Limbo: A Fast and Flexible Library for Bayesian Optimization
Limbo is an open-source C++11 library for Bayesian optimization which is designed to be both highly flexible and very fast. It can be used to optimize functions for which the gradient is unknown, evaluations are expensive, and runtime cost matters (e…
Authors: Antoine Cully, Konstantinos Chatzilygeroudis, Federico Allocati
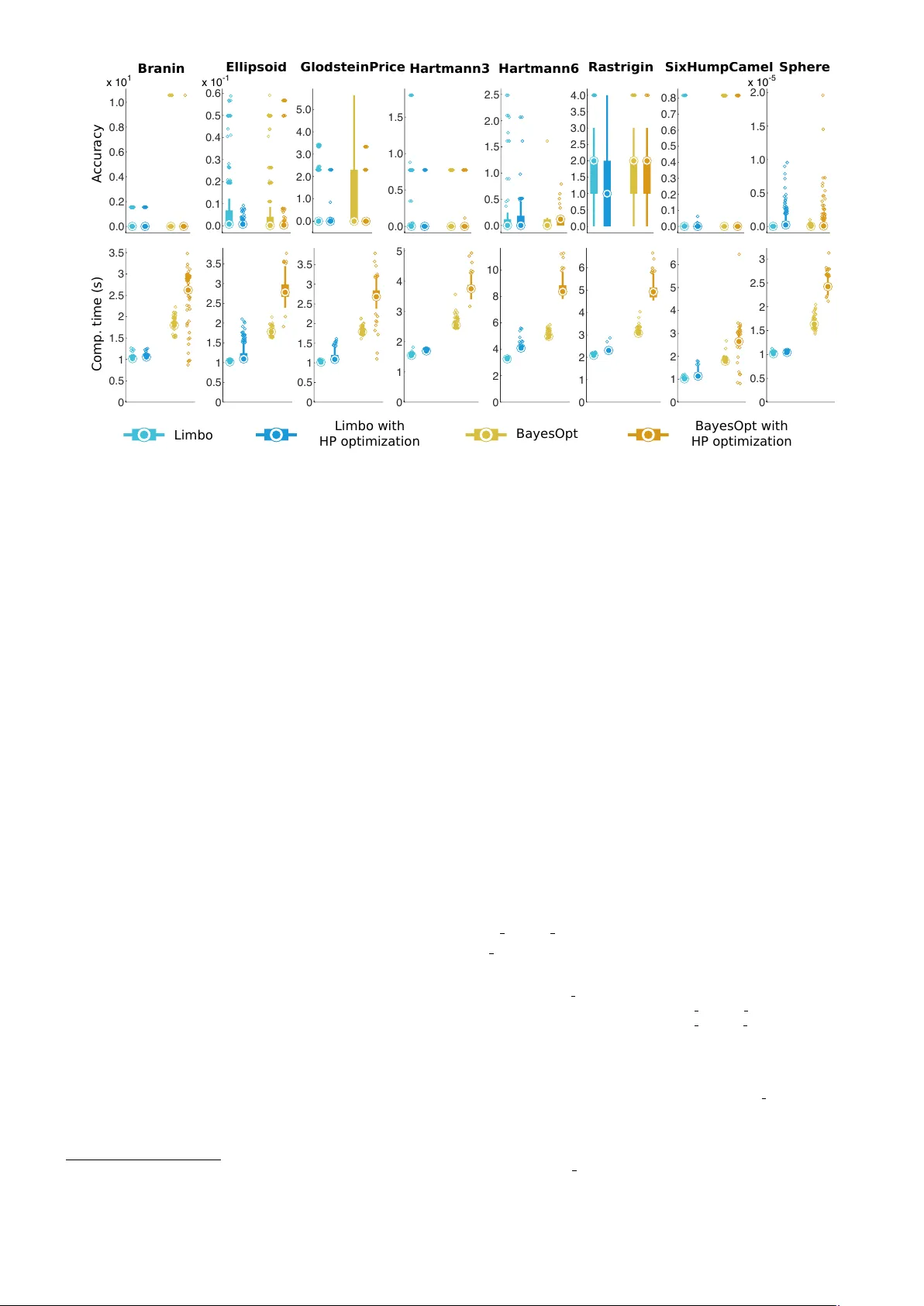
Limb o: A F ast and Flexible Lib ra ry fo r Ba y esian Optimization Antoine Cully 1 , Konstantinos Chatzilygeroudis 2 , 3 , 4 , F ederico Allo cati 2 , 3 , 4 and Jean-Baptiste Mouret 2 , 3 , 4 1 P ersonal Rob otics Lab, Imperial College London, London, UK 2 Inria Nancy Grand - Est, Villers-l` es-Nancy , F rance 3 CNRS, Lo ria, UMR 7503, V andœuvre-l` es-Nancy , F rance 4 Universit´ e de Lo rraine, Lo ria, UMR 7503, V andœuvre-ls-Nancy , F rance Co rresp ondence to: jean-baptiste.mouret@inria.fr Prep rint – Novemb er 23, 2016 Limb o is an op en-source C++11 libra ry for Ba y esian optimization which is designed to b e b oth highly flexi- ble and very fast. It can b e used to optimize functions fo r which the gradient is unknown, evaluations are ex- p ensive, and runtime cost matters (e.g., on emb edded systems o r rob ots). Benchma rks on standard functions sho w that Limbo is ab out 2 times faster than Bay esOpt (another C++ lib rary) fo r a similar accuracy . Intro duction N on-linear optimization problems are p erv asive in mac hine learning. Bay esian Optimization (BO) is de- signed for the most challenging ones: when the gradient is unkno wn, ev aluating a solution is costly , and ev aluations are noisy . This is, for instance, the case when we w ant to find optimal parameters for a machine learning algorithm [Sno ek et al., 2012], because testing a set of parameters can tak e hours, and b ecause of the stochastic nature of man y mac hine learning algorithms. Besides parameter tuning, Ba y esian optimization recen tly attracted a lot of interest for direct p olicy searc h in rob ot learning [Lizotte et al., 2007, Wilson et al., 2014, Calandra et al., 2016] and on- line adaptation; for example, it was recently used to allow a legged robot to learn a new gait after a mec hanical dam- age in ab out 10-15 trials (2 minutes) [Cully e t al., 2015]. A t its core, Bay esian optimization builds a probabilistic mo del of the function to b e optimized (the reward/perfor- mance/cost function) using the samples that hav e already b een ev aluated [Shahriari et al., 2016]; usually , this mo del is a Gaussian process [Williams and Rasm ussen, 2006]. T o select the next sample to be ev aluated, Ba yesian optimiza- tion optimizes an ac quisition function whic h leverages the mo del to predict the most promising areas of the searc h space. Typically , this acquisition function is high in ar- eas not yet explored by the algorithm (i.e., with a high uncertain t y) and in those where the mo del predicts high- p erforming solutions. As a result, Bay esian optimization handles the exploration / exploitation trade-off by select- ing samples that combine a go o d predicted v alue and a high uncertain ty . In spite of its strong mathematical foundations [Mockus, 2012], Bay esian optimization is more a template than a fully-sp ecified algorithm. F or any Bay esian optimization algorithm, the follo wing comp onents need to b e chosen: (1) an initialization function (e.g., random sampling), (2) a mo del (e.g., a Gaussian process, whic h itself needs a kernel function and a mean function), (3) an acquisition function (e.g., Upp er Confidence Bound, Exp ected Improv ement, see Shahriari et al. 2016), (4) a global, non-linear opti- mizer for the acquisition function (e.g., CMA-ES, Hansen and Ostermeier 2001, or DIRECT, Jones et al. 1993) (5) a non-linear optimizer to learn the hyper-parameters of the mo dels (if the user chooses to learn them). Sp ecific applications often require a sp ecific choice of comp onents and most research articles focus on the introduction of a single comp onent (e.g., a nov el acquisition function or a no v el kernel for Gaussian pro cesses). This almost infinite num b er of v ariants of Bay esian optimization calls for flexible libraries in which comp o- nen ts can easily b e substituted with alternative ones (user- defined or predefined). In man y applications, the run-time cost is negligible compared to the ev aluation of a p oten- tial solution, but this is not the case in online adapta- tion for rob ots (e.g., Cully et al. 2015), in which the algo- rithm has to run on small em b edded platforms (e.g., a cell phone), or in in teractive applications [Bro ch u et al., 2010], in which the algorithm needs to quic kly react to the in- puts. T o our kno wledge, no op en-source library combines a high-p erformance implementation of Ba yesian optimiza- tion with the high flexibility that is needed for developing and deplo ying nov el v ariants. The Limb o libra ry Lim b o (LIbrary for Model-based Bay esian Optimiza- tion) is an op en-source (GPL-compatible CeCiLL license) C++11 library which provides a mo dern implemen tation of Bay esian optimization that is b oth flexible and high- p erforming. It do es not dep end on any proprietary soft- w are (the main dep endencies are Bo ost and Eigen3). The co de is standard-complian t but it is currently mostly de- 1 x 10 1 0.0 0.2 0.4 0.6 0.8 1.0 x 10 -1 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.0 1.0 2.0 3.0 4.0 5.0 0.0 0.5 1.0 1.5 0.0 0.5 1.0 1.5 2.0 2.5 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 x 10 -5 0.0 0.5 1.0 1.5 2.0 Limbo Limbo with HP optimization BayesOpt BayesOpt with HP optimization Branin Elli psoid Glodstei nPric e Hartmann3 Hartmann6 Ras tri gin Si xHumpCamel Sp he re Comp. time (s) A ccura cy 0 0.5 1 1.5 2 2.5 3 3.5 0 0.5 1 1.5 2 2.5 3 3.5 0 0.5 1 1.5 2 2.5 3 3.5 0 1 2 3 4 5 0 2 4 6 8 10 0 1 2 3 4 5 6 0 1 2 3 4 5 6 0 0.5 1 1.5 2 2.5 3 Figure 1: Comparison of the accuracy (difference with the optimal v alue) and the w all clock time for Limbo and Ba y esOpt [Martinez-Cantin, 2014] – a state-of-the art C++ library for Bay esian optimization – on common test functions (see http://www.sfu.ca/ ˜ ssurjano/optimization.html ). Two configurations are tested: with and without optimization of the h yp er-parameters of the Gaussian Pro cess. Each exp eriment has b een replicated 250 times. The median of the data is pictured with a thick dot, while the b ox represents the first and third quartiles. The most extreme data p oints are delimited by the whiskers and the outliers are individually depicted as smaller circles. Lim b o is configured to repro duce the default parameters of Ba y esOpt. v elop ed for GNU/Lin ux and Mac OS X with b oth the GCC and Clang compilers. The library is distributed via a GitHub rep ository 1 , in which bugs and further develop- men ts are handled by the comm unity of dev elop ers and users. An extensiv e documentation 2 is av ailable and con- tains guides, examples, and tutorials. New con tributors can rely on a full API reference, while their developmen ts are chec k ed via a contin uous integration platform (auto- matic unit-testing routines). Limbo w as instrumental in sev eral of our robotics pro jects (e.g., Cully et al. 2015) but it has successfully b een used internally for other fields. The implemen tation of Limbo follows a template-based, p olicy-b ase d design [Alexandrescu, 2001], which allows it to b e highly flexible without paying the cost induced b y classic ob ject-oriented designs [Driesen and H¨ olzle, 1996] (cost of virtual functions). In practice, changing one of the components of the algorithms in Lim b o (e.g., c hanging the acquisition function) usually requires changing only a template definition in the source co de. This design make it p ossible for users to rapidly exp erimen t and test new ideas while b eing as fast as sp ecialized co de. According to the b enchmarks we p erformed (Figure 1), Lim b o finds solutions with the same lev el of quality as Ba y esOpt [Martinez-Cantin, 2014], within a significan tly lo w er amount of time: for the same accuracy (less than 2 . 10 − 3 b et w een the optimized solutions found by Limbo and Bay esOpt), Limbo is b etw een 1 . 47 and 1 . 76 times 1 http://github.com/resibots/limbo 2 http://www.resibots.eu/limbo faster (median v alues) than Ba y esOpt when the hyper- parameters are not optimized, and b etw een 2 . 05 and 2 . 54 times faster when they are. Using Limb o The p olicy-based design of Limbo allows users to define or adapt v ariants of Bay esian Optimization with very little change in the co de. The definition of the optimized function is achiev ed by creating a functor (an arbitrary ob ject with an op er ator() function) that takes as input a vector and outputs the resulting v ector (Lim b o can supp ort m ulti-ob jectiv e optimization); this ob ject also defines the input and output dimensions of the problem ( dim in , dim out ). F or example, to maximize the function my fun ( x ) = − P 2 i =1 x 2 i sin(2 x i ): s t r u c t m y f u n { s t a t i c c o n s t e x p r s i z e t d i m i n = 2 ; s t a t i c c o n s t e x p r s i z e t d i m o u t = 1 ; E i g e n : : V e c t o r X d o p e r a t o r ( ) ( c o n s t E i g e n : : V e c t o r X d& x ) c o n s t { d o u b l e r e s = − ( x . a r r a y ( ) . s q u a r e ( ) ∗ ( x ∗ 2 ) . s i n ( ) ) . su m ( ) ; r e t u r n l i m b o : : t o o l s : : m a k e v e c t o r ( r e s ) ; } } ; Optimizing my fun with the default parameters only re- quires instantiating a BOptimizer ob ject and call the “op- 2 timize” metho d: l i m b o : : b a y e s o p t : : B O p t i m i z e r < P a r a m s > o p t ; o p t . o p t i m i z e ( m y f u n ( ) ) ; where P a rams is a structure that defines all the parameters in a static wa y , for instance: s t r u c t P a r a m s { / / d e f a u l t p a r a m e t e r s f o r t h e a c q u i s i t i o n f u n c t i o n ’ g p u c b ’ s t r u c t a c q u i g p u c b : p u b l i c l i m b o : : d e f a u l t s : : a c q u i g p u c b { } ; / / c u s t o m p a r a m e t e r s f o r t h e o p t i m i z e r s t r u c t b a y e s o p t b o p t i m i z e r : p u b l i c l i m b o : : d e f a u l t s : : b a y e s o p t b o p t i m i z e r { B O P A R AM( d o u b l e , n o i s e , 0 . 0 0 1 ) ; } ; / / . . . } While default functors are pro vided, most of the comp o- nen ts of BOptimizer can be replaced to allo w researchers to in v estigate new v arian ts. F or example, changing the k ernel function from the Squared Exp onential kernel (the default) to another type of kernel (here the Matern-5/2) and using the UCB acquisition function is achiev ed as fol- lo ws: / / d e f i n e t h e t e m p l a t e s u s i n g K e r n e l t = l i m b o : : k e r n e l : : M a t e r n F i v e H a l v e s < P a r a m s > ; u s i n g M e a n t = l i m b o : : m e a n : : D a t a < P a r a m s > ; u s i n g G P t = l i m b o : : m o d e l : : GP < P a r a m s , K e r n e l t , M e a n t > ; u s i n g A c q u i t = l i m b o : : a c q u i : : U CB < P a r a m s , G P t > ; / / i n s t a n t i a t e a c u s t o m o p t i m i z e r l i m b o : : b a y e s o p t : : B O p t i m i z e r < P a r a m s , l i m b o : : m o d e l f u n < G P t > , l i m b o : : a c q u i f u n < A c q u i t > > o p t ; / / r u n i t o p t . o p t i m i z e ( m y f u n ( ) ) ; In addition to the many kernel, mean, and acquisition functions that are implemen ted, Limbo provides several to ols for the internal optimization of the acquisition func- tion and the hyper-parameters. F or example, a wrapp er around the NLOpt library (which pro vides many lo cal, global, gradien t-based, and gradient-free algorithms) al- lo ws Lim b o to b e used with a large v ariety of internal opti- mization algorithms. Moreo v er, several “restarts” of these in ternal optimization pro cesses can b e p erformed in par- allel to a void lo cal optima with a minimal computational cost, and several internal optimizations can b e c hained in order to tak e adv an tage of the global asp ects of some al- gorithms and the lo cal prop erties of others. Ackno wledgements This pro ject is funded by the European Research Coun- cil (ERC) under the Europ ean Union’s Horizon 2020 re- searc h and inno v ation programme (Pro ject: ResiBots, gran t agreement No 637972). References Andrei Alexandrescu. Mo dern C++ design: generic program- ming and design patterns applied . Addison-W esley , 2001. Eric Bro chu, Vlad M Co ra, and Nando De F reitas. A tutorial on Bay esian optimization of exp ensive cost functions, with application to active user mo deling and hierarchical rein- fo rcement learning. arXiv p rep rint a rXiv:1012.2599 , 2010. Rob erto Calandra, Andr´ e Seyfarth, Jan Peters, and Mar c P e- ter Deisenroth. Ba yesian optimization fo r lea rning gaits under uncertainty . Annals of Mathematics and Artificial Intelligence , 76(1-2):5–23, 2016. Antoine Cully , Jeff Clune, Danesh T arapore, and Jean- Baptiste Mouret. Rob ots that can adapt like animals. Na- ture , 521(7553):503–507, 2015. Ka rel Driesen and Urs H¨ olzle. The direct cost of virtual func- tion calls in C++. In ACM Sigplan Notices , volume 31, pages 306–323. ACM, 1996. Nik olaus Hansen and Andreas Ostermeier. Completely de- randomized self-adaptation in evolution strategies. Evolu- tiona ry computation , 9(2):159–195, 2001. Donald R Jones, Cary D Perttunen, and Bruce E Stuckman. Lipschitzian optimization without the Lipschitz constant. Journal of Optimization Theory and Applications , 79(1): 157–181, 1993. Daniel J Lizotte, T ao Wang, Michael H Bowling, and Dale Schuurmans. Automatic gait optimization with Gaussian p ro cess regression. In IJCAI , volume 7, pages 944–949, 2007. Rub en Ma rtinez-Cantin. Bay esOpt: a Bay esian optimization lib ra ry for nonlinear optimization, exp erimental design and bandits. Journal of Machine Lea rning Research , 15:3915– 3919, 2014. Jonas Mo ckus. Bay esian approach to global optimization: theo ry and applications , volume 37. Springer Science & Business Media, 2012. Bobak Shahria ri, Kevin Swersky , Ziyu Wang, Ryan P Adams, and Nando de Freitas. T aking the human out of the lo op: A review of Ba yesian optimization. Pro ceedings of the IEEE , 104(1):148–175, 2016. Jasp er Snoek, Hugo La ro chelle, and Ryan P Adams. Practical Ba y esian optimization of machine learning algo rithms. In Advances in neural info rmation p ro cessing systems , pages 2951–2959, 2012. Christopher KI Williams and Carl Edw a rd Rasmussen. Gaus- sian processes fo r machine learning. the MIT Press , 2(3): 4, 2006. Aa ron Wilson, Alan Fern, and Prasad T adepalli. Using trajec- to ry data to imp rove Bay esian optimization for reinfo rce- ment learning. Journal of Machine Lea rning Resea rch , 15 (1):253–282, 2014. 3
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment