Nothing Else Matters: Model-Agnostic Explanations By Identifying Prediction Invariance
At the core of interpretable machine learning is the question of whether humans are able to make accurate predictions about a model's behavior. Assumed in this question are three properties of the interpretable output: coverage, precision, and effort…
Authors: Marco Tulio Ribeiro, Sameer Singh, Carlos Guestrin
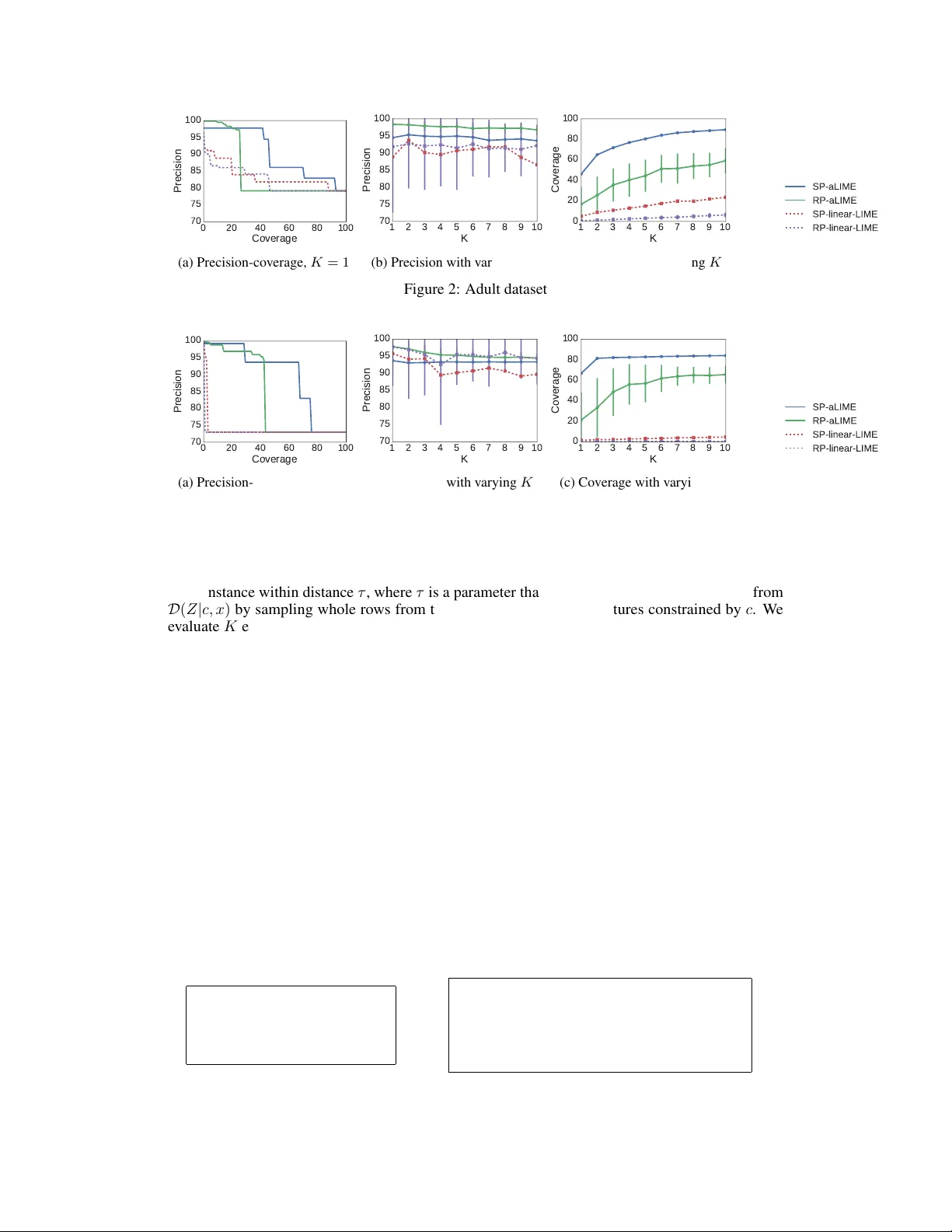
Nothing Else Matters: Model-Agnostic Explanations By Identifying Pr ediction In variance Marco T ulio Ribeiro Univ ersity of W ashington Seattle, W A 98105 marcotcr@cs.uw.edu Sameer Singh Univ ersity of California, Irvine Irvine, CA 92697 sameer@uci.edu Carlos Guestrin Univ ersity of W ashington Seattle, W A 98105 guestrin@cs.uw.edu 1 Introduction At the core of interpretable machine learning is the question of whether humans are able to make accurate predictions about a model’ s behavior . Assumed in this question are three properties of the interpretable output: covera ge , pr ecision , and effort . Coverag e refers to how often humans think they can predict the model’ s behavior , precision to how accurate humans are in those predictions, and effort is either the up-front ef fort required in interpreting the model, or the ef fort required to make predictions about a model’ s behavior . One approach to interpretable machine learning is designing inherently interpretable models. V i- sualizations of these models usually have perfect co verage, b ut there is a trade-off between the accuracy of the model and the ef fort required to comprehend it - especially in complex domains lik e text and images, where the input space is v ery lar ge, and accuracy is usually sacrificed for models that are compact enough to be comprehensible by humans. Experiments usually inv olve sho wing humans these visualizations, and measuring human precision when predicting the model’ s beha vior on random instances, and the time (effort) required to mak e those predictions [7, 8, 9]. Model-agnostic e xplanations [ 12 ] a v oid the need to trade of f accuracy by treating the model as a black box. Explanations such as sparse linear models [ 11 ] (henceforth called linear LIME) or gradients [ 2 , 10 ] can still exhibit high precision and low ef fort (which are de-facto requirements, as there is little point in explaining a model if explanations lead to poor understanding or are too complex) ev en for very complex models by providing explanations that are local in their scope (i.e. not perfect cov erage). Ho wev er , the coverage of such explanations are not explicit, which may lead to human error . T ake the example on Figure 1: we explain a prediction of a comple x model, which predicts that the person described by Figure 1a mak es less than $50K. The linear LIME e xplanation (Figure 1b) sheds some light into why , but it is not clear whether we can apply the insights from this explanation to other instances. In other words, ev en if the explanation is faithful locally , it is not easy to kno w what that local region is. Furthermore, it is not clear when the linear approximation is more or less faithful, e ven within the local re gion. In this paper , we introduce Anchor Local Interpretable Model-Agnostic Explanations (aLIME), a system that e xplains individual predictions with if-then rules (similar to Lakkaraju et al. [9] ) in a model-agnostic manner . Such rules are intuitive to humans, and usually require lo w ef fort to comprehend and apply . In particular , an aLIME explanation (or an anc hor ) is a rule that sufficiently “anchors” a prediction – such that changes to the rest of the instance do not matter (with high probability). For example, the anchor in Figure 1c states that the model will almost always predict Salary ≤ 50 K if a person is not educated beyond high school, regardless of the other features. Such explanations make their cov erage very clear - they only apply when the conditions in the rule are met. W e propose a method to compute such e xplanations that guarantees high precision with a high probability . Further , we present empirical comparison against linear LIME and qualitativ e ev aluation on a variety of tasks (such as text/image classification and visual question answering) to demonstrate that anchors are intuitiv e, ha ve high precision, and v ery clear cov erage boundaries. 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain. Feature V alue Age 37 < Age ≤ 48 W orkclass Priv ate Education ≤ High School Marital Status Married Occupation Craft-repair Relationship Husband Race Black Sex Male Capital Gain 0 Capital Loss 0 Hours per week ≤ 40 Country United States (a) Instance (b) Linear LIME explanation IF Education ≤ High School THEN PREDICT Salary ≤ 50 K (c) aLIME explanation ( anc hor ) Figure 1: Explaining a prediction from the UCI adult dataset. The task is to predict if a person’ s salary is higher than 50,000 dollars ( > 50k) or not ( ≤ 50K). 2 Anchors as Model-Agnostic Explanations Let the model being e xplained be denoted f , such that we explain indi vidual predictions f ( x ) = y . Let an anchor c ∈ C x be defined as a set of constraints (i.e. a rule with conjunctions), C x being the set of all possible constraints that are met by x . For example, in Figure 1c, c = { Education ≤ High School } . W e assume we ha ve a distrib ution of interest D , and that we can sample from D ( z | c, x ) - that is, we can sample inputs where the constraints for the anchor c are met. The reason to condition on x is that D may depend on the instance being explained (for example, see ima ge classification in Section 4). The precision of an anchor is then defined as the expected accurac y (under D ) of applying the anchor to instances that meet its constraints, formalized in Equation 1. Precision ( f , x, c, D ) = E D ( z | c,x ) [ 1 f ( x )= f ( z ) ] (1) As argued before, high precision is a requirement of model-agnostic explanations. It is tri vial to get a perfectly precise (yet useless) anchor by having the constraint set be so specific that only the example being e xplained meets it. In order to balance precision, co verage and ef fort, we optimize the objecti ve in Equation 2, where we try to find the shortest anchor with high precision. The length of the anchor can be used as a proxy for ef fort, and more specific (longer) anchors will naturally hav e less co verage. min c ⊆ C x | c | s.t. Precision ( f , x, c, D ) ≥ 1 − (2) Algorithm: Solving Equation 2 exactly is unfeasible – precision cannot be computed exactly for arbitrary D and f , and finding the best c has combinatorial complexity . T o address the former , we approximate the precision via sampling, and solve the probably approximately correct (P AC) v ersion of Equation 2 so that the chosen anchor will have high precision with high probability . For the latter , we employ an algorithm similar in spirit to lazy decision trees [ 4 ], where we construct c greedily . In particular , at each step, we want to pick the constraint that dominates all other constraints in terms of precision, until the stopping criterion in Equation 2 is met. For ef ficiency , we want to sample as few instances as possible to make each greedy decision. W e use Hoeffding bounds [ 6 ] for the differences in precision to decide when a constraint dominates all the other constraints with high probability . This uses the same insight as Hoef fding trees [ 3 ], with the key dif ference that we can control the sampling distribution, and thus can use the bounds to sample the regions of the input space that reduce the uncertainty between the precision estimates with as fe w samples as possible. Due to lack of space, we omit the details of the algorithm. 3 Simulated Experiments In order to e valuate the difference between linear LIME and anchor LIME (aLIME) in terms of cov erage and precision, we perform simulated experiments on tw o UCI datasets: adult and hospital r eadmission . The latter is a 3-class classification problem, where the task is to predict if a patient will be readmitted to the hospital after an inpatient encounter within 30 days, after 30 days, or nev er . For each dataset, we learn a gradient boosted tree classifier with 400 trees, and generate explana- tions for instances in the validation dataset. W e then e valuate the coverage and precision of these explanations on a separate test dataset. W e use = 0 . 05 for anchor (that is, we e xpect precision to be close to 95 %) unless noted otherwise, and consider that a linear LIME e xplanation cov ers e very 2 0 20 40 60 80 100 Coverage 70 75 80 85 90 95 100 Precision (a) Precision-cov erage, K = 1 1 2 3 4 5 6 7 8 9 10 K 70 75 80 85 90 95 100 Precision (b) Precision with varying K 1 2 3 4 5 6 7 8 9 10 K 0 20 40 60 80 100 Coverage (c) Cov erage with varying K Figure 2: Adult dataset 0 20 40 60 80 100 Coverage 70 75 80 85 90 95 100 Precision (a) Precision-cov erage, K = 1 1 2 3 4 5 6 7 8 9 10 K 70 75 80 85 90 95 100 Precision (b) Precision with varying K 1 2 3 4 5 6 7 8 9 10 K 0 20 40 60 80 100 Coverage (c) Cov erage with varying K Figure 3: Hospital Readmission dataset other instance within distance τ , where τ is a parameter that we v ary . For aLIME, we sample from D ( Z | c, x ) by sampling whole rows from the dataset except for the features constrained by c . W e ev aluate K explanations, chosen either at random (RP) or via Submodular Pick (SP), a procedure that picks explanations to maximize the co verage [11], on the v alidation. W e sho w precision-co verage plots of a single explanation ( K = 1 ) in Figures 2a and 3a, where we vary τ for linear LIME and for aLIME. The results show that for any le vel of cov erage, aLIME has better precision than linear LIME. Furthermore, using submodular pick greatly increases the cov erage at the same precision lev el. Linear LIME performs particularly worse in the dataset with the highest number of dimensions ( hospital readmission ), where the distance degrades. W e note that one of the main advantages of aLIME ov er linear LIME is making its cov erage clear to humans - without human experiments, there is no way to kno w what these plots look like for linear LIME, b ut we can expect them to be the same for aLIME. W e vary the number of explanations the simulated user sees ( K ) in Figures 2b, 2c, 3b and 3c. In order to keep the results comparable, we set = 0 . 05 and picked τ such that the a verage precision at K = 1 for linear LIME was at least 0 . 95 . In both datasets, aLIME is able to maintain higher precision regardless of ho w many e xplanations are sho wn, with cov erage that dominates linear LIME. It is worth noting that both datasets are of the same data type (tabular), and are such that the behavior of the model is simple in a lar ge part of the input space (good conditions for aLIME), as demonstrated by the top 2 anchors that maximize cov erage for each dataset in Figure 4. While these models are complex, their beha vior on most of the input space (65% for adult and 81% for hospital readmission ) is cov ered by these simple rules with high precision. IF Education ≤ High School THEN PREDICT Salary ≤ 50 K IF Marital status = Nev er married THEN PREDICT Salary ≤ 50 K (a) Adult IF Inpatient visits = 0 THEN PREDICT Nev er IF Inpatient visits ≥ 2 AND Emergency visits ≥ 1 AND Outpatient visits ≥ 1 THEN PREDICT > 30 days (b) Hospital readmission Figure 4: T op-2 anchors chosen with Submodular Pick for both datasets 3 Data and prediction Explanation Sentence T ag for word play IF THEN PREDICT I want to play ball. VERB previous w ord is P AR TICLE play is VERB. I went to a play yesterday . NOUN pre vious word is DETERMINER play is NOUN. I play ball on Mondays. VERB previous w ord is PR ONOUN play is VERB. T able 1: Anchors for Part of Speech tagging (a) Original image (b) Anchor for “Zebra” (c) Images with P ( zebra ) > 90% Figure 5: Image classification : explaining a prediction from Inception, and examples from D ( z | c, x ) 4 Qualitative Examples Part-of-Speech tagging: W e use a black box state-of-the-art POS tagger ( http://spacy.io ), and explain tag predictions for the word play in dif ferent conte xts in T able 1. The anchors demonstrate that the POS picks up on the correct patterns. Furthermore, they are short and easy to understand. Anchors are particularly suited for this task, where the dimensionality is small and the beha vior of good models is more easily captured by IF-THEN rules than linear models. Image classification: W e use aLIME to explain a prediction from the Inception V3 classifier on an image of a Zebra in Figure 5, where we first split the image into superpixels. The anchor in Figure 5b means that if we fix the non-grey superpixels, we can substitute the greyed-out superpixels by a random image, and the model will predict “zebra” around 95% of the time. T o illustrate this, we display on Figure 5c a set of images from D ( z | c, x ) (i.e. where the anchor is fixed), and the model predicts “zebra”. While this choice of distribution produces images that look nothing lik e real images (Figure 5c), it makes for more robust explanations than distributions that only hide parts of the image with gray or dark patches ([ 5 , 11 ]). This anchor demonstrates that the model picks up on a pattern that does not require a zebra to have four le gs, or ev en a head - which is a pattern very dif ferent than the patterns humans use to detect zebras. V isual Question Answering: V isual QA [ 1 ] models are multi-modal, and thus can be explained in terms of the image, the question or both. Here, we find anchors on the questions, leaving the image fixed, and use a bigram language model trained on input questions as D . W e select two questions to explain, which are the top rows (in purple) of Figures 6b and 6c. The anchors (in bold), are respectiv ely “What” and “many”, and we sho w questions drawn from D ( z | c, x ) below the original question. The first anchor states that if “What” is in the question, the answer will be “banana” about 95% of the time, while the latter states the same about “many” and “2”, respectively – both explanations clearly indicate undesirable behavior from the model. Again, this kind of explanation is intuiti ve and easier to understand than a linear model, e ven one with high weight on the words “What” and “banana”, as one knows e xactly when it applies and when it does not. (a) Original Image What is the mustache made of? banana What is the ground made of ? banana What is the bed made of ? banana What is this mustache ? banana What is the man made of? banana What is the picture of ? banana (b) How many bananas are in the picture? 2 How many are in the picture? 2 many animals the picture ? 2 How many people are in the picture ? 2 How many zebras are in the picture ? 2 How many planes are on the picture ? 2 (c) Figure 6: V isual QA: explaining predictions from a CNN-LSTM model by looking at the question text (image is fix ed), and examples from D ( z | c, x ) 4 5 Conclusion In this work, we ar gued that high precision and clear co verage bounds are v ery desirable properties of model-agnostic explanations. W e introduced aLIME, a system is designed to produce rule-based explanations that e xhibit both these properties. IF-THEN rules are intuiti ve and easy to understand, and identifying parts of the input that result in prediction inv ariance (i.e. the rest does not matter) is similar to how humans explain many of their choices. W e demonstrated aLIME’ s flexibility by explaining predictions from a variety of classifiers on a myriad of domains, outperforming linear explanations from LIME on simulated e xperiments. References [1] Stanislaw Antol, Aishwarya Agra wal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C. Lawrence Zitnick, and Devi Parikh. Vqa: V isual question answering. In International Conference on Computer V ision (ICCV) , 2015. [2] David Baehrens, T imon Schroeter , Stefan Harmeling, Motoaki Ka wanabe, Katja Hansen, and Klaus-Robert Müller . How to e xplain indi vidual classification decisions. Journal of Machine Learning Resear ch , 11, 2010. [3] Pedro Domingos and Geoff Hulten. Mining high-speed data streams. In Pr oceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , KDD ’00, pages 71–80, New Y ork, NY , USA, 2000. A CM. ISBN 1-58113-233-6. doi: 10.1145/347090.347107. [4] Jerome H. Friedman. Lazy decision trees. In Pr oceedings of the Thirteenth National Confer ence on Artificial Intelligence - V olume 1 , AAAI’96, pages 717–724. AAAI Press, 1996. ISBN 0-262-51091-X. [5] Y ash Goyal, Akrit Mohapatra, Devi Parikh, and Dhruv Batra. Interpreting visual question answering models. ICML W orkshop on V isualization for Deep Learning , 2016. [6] W Hoef fding. Probability inequalities for sums of bounded random v ariables. Journal of the American Statistical Association , pages 13–30, 1963. [7] Johan Huysmans, Karel Dejaeger , Christophe Mues, Jan V anthienen, and Bart Baesens. An empirical e valuation of the comprehensibility of decision table, tree and rule based predicti ve models. Decis. Support Syst. , 51(1):141–154, April 2011. ISSN 0167-9236. doi: 10.1016/j.dss. 2010.12.003. [8] Been Kim, Cynthia Rudin, and Julie A Shah. The bayesian case model: A generative approach for case-based reasoning and prototype classification. In Z. Ghahramani, M. W elling, C. Cortes, N.D. Lawrence, and K.Q. W einberger , editors, Advances in Neural Information Pr ocessing Systems 27 , pages 1952–1960. Curran Associates, Inc., 2014. [9] Himabindu Lakkaraju, Stephen H. Bach, and Jure Leskov ec. Interpretable decision sets: A joint framew ork for description and prediction. In Pr oceedings of the 22Nd ACM SIGKDD International Confer ence on Knowledge Discovery and Data Mining , KDD ’16, pages 1675– 1684, New Y ork, NY , USA, 2016. ACM. ISBN 978-1-4503-4232-2. doi: 10.1145/2939672. 2939874. [10] Grégoire Monta von, Sebastian Bach, Alexander Binder , W ojciech Samek, and Klaus-Robert Müller . Explaining nonlinear classification decisions with deep taylor decomposition. December 2015. [11] Marco T ulio Ribeiro, Sameer Singh, and Carlos Guestrin. “why should I trust you?”: Explaining the predictions of any classifier . In Knowledge Discovery and Data Mining (KDD) , 2016. [12] Marco T ulio Ribeiro, Sameer Singh, and Carlos Guestrin. Model-agnostic interpretability of machine learning. In Human Interpr etability in Machine Learning workshop , ICML ’16, 2016. 5
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment