A New Method for Classification of Datasets for Data Mining
Decision tree is an important method for both induction research and data mining, which is mainly used for model classification and prediction. ID3 algorithm is the most widely used algorithm in the decision tree so far. In this paper, the shortcomin…
Authors: Singh Vijendra, Hemjyotsana Parashar, Nisha Vasudeva
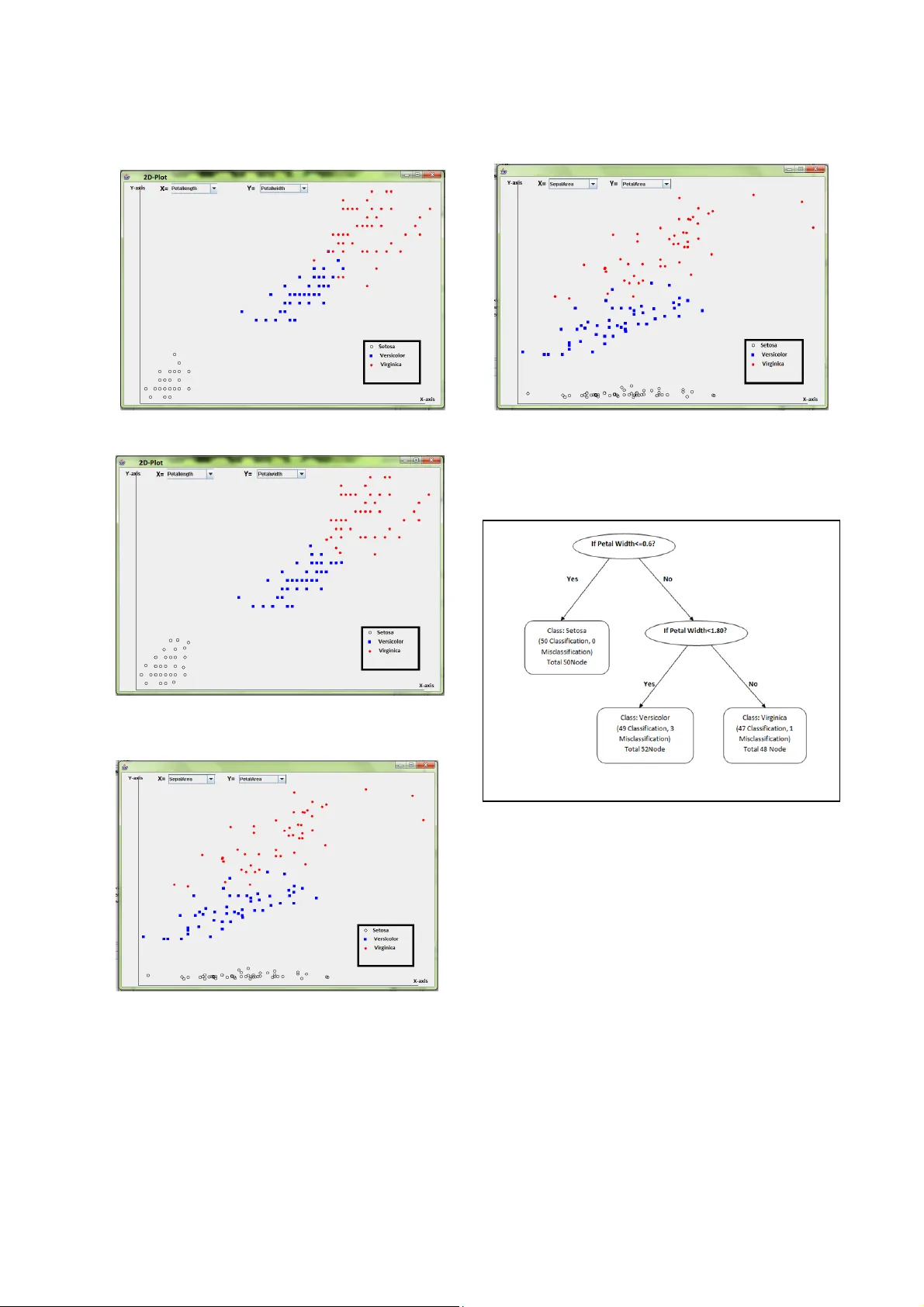
A New Method for Classification of Datasets for Data Mining Singh Vijendra, Hemjyo tsana Parashar and Nisha Vasudeva Faculty of Engineering & Technology, Mody Institute of Technology & Science, La kshmangarh, Sikar, Rajasthan, India d_vijendrasingh@yahoo.co.in and h emjyotsana@gmail.com Abstract —— D ecision tree is a n important method f or both induction research and data mining, which is mainly used for model classifica tion and p rediction. ID3 algorithm is the most widely used algorith m in the d ecision tree so far. In this paper, the shortcoming of ID3's inclining to choose attributes with many values is discussed, an d then a new decision tree algorithm which is improved version of ID3. In our proposed algorithm attributes are divided into groups and then we apply the selection measure 5 fo r these groups. If information gain is not good then again divide att ributes values into groups. These steps are done until we get good classification/misclassification ratio. The proposed algorithms classify the da ta sets more accurately and ef ficiently. Keywords- classification, decision tree, knowledge engineerin g, data mining, supervised learning I. I NTRODUCTION Humans have been manually extracting patterns fro m data for centuries, but the increasing volume of data in modern times has called for more automated approaches. Information leads to po wer and success, and tha nks to sophisticated technologies such as computers, satellites, etc., we have been collectin g tremendous amounts of infor mation. Initia lly, w ith th e adv ent of comput ers and m eans fo r mass digital storage, we s tarted collecting and storing al l sorts of data, counting on the power of computers to help sort through this amalga m of information. Unfortunately, these massive collec tions of data stored on disparate structure s very rapidly beca me overwhelming. A variety of inf orm ation collected in digital form in databases and in flat files . business transactions, scient ific data, medical and personal data, surveillance video a nd pictures, satellite sensing, games, digital media, CAD and software engineeri ng data, virtual worlds, text reports and memos (e-mail messages), The World Wide Web repositories[1, 4]. Ear ly methods of identifying patterns in data include Bayes' theore m (1700s) and regression analysis (1800s). T he proliferation, ubiquity and increasing power of co mputer technology has increased data collection and storage. As data sets have grow n in size and complexity, direct hands-on data analysis has increasingly been aug mented with indirect, auto matic data processing. This has been aided by other disc overies in computer science, such as neural networks, clustering, genetic algorith ms (1950s), decision trees (1960s) and support vector machines (1980s). Data mining is the process of applying these methods to data w ith the intention of uncovering hidden patterns [1,2,13]. Classification is the processing of finding a set of models (or functions) which describe and distin guish data classes or concepts. The derived model is based on the analysis of a set of training data (i.e., data objects whose class label is known). The deri ved mod el may be repre sente d in var ious for ms, such as classification (IF-THEN) rules, decision trees, mathematical formulae, or neural networks. A decision tree is a flow-chart- like tree structure, where each node denotes a test on a n attribute value, each branch represents an outcome of the test, and tree leaves represent classes or class distributi ons. Decision trees can be easily converted to classification r ules. Decision trees can handle hig h dimensional data. Their representation of acquired knowledge in tree form i s intuitive and generally easy to assimilate by humans. The learning and classification steps of decision tree induction are simple and fast with good accuracy. Decision tree induction algorithms have been used for classification in many application areas, such as medicine, manufacturing and production, financial analy sis, astronomy, and molecular biology. Tree-based learning methods are widely used for machine learning and data mining applications. These methods have a long tradition and are commonly known since the works of [1, 2, and 3]. They are conceptual ly simple yet powerful. The most common way to build decision trees is by top down partitioning, starting with the full training set and recursivel y finding a univariate split that maximizes some local criterion (e.g. gain ratio) until the class distributions the leaf partitio ns are sufficiently pure Pessimistic Error Pruning [3] uses statistically motivated heuristics to determine this utility, while Reduced Error Pruning estimates it by testin g the alternatives on separate independent pruning set. In a decision tree learner named NB Tree is introduced that has Naive Bayes classifiers as leaf nodes and uses a s plit criterion t hat is based direc tly on the performance of Naive Bayes classifiers in all first-leve l child nodes (evaluated by cross-validat ion) an extremely expensive procedure[7] . In [6, 10] a decision tree learner i s described that computes new attributes as linear, quadra tic or logistic discriminate functi ons of attributes at each nod e; these are then also passed down the tree. The leaf nodes are still basically majority classifiers, although the class probability distributions o n the path from the r oot are taken into account. A recursive Bayesian class ifier is introduced in [5]. Lots of improvement is already done on decision tree induction method for 100 % accuracy and many of them achieved the goal also but main problem on these improved V5-551 2011 3rd International Conference on Machine Learning and Computing (ICMLC 2011) 5 978-1-4244-92 3 -4 /11/$26.00 ©2011 IEEE methods is that they required lots of ti me and complex extracted rules. The main idea is to split the data recursively into partitions where the conditional independenc e assumption holds. A decision tree is a mapping from observations about a n item to conclusions about its target value [8, 9, 10, 11, and 12]. Decisi on trees are commonly used in operations research, specifically in decision analysi s, to help identify a strategy most likely to reach a goal. Another use of decision trees is as a descriptive means for calculating conditional probabilitie s. A decision tree (or tree diagram) is a decision support tool that uses a tree-like grap h or model of decisions and their possibl e consequences, including chance event outcomes, resource costs, and utility [13]. Decision tree Induction Method has be en successfully used in expert systems in capturing knowledge. Decision tree induction Method is good for multiple at tribute Data sets. This paper is organized as follows. Proposed classification algorithm is briefly described in section II. Section III contains data description and result analysis. Finally, we conclude in Section IV. II. PROPO SED CLASSIFICATION ALGORITHM Inducing Classification Models is the learnin g of decision trees from class-labeled training tuples. Decision trees can easily be converted to classification rules. In our proposed algorithm attributes values are firstly calculated the range to attribute values then we divide these values into different no of groups (or range). A. Proposed Algorithm . Then below steps are recursivel y performed until we get 100% or nearly 100% classification result [13 ]. These concept or algorithm creates 100% accurate result and tree with minimum depth or simplest decision tree for particular data set. III. EXPERIMENTAL RESULTS The implementation of both the a lgorithms is perfor med on java. All experiments wer e run on a PC with a 2.0GHz processor and 1GB RAM. We create interface for proposed system for classification of data set by using Java S wing. In this paper, different data sets are used. Various data sets are tested. Perfo rmance of the propo sed algorithm is very good for som e data set but som e data set values are so different that entropy is not that good. We tested the proposed algorithm over real data and some synthetic data. The comparison results with ID3 are shown in fig 2, fig 3, and fig 4 . Data s et 1: I RIS Data set co nsis ts of 15 0 data p oints with 3 different classes. Data set 2: Hurricane data set consists of 50 d ata points with 2 different classes. Procedure A: A. Create a node N; (i) if all attributes are in the same class, C then m ark N =leaf node with C labeled. (ii) if attribute list=0 then m ark N =leaf node with D labe led. B. Attribute selection method (D, attribute list) (i) if discrete-valued and multi-way splits allow ed then attribute list i th splitting attribute (ii) For each j th of splitting criterion be the set of data tuples in D satisfying outcome j; if D j is empty then attach a leaf no de and labeled with the majority class in D to node N Else Attach the node returned by generate decision tree (D j , attribute list) to nod e N End if return N End for 1. Initialize No_of_Group =2 2. Calculate the Information gain for each attribute 3. Select best attribute according to information gain and calculate the range of selected attribute 4. Divide the data set into No_of_Group according to the r ange 5. Call Procedure A 6. For each group If All_tuples in same class o r classification then exit. Else No_of_Group++; 7. If all tuples are not in same class goto step 5. 8. If No_of_ Group >=MA X then goto step 3 V5-552 2011 3rd International Conference on Machine Learning and Computing (ICMLC 2011) Figure 1. Classification by ID3 of Iris Data set Figure 2. Classification by proposed a lgorithm of Iris D ata set Figure 3. Classification by ID3 of Iris Data set Figure 4. Classification by proposed algorithm of Iris Data se t The proposed algorithm creates a decision tree of each data sets.The Decision tree for iris data sets is shown in fig 5. Figu re 5. Decision Tree of Iris Da ta set by pro posed algorith m IV. CONC LUSION In this paper, we proposed a new method for classification using Decisio n tree. The proposed method creates decision tree and then extract rules for classification more efficiently then the pervious methods. It also improves the quality of solution and classify the data more accurately then I D3 and C4.5. R EFERENCES [1] D Breiman, L.; Friedman, J.H.; Ols hen, R.A.; and Stone, C.J . Classification and Regress ion Trees . Wadsworth International Group. Belmont, CA: The Wadsworth Stat istics/Probability Series1984. [2] Quinlan, J.R.. Induction of Decision Trees. Machine Learning 1(1) :81- 106, 1986 . [3] Quinlan, J.R. Simplifying Decision Trees. International Journal o f Man-Machine Studies 27:221-234, 1987. V5-553 2011 3rd International Conference on Machine Learning and Computing (ICMLC 2011) [4] Gama, J.; and Brazdil, P. Linear Tr ee. Intelligent Data Analysis 3(1): 1-22, 1999. [5] Langley , P. Induction of Recursive Bayesian Class ifiers. In Brazdil P.B. (ed.), Machine Learning: ECML-93 153-164. Springer, Berlin/Heidelberg~lew York/Tokyo,1993. [6] Witten, I. & Frank, E,"Data Mining : Practical machine learning tools and techniques", 2nd Edition, Morgan Kaufmann, San Francisco, 2005. [7] Yang, Y ., Webb, G. On Why Dis cretization Works for Naive-Bayes Classifiers, Lecture Notes in Computer Science, Volume 2003, Pages 440 – 452. [8] H. Zantema and H. L. Bodlaender, Finding Small Equivalent Decision Tree s is Hard, Internati onal Journal of Fou ndations of Computer Science, 11(2):343-354, 2000. [9] Huang Ming Niu Wenying Liang Xu , “An improved De cision Tree classification algorithm based on ID3 and the application in score analysis”, So ftware Technol. In st., Dalian Jiao Tong Univ., Dali an, China, June 2009. [10] Chai Rui- min Wang Miao ,” A more efficie nt classification s cheme for I D3 ”, Sch. of Electron. & Inf. Eng., Liaoning Tech. Univ., Huludao, China,Version1,329-345,2010. [11] iu Yuxun Xie Niuniu “ Improved ID3 algorithm ”, Coll. of Inf. Sci. & Eng., Henan Univ. of Technol., Zhengzhou, China,465-573,2010. [12] Chen Jin Luo De-l in Mu Fen-xiang ,” An improved ID3 decision tree algorithm ”, Sch. of Inf. Sci. & Technol., Xiamen Univ., Xiamen, China,page 127-134,2009. [13] Jiaw ei Han and Mich eline Kamber , Data Mining: Concepts and Techniques, 2nd edition, Morgan Kaufmann, 2006. V5-554 2011 3rd International Conference on Machine Learning and Computing (ICMLC 2011)
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment