic maps. As a proof of concept, we now ev aluate performance with the real maps generated on-the-fly by the approach described in Sec. 4 (RSM). This experiment allows us to ev aluate the quality of the policy that can be learned when using the standard detection and mapping techniques without an y extra engineering. In other words, we measure the drop in performance caused by imperfect object detection and SLAM in a real world scenario with respect to the oracle. The difference between the OSM and the RSM is seen in Fig. 4 (r). Here, the semantic categories are coloured instead of greyscale le vels for emphasis. As seen in Fig. 5 (l), the reconstructed map leads to sig- nificantly better results than the baseline. Even though it doesn’t match the oracle, we clearly see that the RSM is much closer to the OSM than the baseline. The remaining gap can be further reduced with progress in the field. 5.4. Prioritized Duel DQN Combination of the prioritized experience replay [ 40 ] and dueling netw ork architecture [ 46 ] has demonstrated su- perior results on 57 Atari games (2D en vironment) com- pared to the vanilla DQN approach that is the baseline con- sidered above. In this experiment, we compare this success- ful model (referred as dDQN) with the basic DQN model augmented with our semantic maps. Fig. 5 (m) shows that while the combination of PRL with dual DQN achiev es better results than the DQN baseline, the model with our semantic maps, despite trained with the Figure 5. (l) OSM vs. RSM (m) Our method vs. dual DQN with prioritized ER. (r) OSM vs. DQN on mean run-length basic DQN, outperformed the PRL with dual DQN trained on first person vie ws. It is also interesting to note that these two approaches are orthogonal and could be combined. W e leav e this study for the future work. 5.5. Mean Run Length As can be seen in Fig. 5 (r), the agent trained with se- mantic maps is able to typically liv e longer than the one trained only on the first-person vie w . This is a consequence of the fact that the OSM agent inherently attempts to build a representation of the en vironment it is in, which helps it adapt better from arbitrary initialisation points. The base- line howe ver , does not hav e access to such capabilities, and hence performs incoherently in these situations. In keeping with the general characteristics of the results seen thus far , the RMS agent typically underperforms in relation to the ORM agent, b ut still significantly outperforms the baseline. 6. Discussion and Conclusion W e proposed to augment the standard DQN model with semantic maps; a representation that provides aggregated information about the 3D en vironment around the agent. W e hav e demonstrated the efficac y of our approach with both oracle maps, and automatically reconstructed maps us- ing object detection and SLAM, demonstrating the efficac y of our approach with standard computer-vision recognition and reconstruction pipeline ( e.g . , for road scene understand- ing [ 43 ]) and a standard of f-the-shelf polic y learner (DQN). Our central thesis is exploring the benefits of semantic representations augmenting the directly-from-pixels learn- ing approach typically employed. While we do not claim major contrib utions to policy-learning algorithms them- selves, the effort nonetheless provides insight on the ef- ficacy of such representations against those learned in a purely bottom-up manner . It also potentially serves as a benchmark for effecti veness of representations learned in a purely bottom-up manner . Moreov er , our approach has the potential to extend and scale be yond the Doom en viron- ment by virtue of its applicability to any en vironment with a reasonable number of potential other entities and the ex- tractability of 3D information. In terms of future directions, we would like to extend our framew ork along a variety of different axes. One particu- lar direction is improving our resilience to layered en viron- ments as we are currently unable to represent en vironments such as buildings (“stacked floors/levels”). Another direc- tion in volves relaxing the metric constraints that our maps are currently constructed under . Better localisation and se- mantic representations could exist that do not necessarily require metric reconstruction, but perhaps a more relativis- tic, graph-based approach. And finally , we are interested in extending our experiments to incorporate more maps (be- yond the deathmatch scenario we currently employ), and elicit qualitativ e judgments of the learned gameplay . References [1] A. G. Barto and S. Mahadev an. Recent advances in hierar- chical reinforcement learning. Discrete Event Dynamic Sys- tems , 13(4):341–379, 2003. 2 [2] P . J. Besl and N. D. McKay . A method for registration of 3-d shapes. T -P AMI , 1992. 4 [3] C. Bibby . Probabilistic Methods for Enhanced Marine Situ- ational A war eness . PhD thesis, Univ ersity of Oxford, 2010. 3 , 4 [4] N. Burgess. Spatial cognition and the brain. Annals of the New Y ork Academy of Sciences , 1124(1):77–97, 2008. 2 [5] M. Cummins. Pr obabilistic Localization and Mapping in Appearance Space . PhD thesis, University of Oxford, 2009. 3 [6] A. J. Da vison, I. D. Reid, N. D. Molton, and O. Stasse. Monoslam: Real-time single camera slam. T -P AMI , 2007. 3 [7] M. Denis and J. M. Loomis. Perspectives on human spatial cognition: memory , navigation, and environmental learning. Psychological Resear ch , 71(3):235–239, 2007. 2 [8] A. Dosovitskiy and V . K oltun. Learning to act by predicting the future. ICLR-2017 submission , 2016. 2 [9] D. Eigen, C. Puhrsch, and R. Fergus. Depth map prediction from a single image using a multi-scale deep network. In NIPS . 2014. 4 [10] J. Engel, T . Sch ¨ ops, and D. Cremers. LSD-SLAM: Large- scale direct monocular SLAM. In ECCV , 2014. 3 [11] P . F . Felzenszwalb, R. B. Girshick, D. A. McAllester, and D. Ramanan. Object detection with discriminativ ely trained part-based models. T -P AMI , 2010. 3 [12] M. A. Fischler and R. C. Bolles. Random sample consen- sus: A paradigm for model fitting with applications to image analysis and automated cartography . Commun. ACM , 1981. 5 [13] M. A. Fischler and R. A. Elschlager . The representation and matching of pictorial structures. T -Computers , 1973. 3 [14] D. J. Freedman and E. K. Miller . Neural mechanisms of vi- sual categorization: insights from neurophysiology . Neur o- science & Biobehavioral Re views , 32(2):311–329, 2008. 2 [15] R. Girshick. Fast R-CNN. ICCV , 2015. 3 , 4 [16] R. Girshick, F . Iandola, T . Darrell, and J. Malik. Deformable part models are con volutional neural networks. In CVPR , 2015. 3 [17] M. Hausknecht and P . Stone. Deep recurrent q-learning for partially observable mdps. arXiv pr eprint arXiv:1507.06527 , 2015. 2 [18] M. Hausknecht and P . Stone. Deep recurrent q-learning for partially observable mdps. arXiv pr eprint arXiv:1507.06527 , 2015. 2 [19] J. Hosang, R. Benenson, P . Dollar , and B. Schiele. What makes for ef fectiv e detection proposals? T -P AMI , 2016. 3 [20] W . Jako wski, M. Kempka, M. W ydmuch, and J. T oczek. V iz- doom competition. 2 , 5 [21] M. Kempka, M. W ydmuch, G. Runc, J. T oczek, and W . Ja ´ sko wski. V izdoom: A doom-based ai research plat- form for visual reinforcement learning. arXiv pr eprint arXiv:1605.02097 , 2016. 5 [22] G. Klein and D. W . Murray . Parallel tracking and mapping for small ar workspaces. In ISMAR , 2007. 3 [23] R. Kuemmerle, G. Grisetti, H. Strasdat, K. Konolige, and W . Burgard. g2o: A general framework for graph optimiza- tion. In ICRA , 2011. 3 , 5 [24] T . D. Kulkarni, K. R. Narasimhan, A. Saeedi, and J. B. T enenbaum. Hierarchical deep reinforcement learning: Inte- grating temporal abstraction and intrinsic motiv ation. arXiv pr eprint arXiv:1604.06057 , 2016. 2 [25] G. Lample and D. S. Chaplot. Playing fps games with deep reinforcement learning. arXiv preprint , 2016. 2 [26] V . Lepetit, F . Moreno-Noguer, and P . Fua. Epnp: An accurate o(n) solution to the pnp problem. IJCV , 2009. 5 [27] S. Liwicki, C. Zach, O. Miksik, and P . H. S. T orr . Coarse-to- fine planar re gularization for dense monocular depth estima- tion. In ECCV , 2016. 3 [28] M. J. Milford, G. F . W yeth, and D. Prasser . Ratslam: a hip- pocampal model for simultaneous localization and mapping. In ICRA , 2004. 3 [29] V . Mnih, K. Ka vukcuoglu, D. Silv er , A. Gra ves, I. Antonoglou, D. Wierstra, and M. Riedmiller . Playing atari with deep reinforcement learning. In NIPS Deep Learning W orkshop . 2013. 1 , 6 [30] V . Mnih, K. Kavukcuoglu, D. Silver , A. A. Rusu, J. V eness, M. G. Bellemare, A. Graves, M. Riedmiller , A. K. Fidjeland, G. Ostrovski, et al. Human-lev el control through deep rein- forcement learning. Natur e , 2015. 1 , 3 , 6 [31] E. I. Moser , E. Kropff, and M.-B. Moser . Place cells, grid cells, and the brain’ s spatial representation system. Annual Revie w of Neur oscience , 31(1):69–89, 2008. 2 [32] R. Mur-Artal, J. M. M. Montiel, and J. D. T ard ´ os. ORB- SLAM: a versatile and accurate monocular SLAM system. T -R O , 2015. 3 , 4 [33] R. A. Newcombe, S. Izadi, O. Hilliges, D. Molyneaux, D. Kim, A. J. Davison, P . Kohli, J. Shotton, S. Hodges, and A. Fitzgibbon. Kinectfusion: Real-time dense surface map- ping and tracking. In ISMAR , 2011. 3 [34] R. A. Newcombe, S. Love grov e, and A. J. Davison. Dtam: Dense tracking and mapping in real-time. In ICCV , 2011. 3 [35] M. Nießner , M. Zollh ¨ ofer , S. Izadi, and M. Stamminger . Real-time 3d reconstruction at scale using voxel hashing. A CM TOG , 2013. 3 , 5 [36] S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: T o- wards real-time object detection with region proposal net- works. T -P AMI , 2015. 3 , 4 [37] E. Rosten, R. Porter, and T . Drummond. F aster and better: A machine learning approach to corner detection. T -P AMI , 2010. 4 [38] E. Rublee, V . Rabaud, K. K onolige, and G. R. Bradski. Orb: An efficient alternati ve to sift or surf. In ICCV , 2011. 5 [39] O. Russakovsky and et al. ImageNet Large Scale V isual Recognition Challenge. IJCV , 2015. 5 [40] T . Schaul, J. Quan, I. Antonoglou, and D. Silver . Prioritized experience replay. Advances in ICLR , 2016. 7 [41] J. St ¨ uhmer , S. Gumhold, and D. Cremers. Real-time dense geometry from a handheld camera. In D A GM , 2010. 3 [42] R. S. Sutton, D. Precup, and S. Singh. Between mdps and semi-mdps: A frame work for temporal abstraction in rein- forcement learning. AI , 112(1):181–211, 1999. 2 [43] V . V ineet, O. Miksik, M. Lidegaard, M. Nießner , S. Golodetz, V . A. Prisacariu, O. K ¨ ahler , D. W . Murray , S. Izadi, P . Perez, and P . H. S. T orr . Incremental dense se- mantic stereo fusion for large-scale semantic scene recon- struction. In ICRA , 2015. 8 [44] P . V iola and M. J. Jones. Robust real-time f ace detection. IJCV , 2004. 3 [45] C.-C. W ang, C. Thorpe, S. Thrun, M. Hebert, and H. Durrant-Whyte. Simultaneous localization, mapping and moving object tracking. IJRR , 2007. 3 , 4 [46] Z. W ang, T . Schaul, M. Hessel, H. van Hasselt, M. Lanctot, and N. de Freitas. Dueling Network Architectures for Deep Reinforcement Learning. arXiv preprint , 2016. 7 [47] M. D. Zeiler and R. Fergus. V isualizing and understanding con volutional netw orks. In ECCV , 2014. 4
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment