Memory Lens: How Much Memory Does an Agent Use?
We propose a new method to study the internal memory used by reinforcement learning policies. We estimate the amount of relevant past information by estimating mutual information between behavior histories and the current action of an agent. We perfo…
Authors: Christoph Dann, Katja Hofmann, Sebastian Nowozin
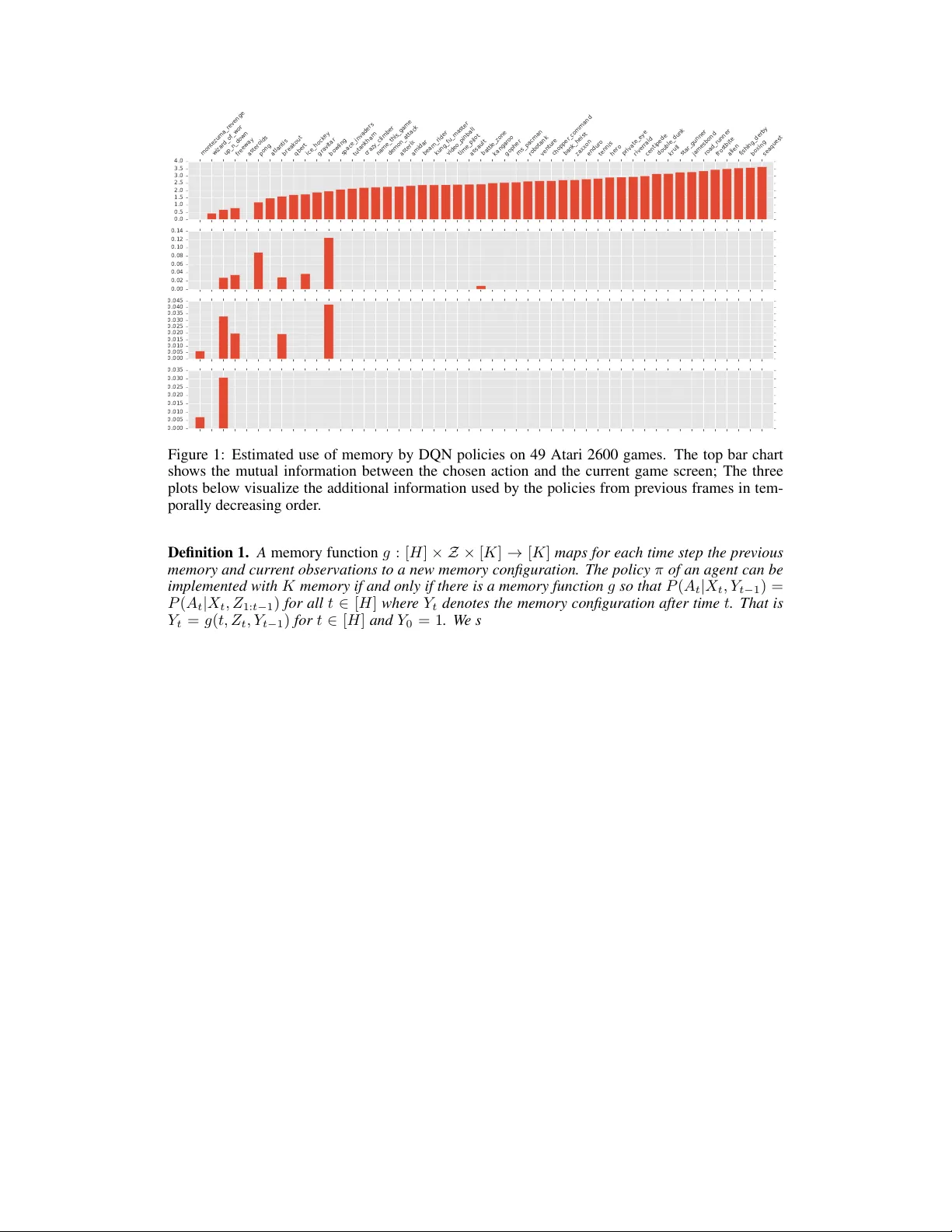
Memory Lens: How Much Memory Does an Agent Use? Christoph Dann CMU cdann@cdann.net Katja Hofmann Microsoft Research Katja.Hofmann@microsoft.com Sebastian Nowozin Microsoft Research senowozi@microsoft.com Abstract W e propose a ne w method to study the internal memory used by reinforcement learning policies. W e estimate the amount of relev ant past information by esti- mating mutual information between beha vior histories and the current action of an agent. W e perform this estimation in the passiv e setting, that is, we do not intervene but merely observ e the natural beha vior of the agent. Moreov er , we provide a theoretical justification for our approach by showing that it yields an implementation-independent lower bound on the minimal memory capacity of any agent that implement the observed policy . W e demonstrate our approach by esti- mating the use of memory of DQN policies on concatenated Atari frames, demon- strating sharply different use of memory across 49 games. The study of memory as information that flows from the past to the current action opens avenues to understand and improv e successful reinforcement learning algorithms. 1 Introduction Can you understand the comple xity of an agent just by observing its behavior? Herbert Simon provided a vivid example by imagining an ant moving along a beach (Simon, 1996). He observed that the path the ant takes while walking toward a certain destination appears highly irregular and hard to describe. This complexity may indicate a sophisticated decision making in the ant, but Simon postulated that instead the ant follows very simple rules and the observed complexity of the path stems from the complexity in the en vironment. In this work we aim to understand the complexity of agents acting according to a fixed policy in an en vironment. In particular , we are interested in the memory of an agent, that is, its ability to use past observations to inform future actions. W e do not assume a specific implementation of the agent, b ut instead observe its beha vior to deri ve statements about its memory . The study of memory in agents is important for two reasons. F irst , most state-of-the-art reinforce- ment learning approaches assume that the en vironment is a Markov decision process (MDP) (Puter- man, 1994), but in contrast most real-world tasks hav e non-Markov structure and are only partially observable by the agent. In such en vironments, optimal decisions may not only depend on the most recent observation but on the entire history of interactions. That is, to solve a task optimally or ev en just reasonably well, an agent might need to remember all previous observations and actions taken (Singh et al., 1994; Krishnamurthy et al., 2016). Second , in many recent algorithms the policy has access to memory of certain fixed capacity . Popular choices include using a fixed window of history (e.g. the last four observ ations as in Mnih et al. (2015)) or recurrent neural networks as adap- tiv e memory (Heess et al., 2015; Li et al., 2015). These approaches are practically successful for specific tasks, but it is unclear ho w much memory capacity they actually use and how much memory capacity to use for different tasks. Our approach allows us to study the use of memory—measured in bits ov er time—independent of the implementation of the agent. 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain. Our method of estimating memory works as follows. W e assume we can ob serve all interactions of an agent’ s policy with the environment in the form of sequences of observation-action-re ward triples. W e then estimate the mutual information between actions and parts of the history . This approach treats the agent and the environment as black boxes which in principle also allows the application of the method to humans or animals as agents. W e provide a theoretical justification of the method in two steps. First, we formally define the minimal memory capacity required to reproduce a giv en policy . Second, we connect our practical estimation method with this formal notion by showing that our method estimates a lower bound to the memory capacity . T o demonstrate the usefulness of our approach we analyze the memory capacity of the state-of-the-art Deep Q-Network policies trained on 49 Atari 2600 games (Mnih et al., 2015). In summary our work makes the follo wing contributions: • A practical method for estimating the memory use of an agent’ s policy from its beha vior; • A theoretical justification in terms of minimum memory capacity; • Insight into the memory use of successful DQN policies on Atari games. 2 Problem Setting and Notation W e consider the following setting: an agent interacts at discrete times t = 1 , 2 , . . . with a stochas- tic en vironment by (1) making an observ ation X t ∈ X , (2) taking an action A t ∈ A and (3) receiving a scalar rew ard R t ∈ R at each of these times. For notational conv enience, we de- note the quantities at time t by Z t = ( X t , A t , R t ) and the concatenation of sev eral time steps by Z k : t = ( Z k , . . . , Z t − 1 , Z t ) . While X t and R t are determined by the environment, the action is sampled from the agent’ s policy and may depend on the entire previous history Z 1 , . . . Z t − 1 , X t . W e assume that the environment is stochastic b ut not necessarily Markov . W e are interested in agents that have mastered a task, which means that learning has mostly ended and the policy changes slowly if at all. W e thus formally assume that the agent’ s policy is fixed for notational simplicity . 1 A trajectory ξ = ( Z 1 , Z 2 , . . . , Z n ) consisting of n time-steps is therefore a random vector sampled from a fixed distribution ξ ∼ P . W e further assume that Z t can take only finitely many values. Giv en one or more trajectories ξ 1 , ξ 2 , · · · ∼ P of the agent interacting with the en vironment, our goal is to estimate the amount of memory required by any agent that implements the observ ed policy . 3 Method: Memory Lens Memory allows the action A t to depend not only on the most recent observation X t but also on the previous history Z 1 , . . . Z t − 1 . One intuiti ve notion to describe the amount of memory used for some action A t is mutual information of action A t and history Z 1 , . . . , Z t − 1 giv en X t , that is, I ( A t ; Z 1: t − 1 | X t ) = E [ D K L ( P ( A t | X t , Z 1: t − 1 ) k P ( A t | X t ))] . This conditional mutual information quantifies the information in bits or nats about action A t one gains by getting to know Z 1: t − 1 when one already knows the value of X t . If this quantity is zero for all t , then the policy is Markov , that is, the action depends only on the most recent observ ation. If it is nonzero, e very implementation of the agent has to use at least some form of memory . Our approach is to estimate the following mutual information quantities M 0 := I ( A t ; X t ); M 1 := I ( A t ; Z t − 1 | X t ); M 2 := I ( A t ; Z t − 2 | X t , Z t − 1 ); (1) M 3 := I ( A t ; Z t − 3 | X t , Z t − 2: t − 1 ); . . . M t − 1 := I ( A t ; Z 1 | X t , Z 2: t − 1 ) . (2) Each entry M i of M quantifies how much additional information about A t can be gained when considering history of length i instead of only i − 1 . The first entry M 0 is the amount of information X t shares with A t . 1 This assumption is not crucial. In the case of changing policies, our results hold for the mixture of policies followed by the agent. 2 3.1 Estimating Mutual Information Mutual information and conditional mutual information can be written as differences of entropy terms, I ( A t ; X t ) = H ( A t ) + H ( X t ) − H ( A t , X t ) and I ( A t ; Z 1: t − k | X t , Z t − k +1: t − 1 ) = H ( A t , X t , Z t − k +1: t − 1 ) + H ( X t , Z t − k : t − 1 ) (3) − H ( A t , X t , Z t − k : t − 1 ) − H ( X t , Z t − k +1: t − 1 ) , (4) where the entropy of multiple random variables is defined by the entropy of their joint distribution. W e can therefore estimate M i by estimating the individual entrop y terms. W e use the entropy estimator by Grassberger (2003) due to its simplicity and computational effi- ciency; alternativ es (plug-in, Nemenman et al. (2002); Hausser and Strimmer (2009)) yielded very similar results in our experimental ev aluations. The Grassber ger (2003) estimate of the entropy in nats of a random quantity Y of which we hav e seen k dif ferent values, each n 1 , . . . , n k times, is (Nowozin, 2012) ˆ H ( Y ) = ln( N ) − 1 N P k i =1 G ( n i ) , where N = P i n i is the total number of samples and G ( n ) = ψ ( n ) + ( − 1) n 2 ψ n +1 2 − ψ n 2 , with ψ being the digamma function . 3.2 T est of Significance In practice the sample size av ailable for estimating the conditional mutual information is limited. Therefore, our estimates will be affected both by bias and statistical variation. T o prevent in valid conclusions due to bias and variation we use a simple permutation test as follo ws. W e take the original set of samples { ( Z t − i : t − 1 , X t , A t ) } for estimating the conditional mutual information ˆ M i and replace the last action by sampling a ne w action ˜ A t ∼ ˆ p ( A t ) from the empirical mar ginal of A t . W e then compute the conditional mutual information ˜ M i w .r .t. the modified samples { ( Z t − i : t − 1 , X t , ˜ A t ) } . This action-resampling process is repeated 100 times to obtain the ordered sequence ˜ M (1) i , . . . ˜ M (100) i with ˜ M ( j ) i ≤ ˜ M ( j +1) i for all j . W e consider memory use significant if ˆ M i is abov e the 95% percentile of this set, i.e., ˆ M i ≥ ˜ M (95) i . 4 Experimental Results W e trained Deep Q-Network policies for 50 million time steps on 49 Atari games. The network structure as well as all learning parameters have been chosen to match the setting by Mnih et al. (2015). Each policy chooses with probability = 0 . 05 an av ailable action uniformly at random and otherwise takes the action that maximizes the learned Q-function. The Q-function tak es as input the last four frames of the games as 84 × 84 pix el grayscale images. W e can interpret this as the agent having memory to perfectly store the last 4 observations. W e applied our memory lens method and estimated to what extent each of these observ ations are actually used when making decisions in each game. W e recorded 10000 games played by each of the fully trained 49 policies. For each policy we used these 10000 trajectories of length up to at most 10000 time steps to estimate the memory use. Since we know that the policies are stationary , we expect their use of memory to be fairly stationary too. W e therefore did not estimate M for the actions at each time t individually but aggregated samples for all actions. The results are shown in Figure 1. The top bar plot shows the mutual information estimate ˆ M 0 of action and most recent frame (requires no memory) and the plots below show ˆ M 1 , ˆ M 2 and ˆ M 3 for the policies of each game. Only bars are displayed that indicate statistically significant dependencies (see Section 3.2). 5 F ormalization of Memory In this section we provide a more formal definition of amount of memory required to implement an agent’ s behavior and relate the quantities M estimated by our memory lens approach to it. For the sak e of conciseness, we focus on finite-horizon episodic decision problems with a fixed horizon of H . A single episode ξ is then an element of Z H . W e use the short-hand notation [ H ] = { 1 , 2 , 3 , . . . , H } . Assume an abstract model of memory where the state of memory can take K ∈ N different v alues. Follo wing the formalization by Chatterjee et al. (2010), we define: 3 montezuma_revenge wizard_of_wor up_n_down freeway asteroids pong atlantis breakout qbert ice_hockey gravitar bowling space_invaders tutankham crazy_climber name_this_game demon_attack asterix amidar beam_rider kung_fu_master video_pinball time_pilot assault battle_zone kangaroo gopher ms_pacman robotank venture chopper_command bank_heist zaxxon enduro tennis hero private_eye riverraid centipede double_dunk krull star_gunner jamesbond road_runner frostbite alien fishing_derby boxing seaquest 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 0.00 0.02 0.04 0.06 0.08 0.10 0.12 0.14 0.000 0.005 0.010 0.015 0.020 0.025 0.030 0.035 0.040 0.045 0.000 0.005 0.010 0.015 0.020 0.025 0.030 0.035 Figure 1: Estimated use of memory by DQN policies on 49 Atari 2600 games. The top bar chart shows the mutual information between the chosen action and the current game screen; The three plots below visualize the additional information used by the policies from previous frames in tem- porally decreasing order . Definition 1. A memory function g : [ H ] × Z × [ K ] → [ K ] maps for each time step the pre vious memory and curr ent observations to a new memory configuration. The policy π of an agent can be implemented with K memory if and only if ther e is a memory function g so that P ( A t | X t , Y t − 1 ) = P ( A t | X t , Z 1: t − 1 ) for all t ∈ [ H ] where Y t denotes the memory configuration after time t . That is Y t = g ( t, Z t , Y t − 1 ) for t ∈ [ H ] and Y 0 = 1 . W e say that g is a memory function for π in this case and denote the set of memory functions with capacity K for π by M M ,π . Note that this abstract model of memory is v ery general and, for example, recurrent neural networks can be considered a direct implementation of it. W e can formally define the minimum amount of memory required by a policy as Definition 2. The memory capacity C ( π ) of a policy π is the smallest amount of memory capacity r equired to r eproduce this policy . F ormally , it is C ( π ) = min { K ∈ N : M K,π 6 = ∅} . If the distribution P from which the episodes are sampled from is known, C ( π ) can be computed in finite time (there are only finitely many memory functions). This implies that in principle C ( π ) can be estimated just from observations by estimating P and then computing C ( π ) . Howe ver , to determine C ( π ) one has to perform tests on equality of conditional probabilities (condition in Def. 1). Each conditional probability has to be estimated accurately which requires infeasibly man y samples for any problem be yond simple toy settings. Instead, the mutual information quantities M used in our method are much easier to estimate. 5.1 P i> 0 M i is a lower bound on log C ( π ) The next corollary states that for any t the sum of all conditional mutual quantities M 1 , . . . , M t − 1 estimated by our memory lens approach (excluding M 0 ) is a lo wer bound on the log-memory ca- pacity . Corollary 1. F or all t ∈ [ H ] , P t − 1 i =1 M i = P t − 1 i =1 I ( A t ; Z i | X t , Z i +1: t − 1 ) ≤ log C ( π ) . Instead of proving this corollary directly , we show a stronger version in the theorem below . This theorem allows to restrict the measure P to an ev ent that can be decided based on the history and shows that this still results in a valid lower bound on log C ( π ) . In some scenarios one might have prior intuition when an agent uses memory to make a decision. One can then restrict the measure to the ev ent E where one expects the memory use will be higher than in Σ \ E and obtain a possibly tighter lower bound on log C ( π ) . 4 Theorem 1. Let k < t and E ∈ σ ( Z 1: t − 1 , X t ) be an event in the sigma-field generated by the history up to time t − 1 and the observation at time t . Denote by P E the pr obability measur e that r estricts P to E . Then I E ( A t ; Z 1: k | X t , Z k +1: t − 1 ) ≤ min g ∈M ∞ ,π log | g ( k , Z , [ H ]) | ≤ log C ( π ) , wher e I E denotes the (conditional) mutual information with r espect to P E . Pr oof. Since Y t is a function of Y k and Z k +1: t for any k < t , the generated sigma-fields sat- isfy σ ( Z 1: t − 1 ) ⊇ σ ( Y k , Z k +1: t − 1 ) ⊇ σ ( Y t − 1 ) . From P ( A t | X t , Y t − 1 ) = P ( A t | X t , Z 1: t − 1 ) , it follows that P E ( A t | X t , Y t − 1 ) = P E ( A t | X t , Z 1: t − 1 ) and hence P E ( A t | X t , Y k , Z k +1: t − 1 ) = P E ( A t | X t , Z 1: t − 1 ) . W e can then equiv alently write P E ( A t , X t , Y k , Z k +1: t − 1 ) P E ( X t , Z k +1: t − 1 ) P E ( X t , Z k +1: t − 1 , Y k ) P E ( X t , Z k +1: t − 1 , A t ) = P E ( A t , X t , Z 1: t − 1 ) P E ( X t , Z k +1: t − 1 ) P E ( X t , Z 1: t − 1 ) P E ( X t , Z k +1: t − 1 , A t ) which implies that I E ( A t ; Z 1: k | X t , Z k +1: t − 1 ) = I E ( A t ; Y k | X t , Z k +1: t − 1 ) . W e then can bound the conditional mutual information using basic properties of entropies as I E ( A t ; Z 1: k | X t , Z k +1: t − 1 ) = I E ( A t ; Y k | X t , Z k +1: t − 1 ) = H E ( Y k | X t , Z k +1: t − 1 ) − H E ( Y k | A t , X t , Z k +1: t − 1 ) ≤ H E ( Y k | X t , Z k +1: t − 1 ) ≤ H E ( Y k ) ≤ log | Y k ( E ) | ≤ log | Y k (Ω) | . 6 Related W ork Papapetrou and K ugiumtzis (2016) perform statistical tests based on conditional mutual information to identify the order of Markov chains. This is similar to our method but we are only interested on parts of the stochastic process, namely the agent’ s actions. In the work of T ishby and Polani (2011) mutual information is used as part of an optimization objecti ve for policies. Instead of just for maximum cumulative rew ard, they optimize for the best trade-off between information processing cost and cumulativ e reward. Our definition of a memory function matches the one by Chatterjee et al. (2010). While we are concerned with the analysis of our method, they use memory functions for asymptotic theoretical analysis of memory required to solve POMDPs with parity objecti ves. In the abstract model of memory in Section 5, the memory state is essentially a sufficient statistic summarizing all informa- tion from the past relev ant for any action in the future. Sufficient statistics for general stochastic processes are discussed by Shalizi and Crutchfield (2001) introducing the concept of -machines. Unlike -machines, we require memory to be updated recursiv ely and we are only concerned with the predictiv e power re garding future actions. 7 Conclusion In this paper , we hav e proposed an approach for analyzing memory use of an agent that interacts with an environment. W e ha ve pro vided both a theoretical foundation of our method and demonstrated its effecti veness in an analysis of state-of-the-art DQN policies playing Atari games. Our treatment of memory usage in agents opens up a wide range of directions for follow-up work. First, our method assumes discrete observation and action spaces. The k ey challenge in e xtending to continuous space is the need to ef ficiently compute mutual information of high-dimensional, continuous observ ations. A promising av enue is to e xplore approximations that have been de veloped in domains such as neural coding, such as variational information maximization (Ag akov and Barber, 2004). Another interesting question to explore is whether the estimate of memory use by a policy can be improv ed when the environment can be controlled actively . That is, the behavior of an agent can activ ely be explored by manipulating the observations and re wards the agent receiv es. The task of identifying the ev ents in which the agents requires the maximum amount of memory by manip- ulating its observations could possibly be set up as a reinforcement learning task itself. Further , estimating the amount of memory necessary to solve a task could potentially be used as an empirical measure for difficulty of sequential decision making tasks. Many real-w orld tasks require high-lev el reasoning with longer-term memory . While current reinforcement learning algorithms still mostly fail to achie ve reasonable performance on such tasks, often experts, e.g. humans, can be observed when solving the task. Analyzing their memory use could not only give an indication of ho w difficult a task is but also possibly inform the design of successful reinforcement learning architectures. 5 References Herbert Simon. The Sciences of The Artifical . MIT Press, 3rd edition, 1996. ISBN 0262193744. Martin L Puterman. Markov Decision Pr ocesses: Discr ete Stochastic Dynamic Pro gramming , vol- ume 10. John Wile y & Sons, 1 edition, 1994. ISBN 0471619779. doi: 10.1080/00401706.1995. 10484354. S.P . Singh, T . Jaakk ola, and M.I. Jordan. Learning without state-estimation in partially observ- able Markovian decision processes. In Pr oceedings of the eleventh international confer ence on machine learning , v olume 31, 1994. Akshay Krishnamurthy , Alekh Agarwal, and John Langford. Contextual-MDPs for P A C- Reinforcement Learning with Rich Observations. arXiv , pages 1–30, 2016. V olodymyr Mnih, Koray Kavukcuoglu, David Silver , Andrei a Rusu, Joel V eness, Marc G Belle- mare, Alex Graves, Martin Riedmiller , Andreas K Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wier - stra, Shane Legg, and Demis Hassabis. Human-level control through deep reinforcement learning. Natur e , 518(7540):529–533, 2015. Nicolas Heess, Jonathan J Hunt, T imothy P Lillicrap, and David Silv er . Memory-based control with recurrent neural networks. arXiv , pages 1–11, 2015. Xiujun Li, Lihong Li, Jianfeng Gao, Xiaodong He, Jianshu Chen, Li Deng, and Ji He. Recurrent Reinforcement Learning: A Hybrid Approach. arXiv , pages 1–11, 2015. Peter Grassber ger . Entropy Estimates from Insuf ficient Samplings. arXiv pr eprint physics/0307138 , (7):5, 2003. Ilya Nemenman, Fariel Shafee, and W illiam Bialek. Entropy and inference, revisited. In Advances in Neural Information Pr ocessing , 2002. Jean Hausser and K orbinian Strimmer . Entropy inference and the James-Stein estimator , with appli- cation to nonlinear gene association netw orks. Journal of Machine Learning Resear ch , 10(June): 1469–1484, 2009. Sebastian Nowozin. Impro ved information gain estimates for decision tree induction. In ICML , 2012. Krishnendu Chatterjee, Laurent Doyen, and Thomas A Henzinger . Qualitativ e Analysis of P artially- Observable Marko v Decision Processes. Mathematical F oundations of Computer Science , 6281: 258–269, 2010. M. Papapetrou and D. Kugiumtzis. Markov chain order estimation with conditional mutual infor- mation. Simulation Modelling Practice and Theory , 61, 2016. Naftali T ishby and Daniel Polani. Information Theory of Decisions and Actions. In P erception- Action Cycle , pages 601–636. 2011. ISBN 978-1-4419-1451-4. Cosma Rohilla Shalizi and James P . Crutchfield. Computational mechanics: Pattern and prediction, structure and simplicity. J ournal of Statistical Physics , 104(3-4):817–879, 2001. Felix Agakov and David Barber . V ariational information maximization for neural coding. In Inter- national Confer ence on Neural Information Pr ocessing . Springer , 2004. 6
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment