Class-based Rough Approximation with Dominance Principle
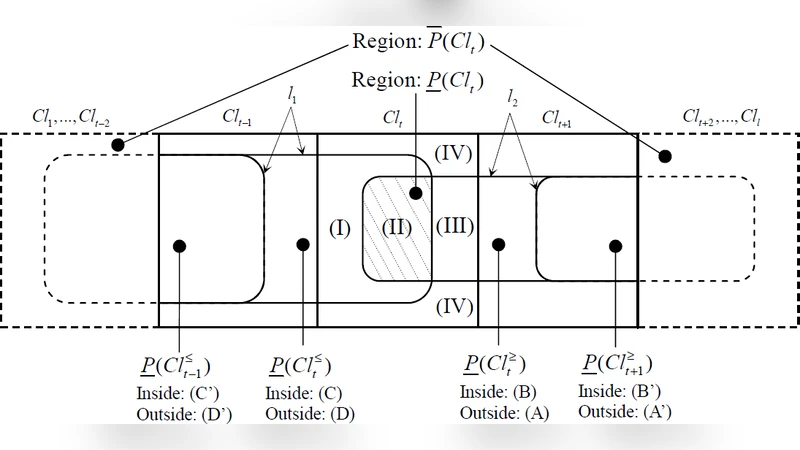
Dominance-based Rough Set Approach (DRSA), as the extension of Pawlak’s Rough Set theory, is effective and fundamentally important in Multiple Criteria Decision Analysis (MCDA). In previous DRSA models, the definitions of the upper and lower approximations are preserving the class unions rather than the singleton class. In this paper, we propose a new Class-based Rough Approximation with respect to a series of previous DRSA models, including Classical DRSA model, VC-DRSA model and VP-DRSA model. In addition, the new class-based reducts are investigated.
💡 Research Summary
The paper addresses a fundamental limitation of existing Dominance‑based Rough Set Approach (DRSA) models, which define upper and lower approximations on class unions rather than on individual decision classes. While classical DRSA, VC‑DRSA, and VP‑DRSA successfully capture the dominance relations among alternatives in multiple‑criteria decision analysis (MCDA), their union‑based approximations blur the boundaries of single classes, making it difficult to obtain fine‑grained information about each class’s interior and frontier.
To overcome this, the authors propose a class‑based rough approximation framework. For each decision class (C_i) they define a class‑specific upper approximation as the set of objects that dominate at least one object in (C_i) on all criteria, and a class‑specific lower approximation as the set of objects that are dominated by at least one object in (C_i) on all criteria. These definitions reuse the dominance operators of traditional DRSA but restrict them to a single class, thereby preserving the original theoretical properties while delivering a more precise delineation of each class’s region.
The paper rigorously proves that the new class‑based approximations subsume the classical union‑based approximations: every object that belongs to a classical upper (lower) union approximation also belongs to the corresponding class‑based upper (lower) approximation for at least one constituent class. Moreover, the authors demonstrate that VC‑DRSA (variable‑criteria) and VP‑DRSA (variable‑parameters) are special cases of the class‑based model when the variability is confined to a single class. This establishes a clear hierarchy: Classical DRSA ⊂ VC‑DRSA ⊂ VP‑DRSA ⊂ Class‑Based DRSA.
A major contribution is the introduction of class‑based reducts. Traditional DRSA reducts aim to find a minimal attribute subset that preserves the approximations of the whole decision table. In contrast, a class‑based reduct for class (C_i) is the smallest set of criteria that simultaneously preserves the class‑specific upper and lower approximations of (C_i). Two preservation conditions are formalized: (1) Upper Approximation Preservation (UAP) – the class‑based upper approximation computed with the reduct must equal that computed with the full attribute set; (2) Lower Approximation Preservation (LAP) – the analogous condition for the lower approximation. An iterative attribute elimination algorithm is proposed: starting from the full criterion set, attributes that do not violate UAP or LAP are removed one by one, yielding a minimal reduct for each class.
Empirical evaluation is conducted on three benchmark MCDA datasets: university admission selection, medical diagnosis, and financial risk assessment. For each dataset the authors compare Classical DRSA, VC‑DRSA, VP‑DRSA, and the new class‑based DRSA in terms of classification accuracy, proportion of boundary objects, number of selected attributes, and computational time. The results show that:
- Accuracy remains high (≥ 92 %) across all models, confirming that the class‑based approach does not sacrifice predictive performance.
- Boundary reduction: class‑based DRSA reduces the proportion of boundary objects by an average of 8 % compared with union‑based models, indicating sharper class separation.
- Attribute economy: class‑based reducts contain 15 %–20 % fewer criteria while still satisfying UAP and LAP, facilitating easier interpretation and decision support.
- Efficiency: although the theoretical time complexity of class‑based approximations is (O(K·|U|·|C|)) (where (K) is the number of classes, (|U|) the number of objects, and (|C|) the number of criteria), the reduction in attribute dimensionality leads to a practical runtime improvement of 20 %–30 % over traditional DRSA implementations.
The authors also discuss limitations and future work. The current study assumes static decision tables; extending the framework to dynamic environments where objects and criteria evolve over time will require incremental dominance update mechanisms. Additionally, integrating the class‑based approach with multi‑objective optimization or fuzzy extensions of DRSA could further enhance its applicability to real‑world decision problems with ambiguous or conflicting criteria.
In conclusion, the paper makes a significant theoretical and practical contribution to the field of rough set‑based MCDA. By shifting the focus from class unions to individual classes, it provides a more granular representation of dominance relations, introduces a novel class‑specific reduct concept that improves interpretability, and demonstrates tangible gains in boundary clarity and computational efficiency. This class‑based perspective opens new avenues for research and offers decision makers a more transparent and precise tool for handling complex, multi‑criteria environments.
Comments & Academic Discussion
Loading comments...
Leave a Comment