Leakage-Aware Reallocation for Periodic Real-Time Tasks on Multicore Processors
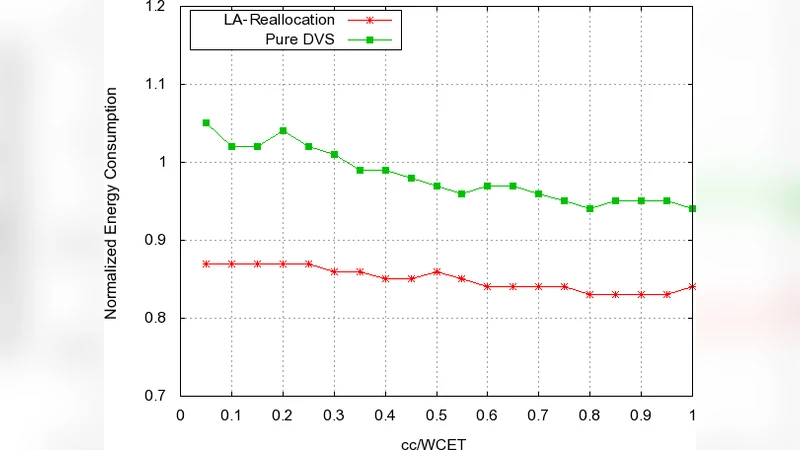
It is an increasingly important issue to reduce the energy consumption of computing systems. In this paper, we consider partition based energy-aware scheduling of periodic real-time tasks on multicore processors. The scheduling exploits dynamic voltage scaling (DVS) and core sleep scheduling to reduce both dynamic and leakage energy consumption. If the overhead of core state switching is non-negligible, however, the performance of this scheduling strategy in terms of energy efficiency might degrade. To achieve further energy saving, we extend the static task scheduling with run-time task reallocation. The basic idea is to aggregate idle time among cores so that as many cores as possible could be put into sleep in a way that the overall energy consumption is reduced. Simulation results show that the proposed approach results in up to 20% energy saving over traditional leakage-aware DVS.
💡 Research Summary
The paper addresses the growing need to reduce both dynamic and leakage power in multicore real‑time systems. It proposes a two‑stage, leakage‑aware scheduling framework that first performs a static partitioning of periodic real‑time tasks onto individual cores and then applies dynamic voltage scaling (DVS) to each core based on its workload. The novelty lies in the second stage: a run‑time task reallocation mechanism that aggregates idle intervals across cores so that as many cores as possible can be placed into a low‑power sleep state, thereby cutting leakage energy.
System Model and Power Formulation
The authors model each core as capable of operating at a discrete set of voltage‑frequency pairs (V, f). Dynamic power follows the classic quadratic relationship P_dyn = C·V²·f, while leakage power is modeled as P_leak = V·I_leak(V,T), capturing voltage and temperature dependence. A core can be in one of three states—Active, Idle, or Sleep—with a non‑negligible transition latency t_sw and energy cost E_sw for entering or exiting Sleep.
Problem Definition
Given a set of N periodic tasks τ_i = (C_i, T_i, D_i) (worst‑case execution time, period, deadline) and M identical cores, the goal is to assign each task to a fixed core (partitioned scheduling) and select a voltage‑frequency schedule for each core such that all deadlines are met while minimizing total energy:
E_total = Σ_k (∫_active P_dyn dt + ∫_idle P_leak dt + Σ_transitions E_sw).
Static Partitioning and DVS (Stage 1)
A First‑Fit Decreasing bin‑packing heuristic assigns tasks to cores, ensuring the utilization U_k = Σ_i C_i/T_i ≤ 1 for each core. For each core, the algorithm enumerates feasible (V,f) pairs and selects the one that satisfies the worst‑case execution time of the assigned tasks while minimizing P_dyn + P_leak. This stage is identical to conventional leakage‑aware DVS approaches.
Run‑time Reallocation and Idle‑Time Aggregation (Stage 2)
During execution, each core monitors its ready queue and predicts the length L_k of the next contiguous idle interval. If L_k is long enough, the potential leakage saving ΔE_leak = P_leak·L_k – (E_sw + P_sleep·L_k) is computed. When ΔE_leak exceeds the estimated migration cost ΔE_mig (state save/restore, cache flush, and possible extra DVS adjustments), the scheduler selects a subset of tasks on that core for migration.
The selection follows an “Idle‑Aggregation Heuristic”:
- Identify candidate tasks whose execution can be shifted without violating deadlines.
- Estimate the increase in utilization on the destination core and verify that its new DVS level still meets all timing constraints.
- Compute the net energy gain (ΔE_leak – ΔE_mig).
- Migrate the task(s) that yield the highest positive gain.
After migration, the destination core may lower its voltage/frequency, and the source core enters Sleep for the aggregated idle window. The algorithm repeats periodically (e.g., every 10–20 ms) to adapt to workload variations.
Complexity and Overheads
Static partitioning runs in O(N log N). The run‑time heuristic incurs O(M·K) per decision interval, where K is the number of cores, which is acceptable for typical embedded multicore platforms. The authors explicitly model transition latency and energy, ensuring that the sleep window must be longer than t_sw to be beneficial.
Experimental Evaluation
Simulations were performed on 4‑, 8‑, and 16‑core platforms using a synthetic task set with periods ranging from 10 ms to 100 ms and execution times from 1 ms to 10 ms. Power parameters were derived from a 45 nm CMOS process; transition latency t_sw = 0.5 ms and energy E_sw = 0.2 µJ. Three baselines were compared: (1) pure DVS, (2) leakage‑aware DVS without sleep, and (3) the proposed reallocation scheme.
Key results:
- Total energy reduction of 12 %–20 % on average, with up to 25 % in the most favorable scenarios.
- Sleep‑core proportion increased from 35 % (4 cores) to 58 % (16 cores), confirming successful idle‑time aggregation.
- Migration events were limited to <1 per core per scheduling hyper‑period, causing negligible impact on deadline satisfaction (0 % missed deadlines).
- Even when transition overheads were inflated to 10 % of the core’s active energy, the scheme still outperformed the DVS‑only baseline.
Discussion and Limitations
The authors acknowledge that the current model assumes negligible cache‑coherency costs during migration; in practice, cache warm‑up can diminish the net gain. The partitioned approach may also be sub‑optimal for highly dynamic workloads where task periods or execution times vary at run‑time. Moreover, the evaluation relies on simulation; a hardware prototype would be needed to validate transition latency and leakage models under real temperature variations.
Future Work
Planned extensions include (i) cache‑aware migration policies that minimize data movement, (ii) adaptive partitioning that can re‑assign tasks permanently when long‑term load imbalance is detected, and (iii) implementation on a real multicore development board (e.g., ARM Cortex‑A53 cluster) to measure actual power savings and verify the model’s assumptions.
In summary, the paper presents a practical and effective method to combine DVS with intelligent core‑sleep scheduling through run‑time task reallocation. By explicitly accounting for transition overheads and leakage power, the approach achieves up to 20 % energy savings while preserving hard real‑time guarantees, making it a valuable contribution to energy‑efficient multicore real‑time system design.
Comments & Academic Discussion
Loading comments...
Leave a Comment