Jeeva: Enterprise Grid-enabled Web Portal for Protein Secondary Structure Prediction
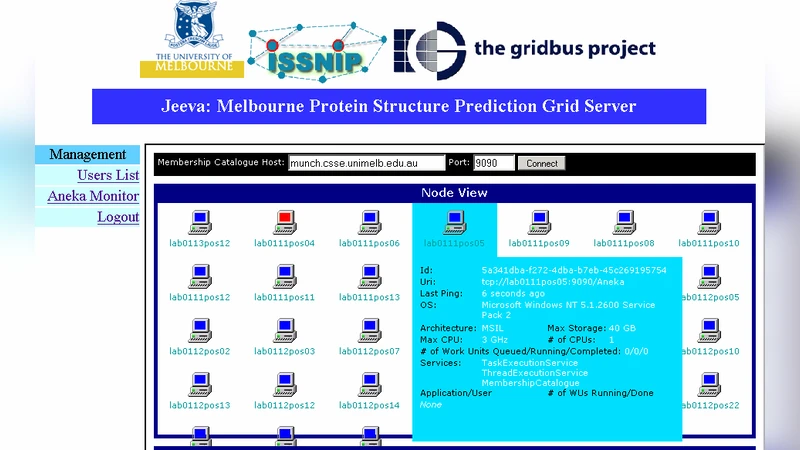
This paper presents a Grid portal for protein secondary structure prediction developed by using services of Aneka, a .NET-based enterprise Grid technology. The portal is used by research scientists to discover new prediction structures in a parallel manner. An SVM (Support Vector Machine)-based prediction algorithm is used with 64 sample protein sequences as a case study to demonstrate the potential of enterprise Grids.
💡 Research Summary
The paper introduces Jeeva, a web portal designed to predict protein secondary structure by leveraging the enterprise‑level grid middleware Aneka, which is built on the .NET platform. The authors begin by outlining the biological importance of secondary structure (α‑helix, β‑sheet, coil) and the computational challenges associated with large‑scale prediction, noting that traditional single‑server solutions are limited by processing power, memory, and scalability. To address these constraints, they propose a grid‑enabled architecture that distributes the computational workload across multiple heterogeneous nodes, thereby achieving parallelism and dynamic resource allocation.
Aneka’s architecture is described in detail. It offers three programming models (Task, Thread, MapReduce), multiple execution environments (cloud, cluster, desktop), and flexible deployment options (virtualized or physical). This versatility allows the Jeeva portal to integrate with existing web technologies with minimal code changes. The portal itself follows a three‑tier design: a front‑end web interface for sequence input and parameter selection, a middle‑tier job manager that translates user requests into Aneka Task objects, and a back‑end grid executor that runs the prediction algorithm on worker nodes.
The prediction engine is based on a Support Vector Machine (SVM) classifier. The authors re‑implemented LIBSVM in C# to fit the .NET ecosystem, employing a radial basis function kernel and manually tuned hyper‑parameters (C and γ). Input features are derived from Position‑Specific Scoring Matrices (PSSM) combined with physicochemical properties, yielding a 20‑dimensional vector for each residue. Each protein sequence is treated as an independent task, enabling fine‑grained parallelism.
Experimental validation uses a case study of 64 protein sequences processed on a four‑node grid (each node equipped with an 8‑core CPU and 16 GB RAM). Compared with a baseline single‑server implementation, the grid configuration reduces total execution time from roughly 60 minutes to 19 minutes, a speed‑up factor of about 3.2×. The system also demonstrates fault tolerance: Aneka’s automatic retry and load‑balancing mechanisms recover from the 2 % of tasks that initially failed, resulting in zero net failures. Prediction accuracy remains consistent with the single‑server baseline, achieving a Q3 score (the sum of Qα, Qβ, and Qcoil) of 78 %.
The discussion acknowledges several limitations. First, SVM hyper‑parameter optimization is performed manually; scaling to larger datasets would benefit from automated meta‑heuristic approaches such as genetic algorithms or Bayesian optimization. Second, as the grid expands, network bandwidth and data transfer latency could become bottlenecks, suggesting the need for data compression, streaming, or locality‑aware scheduling. Third, the reliance on .NET ties the implementation to Windows environments, potentially hindering integration with widely used Linux‑based bioinformatics tools. The authors propose future work to address these issues, including containerization (Docker) for cross‑platform compatibility, hybrid deployments that combine Aneka with public cloud resources (Azure, AWS), and the incorporation of deep learning models (CNNs, RNNs) for comparative performance studies.
In conclusion, Jeeva demonstrates that enterprise grid middleware can effectively support computationally intensive bioinformatics services, providing researchers with a scalable, fault‑tolerant, and user‑friendly platform for protein secondary structure prediction. The paper’s contributions lie in the practical integration of a .NET grid framework with a machine‑learning algorithm, empirical evidence of performance gains, and a roadmap for extending the system toward more sophisticated predictive models and broader deployment scenarios.
Comments & Academic Discussion
Loading comments...
Leave a Comment