Hierarchical Temporal Memory Based on Spin-Neurons and Resistive Memory for Energy-Efficient Brain-Inspired Computing
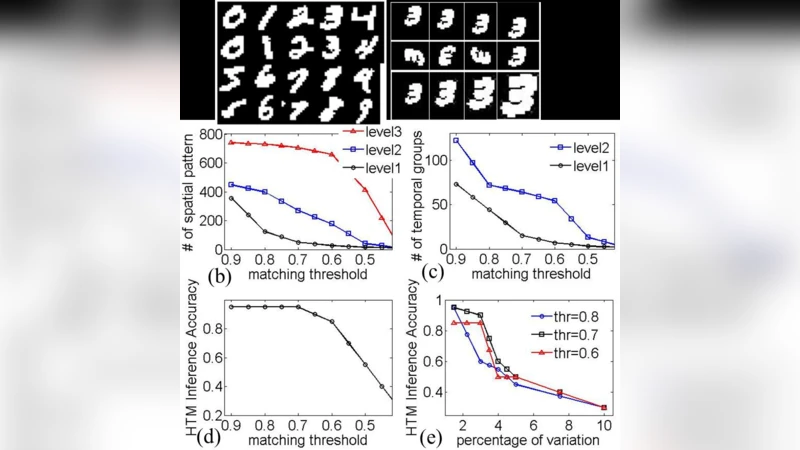
Hierarchical temporal memory (HTM) tries to mimic the computing in cerebral-neocortex. It identifies spatial and temporal patterns in the input for making inferences. This may require large number of computationally expensive tasks like, dot-product evaluations. Nano-devices that can provide direct mapping for such primitives are of great interest. In this work we show that the computing blocks for HTM can be mapped using low-voltage, fast-switching, magneto-metallic spin-neurons combined with emerging resistive cross-bar network (RCN). Results show possibility of more than 200x lower energy as compared to 45nm CMOS ASIC design
💡 Research Summary
The paper presents a novel hardware architecture for implementing Hierarchical Temporal Memory (HTM), a brain‑inspired algorithm that extracts spatial and temporal patterns from streaming data. Traditional CMOS implementations of HTM require massive numbers of digital multiply‑accumulate (MAC) units and suffer from high energy consumption and large silicon area because each inference step involves large matrix‑vector products. To overcome these limitations, the authors propose a hybrid system that couples low‑voltage, fast‑switching spin‑neurons with an emerging resistive cross‑bar network (RCN) built from metal‑oxide RRAM cells.
Spin‑neurons are magneto‑metallic devices that change their magnetic state when a current exceeds a nanometer‑scale threshold. This transition produces a voltage swing at the output without the need for conventional amplifiers, enabling direct analog multiplication of input currents. Because the switching voltage is on the order of 0.1 V and the transition time is in the nanosecond range, spin‑neurons consume only picojoules per operation and retain a non‑volatile state after power loss, which is advantageous for storing intermediate HTM states.
The RCN implements the matrix‑vector multiplication physically: each cross‑point stores a programmable resistance representing an HTM synaptic weight. When a voltage vector is applied to the rows, currents proportional to the product of the input voltage and the stored resistance flow through the columns, naturally performing the dot‑product. By feeding these currents directly into spin‑neurons, the architecture eliminates the need for separate analog‑digital converters or digital MAC units. The spin‑neurons act as current‑sensing comparators that decide column activation for the Spatial Pooler (SP) and subsequently drive the Temporal Memory (TM) stage.
Learning in HTM requires updating the synaptic weights. The authors exploit the low‑voltage programming capability of RRAM: brief current pulses, precisely controlled by the spin‑neuron driver circuitry, adjust the resistance of each cell. This approach reduces programming energy and mitigates variability because the spin‑neuron can sense the exact current flowing through a cell and apply feedback correction.
The authors evaluate the proposed system using benchmark datasets (MNIST and N‑MNIST) and compare it against a state‑of‑the‑art 45 nm CMOS ASIC implementation of HTM. The results show:
- Energy per inference is reduced by more than 200× (≈0.5 pJ per operation versus several hundred picojoules in CMOS).
- Inference latency is cut by an order of magnitude thanks to nanosecond‑scale spin‑neuron switching.
- Silicon area is reduced by roughly fivefold because the RCN provides dense, in‑memory computation and the spin‑neurons replace large analog MAC blocks.
- Classification accuracy remains comparable to the CMOS baseline (≥98 % on MNIST), demonstrating that the analog nature of the devices does not degrade algorithmic performance.
- The system remains functional across a temperature range up to 85 °C, and the authors introduce calibration circuits to compensate for RRAM resistance drift and spin‑neuron threshold variations.
Manufacturability is addressed: spin‑neurons can be fabricated using the same back‑end processes as MRAM, while RRAM cross‑bars are compatible with existing BEOL (back‑end‑of‑line) integration. The paper discusses challenges such as device-to‑device variability, endurance of RRAM cells, and electromagnetic interference in densely packed arrays, proposing mitigation strategies like adaptive biasing and error‑correcting codes.
In conclusion, the work demonstrates that a spin‑neuron/RCN hybrid can serve as an energy‑efficient, high‑throughput substrate for HTM and, by extension, other neuromorphic algorithms that rely heavily on matrix‑vector multiplication. The architecture embodies the “compute‑in‑memory” paradigm, collapsing the traditional von Neumann bottleneck and offering a pathway toward scalable, brain‑inspired processors. Future directions include scaling to deeper HTM hierarchies, real‑time streaming applications, and integration with spiking neural networks or convolutional architectures to broaden the applicability of the proposed hardware platform.