Throughput-Delay Trade-off for Hierarchical Cooperation in Ad Hoc Wireless Networks
Hierarchical cooperation has recently been shown to achieve better throughput scaling than classical multihop schemes under certain assumptions on the channel model in static wireless networks. However, the end-to-end delay of this scheme turns out t…
Authors: Ayfer Ozgur, Olivier Leveque
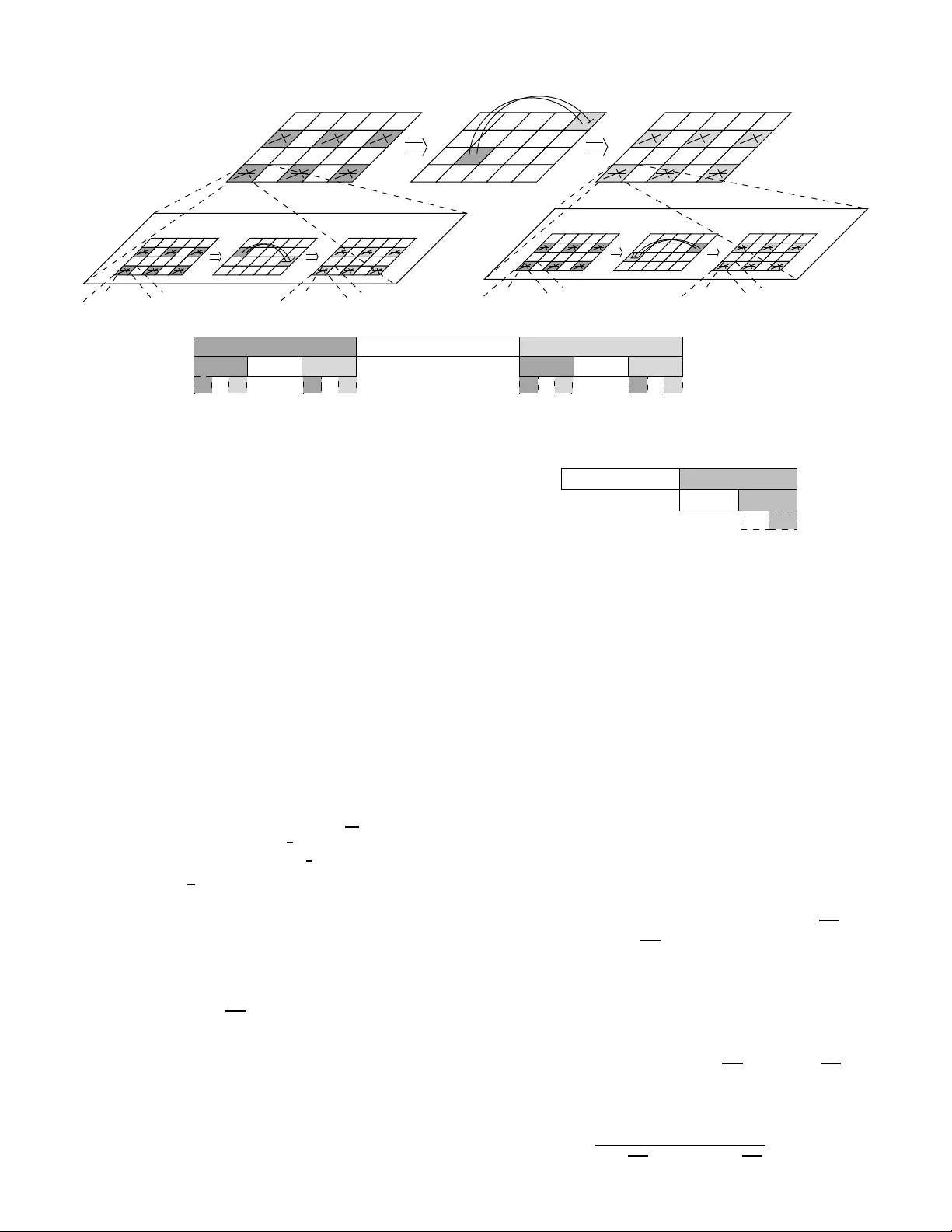
1 Throughp ut-Delay T rade-of f for Hierarc hical Cooperation in Ad Hoc W ir eless Networks A yfer ¨ Ozg ¨ ur , Oli vier L ´ ev ˆ eque, Member , IEEE Abstract — Hierarchical cooperation has r ecently been shown to achiev e better thro ughput scaling than classica l multihop schemes under certain assumpti ons on the channel model in static wireless networks. Howe ver , the end-to-end delay of th is scheme turns out to b e significantly larger than those of multihop schemes. A modification of the scheme is proposed h ere that achieves a throughput-delay trade-off D ( n ) = (log n ) 2 T ( n ) for T ( n ) between Θ( √ n/ log n ) and Θ( n/ log n ) , wh ere D ( n ) and T ( n ) are respectively t he a verag e delay per bit and the aggr egate throughput in a network of n nodes. This trade-off complements the previous results of El Gamal et al., which show that the throughput-delay trade-off for multihop schemes is given by D ( n ) = T ( n ) where T ( n ) lies between Θ(1) and Θ( √ n ) . Meanwhile, the present p aper consid ers th e n etwork multip le- access problem, wh ich may be of interes t in its own right. Index T erms — Ad hoc Wireless Netwo rks, Hiera rchical Coop- eration, Scaling Laws, Thro ughput-Delay T rade-off. I . I N T R O DU C T I O N Scaling laws offer a way of stu dying f undam ental trade- offs in wireless networks as well as o f highlighting the qu alitativ e and arch itectural prop erties of specific d esigns. Such stu dy has been initiated by th e work [1] of Gu pta and Kumar in 2000. Their by now familiar model con siders n nodes random ly distributed on a unit area, each of which w ants to communicate to a random destination a t a c ommon rate R ( n ) . They ask what is the m aximally ach iev able scaling of the agg regate throug hput T ( n ) = nR ( n ) and show that co operation be- tween nodes can dram atically improve p erform ance. Instead of usin g the simple scheme o f time-shar ing between direct transmissions fr om source nod es to de stinations, which o nly achieves aggr egate th rough put Θ (1) , the nodes can cooper ate and re lay the packets b y multih opping from one nod e to th e next, in wh ich c ase an aggregate throug hput scaling of Θ( √ n ) is achieved. T he price to pay , howe ver , is in term s of delay . In the multi-hop s cheme, the packets ne ed to be r etransmitted many times before th ey reach their ac tual destinations, which results in larger end -to-end delay . Mor e precisely , a s sho wn later in [ 2], [3], in a multi-hop sch eme, b its are delivered to their destinatio ns in Θ ( √ n ) time- slots on average a fter they leav e their sou rce nodes, while the a verage d elay for th e simple TDMA sch eme remains only Θ(1) . Note tha t this accou nts only for on-the-fligh t d elay; the queuing delay at the source node is n ot considered . Manuscript recei ve d ??; re vised ??, and ??. The work of A yfer ¨ Ozg ¨ ur was supported by Swiss NSF grant Nr 200020-11 8076. The material in this paper was presented in part at the IEEE Internat ional Confere nce on T eleco mmunicatio ns, Saint -Petersb urg, June 2008. The a uthors are wit h the Ecol e Polyt echniqu e F ´ ed ´ erale de Lausan ne, Facul t ´ e Informatiqu e et Comm unicat ions, Buildi ng INR, Station 14, CH - 1015 Lausanne, Switzerland (e-mails: { ayfer .ozgur , oli vier .leveque } @epfl.ch). Recently , i t has been shown in [4] th at under certain assump- tions on the channel m odel, a much better th rough put scaling is achievable in wireless networks th an the one achieved by classical multi-hop schemes. T he authors exhibit a hierar chical cooper ation scheme that uses d istributed MIMO co mmun ica- tion to achieve agg regate thro ughp ut scaling arbitrar ily c lose to linear, i.e. T h ( n ) = Θ( n h h +1 ) for any integer h > 0 . The parameter h corr esponds to the n umber of hiera rchical lev els used in the scheme an d by increa sing h , one can get arbitrarily close to linear scaling. A natural question is whether there is a price to pay for this superior scaling of the throug hput. In p articular, what is the thro ughpu t-delay trade- off for h ierarchica l cooperatio n? In this paper, we analyz e the delay perfor mance of the hie rarchical cooperation scheme and show that the structure suggested in [4] is very suboptima l from the d elay po int of view . W e propose a mo dification of the scheme in this paper, that achieves much better delay perfor mance for the same throug hput. More precisely , we show that one impo rtant drawback o f the scheme in [4], that is not immediately clear from the presentation in there, is that it uses an extremely large bulk-size, where the bulk-size o f a scheme refer s to the minimu m number of bits th at shou ld be communicated between each source-de stination p air under this sch eme. T he bulk-size used b y th e sch eme in [4] scales as B h ( n ) = Θ( n h 2 ) ; in o ther w o rds, it grows arb itrarily fas t as the throug hput appro aches linear scaling. Note that the bulk-size immediately imposes a lower bou nd on the end-to -end dela y of each com municatio n; even if there is no transmission delay from the source n ode to the d estination node, receiving a bulk of B ( n ) bits will take a t least Θ( B ( n ) / log n ) channel uses for a destination node, sin ce a simple application of the c ut-set bound upper bounds the rate of r eception by (or transmission from) a no de with log n bits per ch annel use. The ba sic idea behin d the hierarch ical cooper ation scheme in [4] is to first d istribute the bits of a source nod e among its neighbo ring n odes, so that these bits can then b e simul- taneously transmitted to a gr oup o f nodes in the vicinity of the destination node. By collecting the obser vations of the receiving nodes to t he actual destinatio n no de, th e destination node is ab le to recover the bits intended for itself. This kind of tra nsmission is often referred to as distributed MIMO since it resembles the multiple -input-m ultiple-ou tput transmis- sions between a tr ansmitter and receiver pair with multip le transmit and receive an tennas re spectiv ely . The ef ficiency o f the distributed MIMO transmission increases with the size of (nu mber of nodes con tained in) th e transmit and r eceiv e clusters, f ormed around the source n ode and the destination node respectively . However , if the size of the transmit cluster is large, the b ulk of data to be commu nicated by each source node has to be large e nough to be chopped off an d distributed among the many nod es in the cluster . Hence, the size of th e transmit cluster imp oses a lower bo und on the bulk size that needs to b e commun icated betwee n ea ch source-d estination pair . Moreover , distributing the bits o f the source node b efore the MIMO transmission and co llecting the o bservations to the destina tion nod e following the MIMO transmission bring s another traffic requirement. It has been shown in [4] that this cooper ation traffic can be hand led efficiently if de composed into multiple prob lems of the or iginal kin d, i.e., of com- municating between n source-d estination pairs in a network of n n odes an d r eusing the ide a o f d istributed MIMO. This recursion builds a h ierarchical a rchitecture that is shown to be efficient from thro ughp ut poin t of view . Howe ver, since distributed MIMO based com municatio n imp oses a lower bound on the bulk-size, repeatin g the idea recu rsiv ely yields a sche me with even larger bulk-size. This is th e r eason why the bulk size of th e hierar chical coop eration scheme increases as Θ( n h 2 ) with h hierarch ical le vels. In this paper, we suggest a mod ification of the hier archi- cal cooper ation scheme in [4] th at handles the p roblem of cooper ation more efficiently . In order to do this, we study the problem of cooperatio n more carefully b y posing it as a network multiple a ccess problem, instead o f separating it into multiple unicast prob lems as was originally don e in [4]. I n the network mu ltiple access prob lem, each of the n nodes in the ne twork is interested in conv eying indepen dent informa tion, say L bits, to each of th e other node s in th e network. W e pr opose a two-phase hierar chical sche me that solves the mu ltiple access p roblem in Θ( n h +1 h ) time-slots for any h > 0 . Using this scheme for coo peration , the m odified hierarchica l cooperatio n scheme achieves the sam e ag gregate throug hput T h ( n ) = Θ( n h h +1 ) by using a mu ch smaller bulk-size B h ( n ) = T h ( n ) . W e show that reduc ed bulk size consequen tly reduces the delay and the modified hie rarchical cooper ation scheme achiev es D h ( n ) = Θ( n ) . W e pro ceed by optim izing scheduling in this scheme to further reduce the en d-to-en d delay . T o do this, we need to consider a genera lized version o f the multiple access problem where each node in the network is interested in co n veying indepen dent in formatio n to each of the no des in a subset of A ( n ) nodes, wh ere the A ( n ) < n nodes a re chosen unifor mly at rand om amon g the n nodes in the network. W e show t hat this task ca n be acco mplished in Θ( A ( n ) n n h h +1 log n ) channel uses f or any h > 0 if A ( n ) ≥ n h h +1 . This allows us to achieve a throu ghpu t delay trade-o ff of ( T ( n ) , D ( n )) = ( n b / lo g n, n b log n ) for any 0 ≤ b < 1 . T his n ew re sult is depicted in Figure 1, together with previous results from th e literature. A related line of resear ch (see e.g. [2], [5], [6], [7]) is the characterizatio n o f the through put-de lay tr ade-off f or mobile n etworks, wh ere no des m ove over the duration of commun ication according to a certain m obility p attern. I n general, mob ility sch emes achieve an agg regate thro ughpu t scaling comparable to that of hierar chical co operatio n (i.e. up Mobility Sche mes 1 1 Multi-hop √ n T(n) D(n) n Cooperation Hierarchical √ n n log n √ n log n √ n log n n log n Fig. 1. Throu ghput-del ay performance achie ved by hierarchic al cooperati on togethe r with known results from the lit erature . to linear in n ), but the delay scaling perfo rmance of such schemes may vary sign ificantly , depen ding on the chosen mobility model. For instance, under the c lassical random walk mobility mo del con sidered in [2], the p erform ance is quite poor, as illustrated in Figur e 1. But from the delay p oint of view , a more prominent disadvantage which is common to all mobility models and which d oes n ot appear on th e g raph in Figure 1, is the con stant th at prece des th e delay scaling law . Roughly spea king, this p re-con stant relates to the speed of nodes in the case of mobility schemes, wh ereas it relates to the speed of light in th e case of hier archical coopera tion. I I . S E T T I N G A N D M A IN R E S U LT S There are n nodes uniformly and indep endently d istributed in a square of unit ar ea. E very n ode is both a source a nd a destination. The sources and destinations are paired up one- to-one in a random fashion withou t any consideration on respective locations. E ach source has the same traffi c rate R ( n ) to s end to it s destination n ode. (In the following text, we will sometimes refer to this tra ffic pattern as the unicast pro blem in order to disting uish it fr om the multicast problem s that will b e discussed in Sections IV and V -B.) The aggregate thr ough put of the system is T ( n ) = nR ( n ) . The co mplex b aseband- equiv alent chan nel gain between node i and node k at time m is given b y: H ik [ m ] = r − α/ 2 ik exp( j θ ik [ m ]) (1) where r ik is the distance between the no des, θ ik [ m ] is the random pha se at time m , un iformly distributed in [0 , 2 π ] and { θ ik [ m ] , 1 ≤ i ≤ n, 1 ≤ k ≤ n } is a collection of i.i.d . random processes. Th e θ ik [ m ] ’ s and the r ik ’ s are also assumed to b e indepen dent. Th e constant α ≥ 2 is c alled the power path loss exponent of the environment. Note that the ch annel is random, dep ending o n the location of the users and the ph ases. The loca tions are assumed to be fixed over th e duration of the communication . The phases are assumed to vary in a stationary e rgodic manner (fast fading). W e assume that th e channel g ains are known at all th e n odes. 2 The signal r eceived by n ode i at time m is giv en by Y i [ m ] = n X k =1 H ik [ m ] X k [ m ] + Z i [ m ] where X k [ m ] is the sign al sent by no de k at time m and Z i [ m ] is white circularly sym metric Gau ssian noise o f variance N 0 per symbo l. Every nod e is subject to a tr ansmit power constraint that we denote by P . 1 The delay D ( n ) of a communicatio n scheme fo r this net- work is define d as the average time it takes fo r a b it, o r p acket of constant size, to reac h its destination n ode af ter it leaves its sourc e node, where the average is taken over all bits or packets tra veling in the network. So d efined, the delay of a scheme quantifies the average time spent by the bits tra veling inside the ne twork while operated un der this scheme. This definitio n o f delay is consistent with [2] , [3] and therefor e the comparison in Figure 1 of the mu ltihop scheme and hier archical coop eration is fair . Howe ver, note that this definition does not include the queuing d elay at the source node, as the clo ck starts when a packet leaves its sour ce node. Th e delay at th e source node can be accou nted f or b y assuming a particu lar packet arrival process and stud ying the overall delay of a packet fro m its arriv al at the sour ce queu e to the decoding at the destination node. Th e transmission delay s giv en in Figure 1 can be regard ed as lower bo unds to this overall delay . C onsider for examp le th e simple T DMA sch eme, one at a time transm ission b etween the source- destination pairs, that cor respond s to the o rigin in Figure 1. Assum e indepen dent Poisson packet a rriv al at each so urce nod e of approp riate rate. If we assume round -robin fashion, backlog unaware scheduling b etween the transmissions, the overall delay o f the TDMA sche me will be Θ( n ) much larger th an the Θ(1) delay predic ted by Figu re 1. Howev er , it is known that this delay can b e reduced to O (log n ) with backlog aw are scheduling [8]. In gene ral, how larger is the overall delay f rom the transmission delay g i ven in Figur e 1 depe nds o n how well we can match the packet ar riv al process with backlog aware s chedulin g schemes. In this paper, o ur aim is to quantif y the transmission d elay of the discu ssed schem es; the secon d question regardin g the queuing delay at the source is left ope n. The following theorem is the ma in result of th is paper . Theor em 2.1: Using h ierarchical coo peration , the following points are achievable o n the thr ough put-delay s caling curve, ( T ( n ) , D ( n )) = Θ n b / lo g n, n b log n where 0 ≤ b < 1 (see Figur e 1). I I I . O V E RV I E W O F T H E H I E R A R C H I C A L C O O P E R AT I O N S C H E M E In this section, we give a brief overview of the hierar- chical coo peration scheme as p resented in [ 4] and establish 1 W e present the low-l e vel assumptions on the chan nel and network model in this section for the sake of complete ness. Ho we ver , most of the discussions in the follo wing sectio ns will re ly on intermediate results established i n [4], hence the dependenc e of the re sults on the low le vel assumptions m ight not be al ways clear . the throug hput-d elay trade-o ff fo r th is scheme. Some of the discussions presented here directly build on results already established in [4]. The hierarchical cooperation schem e is based on clustering the nod es in the network and performin g long-r ange MI MO transmissions between the clusters. The long -rang e MIMO transmissions shou ld be pro ceeded and fo llowed by coop- eration p hases establishing transmit and receive co operation respectively , w hich y ields three su ccessi ve phases in the oper- ation of the network. I f simple TDMA is used fo r establishing cooper ation in ph ase 1 an d 3, the overall schem e achieves a √ n -scaling of the aggregate th rough put. This is th e three phase scheme discussed in Sectio n III-A. Higher th roug hputs can be achieved b y setting the coo peration pro blem as multiple com- munication pro blems and u sing the three phase sch eme as a solution to each of those communication problems. This y ields the idea of recursion and results in a hierarch ical a rchitecture, where increasing the numb er of l ev els in the hierarchy yields an aggregate thro ughpu t scaling arbitrarily close to linear . T he hierarchica l co operatio n sch eme is d iscussed in mo re detail in Section III-B. A. The Thr ee Pha se Scheme The network is di vided into clusters of M 1 nodes and a particular source nod e s sends M 1 bits to its destination n ode d in thr ee steps: (1) Node s first distrib utes its M 1 bits among the M 1 nodes in its cluster, one bit for each no de; (2) These n odes tog ether can th en f orm a distributed transmit antenna array , sending the M 1 bits simultaneously to the destination cluster where d lies; (3) Each n ode in the destina tion cluster gets one o bservation from the MI MO t ransmission, and it qua ntizes and ships the observation to d , wh ich can then do joint MIMO processing o f a ll the o bservations and d ecode th e M 1 transmitted bits. From th e network po int of view , all source-destina tion pairs have to eventually accomplish these three steps. Step 2 is long- range comm unication and only one sou rce-destinatio n pair can operate a t a time. Steps 1 and 3 inv o lve local communica- tion and can be parallelized ac ross sou rce-destinatio n pairs. Combining a ll this leads to th e following three phases in the operation of the n etwork: Phase 1: Setting Up T r ansmit Cooperatio n Clusters work in para llel. W ithin a cluster , each source n ode distributes M 1 bits to the oth er no des, 1 bit f or each n ode, such that at the end of the ph ase, each n ode has 1 bit f rom each of the other nodes in its cluster . (Recall our assumption that ea ch n ode is a source for some commu nication request and a destination for another .) Thus, since there are M 1 source n odes in each cluster , this g iv es a traf fic demand of exchanging M 1 ( M 1 − 1) ∼ M 2 1 bits. Usin g TDMA, on e-at-a-time tr ansmission b etween pairs 3 of nodes, th ese M 2 1 bits can be exchange d in M 2 1 time slots. 2 Phase 2: MIMO T ransmissions Successiv e long- distance MIMO transmissions ar e performed b etween source- destination p airs, o ne at a time. I n e ach one of the MIMO transmissions, say the one between s and d , the M 1 bits of s are simultaneou sly transmitted by th e M 1 nodes in its cluster to the M 1 nodes i n the cluster of d . Each of the lon g-distance MIMO transmissions are rep eated for ea ch source-destination pair in the network, hence we need n time-slots to complete the ph ase. Phase 3: Cooperate to De code Clusters work in par allel. Since there are M 1 destination nodes inside the clusters, each cluster received M 1 MIMO transmissions in ph ase 2 , one intended for e ach of the destination n odes in the c luster . Thus, each node in th e cluster has M 1 received ob servations, one from each o f the MIMO tran smissions, and each ob servation is to be conv eyed to a d ifferent node in its cluster . No des quantize each o bservation in to fixed Q b its, so there are a total of QM 2 1 bits to be exchanged in side each cluster . Using TDMA as in Phase 1 , the p hase can be completed in QM 2 1 time slots. 3 In [4], it is shown that each destination n ode is ab le to decode the transmitted bits from its source no de from the M 1 quantized sign als it gathers by the end o f Phase 3 . The throu ghput achiev ed by the scheme can be calcula ted as follows: each sou rce node is able to transm it M 1 bits to its destination n ode, h ence n M 1 bits in total are delivered to th eir destinations in M 2 1 + n + Q M 2 1 time slots, yield ing an agg regate throug hput of nM 1 M 2 1 + n + QM 2 1 bits per time-slot. Choosing M 1 = √ n to maximize this expression yields an agg regate throughput T ( n ) = 1 2+ Q √ n . Note that as o pposed to multiho p, this three phase scheme allows only b ulk tra nsmission between any sou rce-destinatio n 2 Note that although because of the broadcasting nature of T DMA, e very bit of a source node can be con veyed to all other nodes in the cluster for free, thi s is not wha t we require here. In the MIMO transmissio ns that are follo wing in the next phase, e very node is independentl y encoding its data and it does not need to kno w the bits transmitted by the other nodes. A standard referenc e on the capa city of MIMO channels is [10]. The deri vat ions f or the current case can be found in [4]. 3 In order to be able to con vey the salient feat ures of the hierarchic al coopera tion scheme to the reade r in the simplest way , a rather informal approac h is tak en in this sect ion and some t echnic al details are omitte d. A rigorous description of the scheme can be found in [4]. For example, it is not necessary to ha ve e xactly M 1 nodes in each cluste r but it suf fices to have Θ( M 1 ) nodes for a scaling law anal ysis. It is shown in [4] that by di viding the ne twork into cells of certa in area, we can en sure ha ving Θ( M 1 ) no des in all cell s with high probabilit y . Moreov er, the case when a source node and its destina tion lie i n the same cluste r should be treated separately . Similarly , assuming that each source node is sending e xactly 1 bit to each of the other nodes in its cluster in pha se 1 is a s implifica tion. A rigorous a rgument will assume t hat each sourc e node is sending L bits to eac h of the other nodes where L is a large enough constant independen t of M 1 and n . The rates of the TDMA transmissions in phase 1 and phase 3 and the per node rate for the MIMO transmission in phase 2 are assumed to be 1 for simplicit y , so that 1 bit is transmitte d in 1 time s lot. The actual rates of these transmissions can be sho wn to be constant s depending on the system parameter s a nd independ ent of M 1 and n . Also, in phase 1 and phase 3 not all clusters should be allo wed to operate simul taneousl y but a TDMA scheme be tween the clu sters sho uld be employed so that the resultant inter-cl uster interference is bounded and each clust er becomes acti ve a constan t fraction of time. pair in the ne twork; i.e . one can n ot arbitrarily co mmunica te one bit (or L bits with L co nstant) using the three-ph ase scheme, but M 1 = √ n bits should be tran sferred between ev ery source-destina tion pair with each use of the scheme. The end -to-end delay of this scheme is simply the to tal time for the th ree p hases, since the bits are leaving their so urce nodes at the beginn ing o f the first ph ase and are only decod ed by their respectiv e d estination nodes at the end of the third phase. W ith the ch oice M 1 = √ n , we see that th e delay of the three phase scheme is D ( n ) = (2 + Q ) n . Note that th is delay scaling is muc h worse when c ompared to the d elay o f the multi-ho p scheme achieving same aggregate th roug hput. B. The Hierar chical Coop eration S cheme Higher aggregate thr oughp ut scaling can be ach iev ed by using better n etwork co mmunicatio n schemes th an TDMA to establish the tr ansmit and receive co operatio ns in th e first and third phases of the three p hase scheme d escribed in the previous section. Recall that there ar e M 2 1 and QM 2 1 bits to be exchanged in side each cluster in phases 1 and 3, respecti vely . This traffic demand o f exchan ging M 2 1 bits (or QM 2 1 bits) can be han dled by setting u p M 1 sub-pha ses, and assign ing M 1 pairs in each sub-phase to communicate their 1 b it (or Q bits). The traffic to be hand led at eac h su b-phase now lo oks similar to the origin al network co mmun ication p roblem (the unicast n etwork p roblem defined in Section II), with M 1 users instead of n . Any schem e suggesting a go od solu tion for the original problem can now be u sed inside the sub-phases as an alternative to TDMA; for examp le, the multi-ho p scheme and the three-phase scheme itself would b e two alternativ es both a chieving an agg regate through put scaling Θ( √ M 1 ) (in a network of size M 1 ) as opp osed to the Θ(1) scaling ach iev ed by TDMA. Consider using the three p hase sch eme fo r c ooperatio n as suggested in [4]. More p recisely , we want to handle the traffic of commun icating 1 bit (or Q bits) between the M 1 pairs assigned in each sub -phase of ph ase 1 (or pha se 3 ), by fu rther dividing the c lusters into smaller clu sters of size M 2 and reusing the three phase scheme (TDMA-MI MO-TDMA). Note that this will create a hierarchical structure with two levels . See Figure 2. Note howe ver that the three phase scheme in Section III-A, allows o nly bulk tran smissions between source- destination pairs. In th is particu lar case, one will have to commun icate M 2 bits b etween the so urce-de stination pairs assigned a t eac h sub -phase, as oppo sed to the original req uire- ment o f communicating only 1 bit ( or Q bits). F o r the overall scheme, this in turn inc reases the bulk si ze to b e co mmunic ated between every source- destination pair in the network f rom M 1 bits to M 1 × M 2 bits. So fo r th e 2-le vel hiera rchical sche me, we have to start by assum ing that eac h sou rce node in the network has M 1 × M 2 bits to co mmunica te to its destination node. It can be seen that th ese M 1 × M 2 bits pe r source destination pair , or a total n × M 1 × M 2 bits in the network, can be commun icated in M 1 ( M 2 2 + M 1 + QM 2 2 ) + M 2 n + M 1 Q ( M 2 2 + M 1 + QM 2 2 ) (2) time slots u sing th e 2-lev el hier archical schem e. T he first term M 1 ( M 2 2 + M 1 + QM 2 2 ) is th e completion time of phase-1 4 of the three phase sche me. It is divided into M 1 sessions; in ea ch session, M 1 source-d estination p airs are assigned to commun icate their M 2 bits u sing a thr ee p hase schem e o f TDMA-MIMO- TDMA. Recall fr om the computation s o f the three p hase scheme in Sectio n II that this takes M 2 2 + M 1 + QM 2 2 time slots ( M 1 and M 2 here corresp ond to the n and M 1 , respectively , of the previous section). A similar argu ment holds for th e third term M 1 Q ( M 2 2 + M 1 + QM 2 2 ) in (2) wh ich is the completio n time for phase-3 with the extra Q factor . Note that at th e end of the first phase, each sour ce n ode has distributed its M 1 × M 2 bits among the M 1 nodes in its cluster, hence M 2 bits fo r each node. These bits can be r elayed to the destination cluster in M 2 successiv e MIMO transmissions. Since th e MIM O transmissions have to b e rep eated fo r each o f the n sourc e-destination pairs in the network, the completion time of the seco nd phase is M 2 n in ( 2). Therefo re, the ag gregate throug hput of the 2- lev el scheme is given by the expression M 2 M 1 n M 1 ( M 2 2 + M 1 + Q M 2 2 ) + M 2 n + M 1 Q ( M 2 2 + M 1 + Q M 2 2 ) (3) and the optimal choices of M 1 = n 2 / 3 and M 2 = n 1 / 3 maximize the ag gregate throughput scaling to T 2 ( n ) = M 1 = n 2 / 3 , while the de nominato r dictating the d elay of the scheme is o f order D 2 ( n ) = M 2 × n = n 4 / 3 . Note th at with the 2 -lev el hierarchical schem e, we improve the aggregate th rough put scalin g fr om √ n f or th e th ree-ph ase scheme in the previous section to n 2 / 3 , at the cost of in creasing the bulksize from √ n to n , which , in turn, increa ses the delay from n to n 4 / 3 . The argumen t can be applied recu rsiv e ly to build an h - lev el h ierarchical scheme. The optimal cluster size at the k ’th lev el of an h -lev el hier archical scheme can be compu ted as M k = n h +1 − k h +1 . Th e aggregate th rough put a chieved by an h - lev el hierarchical coope ration scheme is given by T h ( n ) = M 1 = n h h +1 . The bulk-size is B h ( n ) = M h × . . . × M 1 = n h 2 and the end -to-end delay is D h ( n ) = M h × M h − 1 × · · · × M 2 × n = n h 2 + h +2 2( h +1) where w e o bserve that for large h , the delay expo nent is linear in h . The re sults o btained in this section estab lish th e po or delay perfor mance of hiera rchical co operatio n. Note that the delay is mostly due to the large bulk-size used by the sch eme. This is d ifferent from multi-hop schem es since their bulk-size is constant ( Θ(1 ) ) indep endent of the throug hput achiev ed. The delay in multihop is rath er due to the time spent in relayin g the messages inside the network . In the next section , we suggest a mod ification o f the scheme so that it achieves the sam e throug hput using much smaller bulk-size. I V . H I E R A R C H I C A L C O O P E R AT I O N W I T H S M A L L E R B U L K - S I Z E In this sectio n, we treat the pro blem o f coo peration in the three p hase schem e with more care. W e start by defining th e network multiple access pro blem to be the fo llowing. Definition 4.1 (Th e Network Multiple Acce ss Pr oblem) : Consider the assumptio ns on the network and chan nel model giv en in Section II. Let e ach node in th e n etwork be interested in commun icating indep endent info rmation to each of the other n odes in the network . In particu lar , let us assum e that each node has an indep enden t 1 bit message (or L indepen dent bits, with L co nstant) to send to each of the other nod es in th e network an d the quan tity of interest is the smallest time F ( n ) required to accomp lish this task. This problem we refer to b e the network multip le access problem. The fo llowing th eorem provid es an achiev able solution to this prob lem. Theor em 4.1: For any integer h > 0 , the network MAC problem can be solved in F ( n ) ≤ K n h +1 h time-slots w .h.p. 4 , for some con stant K > 0 indepen dent o f n . Pr oof of Theor e m 4.1: Let us start by assuming that th ere exists a schem e that solves the multiple access problem in F ( n ) = n b time-slots with b > 1 . Note that o ne such scheme is simple TDMA that yield s b = 2 . Using this existing scheme, we will con struct a new scheme that yields sm aller F ( n ) . As before, let us start b y di vid ing th e network into clusters of M nodes. Let us first f ocus on o ne specific cluster S an d one node d located outside of this cluster . In particu lar , all nodes in S have 1 bit to send to d . These bits can be com municated to d in two step s: (1) The nod es in S simultaneou sly transmit th eir 1 bit messages destine d to d for ming a distributed transm it antenna array fo r MIMO tr ansmission. The no des in the destination cluster where d lies, for m a distributed receiv e antenna array for this MIMO tran smission. (2) Each n ode in the d estination cluster obtains one observa- tion from the MIMO transmission in the previous phase; it quantizes and ships this observation to d , which can do joint MIMO proce ssing o f all the observations and decode the M transmitted b its from the nodes in S . As a first step tow ard s handling the whole n etwork problem, note th at these two steps should be accomp lished between S and all other nodes in the netw ork. This can again be done in two steps: Phase 1: MIMO transmissions W e perf orm successive long-d istance MIMO transm issions between S an d all other nodes in th e ne twork. In each of the MIM O tran smissions, say b etween S and d , the M n odes in S are simultaneou sly transmitting the 1 bit messages they would like to com mu- nicate to d and th e M nodes in the cluster where d lies are observing the MIMO transmission. The MIMO tran smissions 4 with high probability 5 PHASE 1 PHASE 2 PHASE 3 PHASE 1 PHASE 2 PHASE 3 PHASE 1 PHASE 2 PHASE 3 PHASE 1 PHASE 2 PHASE 3 PHASE 1 PHASE 3 PHASE 2 PHASE 3 PHASE 1 PHASE 2 Fig. 2. The salie nt fe atures of the three phases and the time di vision in a hierarchic al sche me are illu strated. Figure tak en from [4]. should be r epeated for each n ode in the ne twork, hen ce we need n time -slots to comp lete the phase. Phase 2: Cooperate to decode Clusters work in parallel. Since there are M n odes inside each cluster , each clu ster received M MIMO transmissions from S in the p revious phase, o ne inten ded f or each nod e in the cluster . Thus, each node in the cluster has M observations, on e from each of the MIMO tran smissions, a nd each o bservation is intended for a different n ode in the cluster . Each of these o bservations can be qu antized into Q bits, with a fix e d Q , wh ich yie lds exactly the original network multip le acc ess pro blem, with M nodes instead of n . Using the scheme we assumed to exist in the beginning of the pr oof, this task can be co mpleted in QM b time slots. The total time we have spe nt d uring the two phases f or handling the traffic orig inated f rom cluster S is given b y n + QM b . Fro m the network p oint of view , the above two step s should be comp leted fo r all n/ M clusters in the network. T hus, the multicasting task can be completed in n M ( n + QM b ) time slots in total. Choosin g M = n 1 b in order to minimize this quantity yields F ( n ) = (1 + Q ) n 2 − 1 b . Note th at 2 − 1 b < b for b > 1 . In other words, we have established a solution for the multiple access prob lem that is better than the one we started with . Ind eed, the two phase scheme described above can b e used recursively yielding a better schem e at each step of the recur sion. In par ticular, starting with TDMA achieving b = 2 and app lying the idea recursively h times, one g ets a scheme that solves the multiple access prob lem in Θ( n h +1 h ) time slots. Th e operation of this scheme is illustrated in Figure 3. The interest in the multiple access problem ar ises from the fact that it exactly models the required tr affic for cooperation i n the three ph ase sch eme. R ecall the co mmunic ation requir ement inside th e clusters in Phase 1 an d 3 descr ibed in Section III-A. This communication req uirement, eq uiv alen t to a n etwork multiple access prob lem, is h andled using TDMA in the PHASE 1 PHASE 2 PHASE 1 PHASE 2 Fig. 3. The figure illustra tes the time-di vision in the hierarchica l s cheme that solv es the netwo rk multiple access proble m. three p hase scheme wh ich ha s been seen to be sub optimal from throug hput point of view in th e Section II I-A. In the hierarchica l cooperatio n sch eme de scribed in Section I II-B, this multiple access problem is handled by decomp osing it into a num ber of unicast network prob lems. The resultant scheme is optim al in terms of thro ughp ut, but not very satisfying in terms of bulk-size. By using the so lution to the mu ltiple access prob lem suggested in this section, one can mo dify the hierarchica l coope ration sche me, so as to achieve the same throug hput with smaller bulk-size and c onsequen tly smaller delay . The r esultant m odified h ierarchical scheme is illustrated in Figure 4. Note that the gain is comin g from treating the cooper ation pr oblem a s it is and n ot necessarily as multiple unicast prob lems as was previously done in Section III-B. Cor ollary 4 .1: A m odified hierarchical cooperation scheme can achieve an agg regate throug hput T h ( n ) ≥ K 1 n h h +1 with bulk-size B h ( n ) = K 2 n h h +1 and d elay D h ( n ) ≤ K 3 n w .h.p. , for a ny integer h ≥ 0 and so me positi ve con stants K 1 , K 2 , K 3 indepen dent of n . Pr oof of Cor olla ry 4 .1: Consider the th ree ph ase hierar chical scheme described in Section III- A. By Theore m 4.1, the required tr affic fo r tr ansmit and receive cooper ation in ph ase 1 an d phase 3 can be handled in K M h +1 h and K QM h +1 h time slots r espectively . The exp ression for the ag gregate throug hput then becom es M n K M h +1 h + n + K Q M h +1 h 6 PHASE 2 PHASE 1 PHASE 3 PHASE 2 PHASE 2 PHASE 2 PHASE 2 PHASE 3 PHASE 3 PHASE 3 PHASE 3 Fig. 4. T he figure illustrate s the time-di vision in the modified hier archic al sc heme that uses the scheme in Figure 3 for cooper ation. Note the differen ce in operati on of the phases between the modified hie rarchic al coop eration scheme and the origina l hierarchic al coop eration scheme of [4] in Figure 2. which is maximized by the ch oice M = n h h +1 , yielding aggre- gate throug hput T h ( n ) = 1 1+ K + K Q n h h +1 , bulk-size B h ( n ) = n h h +1 and delay D h ( n ) = (1 + K + K Q ) n . V . H I E R A R C H I C A L C O O P E R AT I O N W I T H B E T T E R S C H E D U L I N G In the pre vious sectio n, we presented a mo dified hierarchical scheme th at achieves throu ghput T h ( n ) = Θ( n h h +1 ) u sing bulk-size B h ( n ) = Θ ( n h h +1 ) . Howe ver, the de lay of this scheme is still D h ( n ) = Θ( n ) . I n this section, we o ptimize the schedulin g in the scheme to furthe r impr ove the delay perfor mance to D h ( n ) = Θ( n h h +1 log n ) . W e fir st start by improving the s chedulin g in the three phase scheme with h = 1 discussed in Sec tion III-A. W e then con sider the modified hierarchica l scheme with h ≥ 2 d iscussed in Section I V . Before starting, we state the following binn ing lemma, similar in spirit to Lemm a 4.1 and L emma 5.1 in [4] and can be proven using similar techn iques. Th e lemma will be used repeated ly througho ut the rest of the pap er . Lemma 5.1: Let us assume that f ( n ) balls are thrown in to n bins, in depend ently and unifo rmly at rand om. The following proper ties are satisfied with failure pro bability expon entially small in n . (a) If lim n →∞ f ( n ) n log n = ∞ , then there are Θ( f ( n ) n ) nodes in each bin. (b) If lim n →∞ f ( n ) n = c with c ≥ 0 a constant inde penden t of n , then ther e are at most O (lo g n ) nodes in each bin. A. Better Schedu ling for the Thr ee Phase Scheme Recall the operation of the three p hase scheme from the point of v iew of a single so urce-de stination pair s - d as described in Section II I-A: a step (1) where s distributes its M bits among the M nodes in its cluster , followed by a step (2 ) w here these M b its are simultaneou sly transmitted to the destination cluster via MI MO transmission , and a step (3) wh ere the quantized MIMO observations are collec ted at the d estination node d . These th ree steps need to be e ventually accomplished for each source- destination p air in the network. In this section , we improve the sched uling in accom plishing this task: we organize M su ccessi ve sessions an d allow only n/ M source-d estination pairs to co mplete the thr ee steps in each session. In the beginn ing of each session we random ly choose on e source node from each cluster, thus n/ M sou rce nod es in total. In gen eral, the n/ M destination nodes cor respond ing to these randomly ch osen sou rce n odes can b e located anywh ere. Howe ver, f rom L emma 5.1, we kno w that no m ore th an log n of these destination no des are located in th e same cluster with high probability . W e proceed by acco mplishing th e three steps for these chosen source-d estination pairs: Phase 1: Setting Up T r ansmit Cooperatio n Clusters work in parallel. The ch osen so urce node in each cluster distributes its M bits to the othe r nod es by using TDMA, which ta kes M time-slots in total. Note that as op posed to the scheme described in Sec tion III -A, there is on ly one sou rce nod e operating in each clu ster . Phase 2 : MIMO T ransmissions Successive MIMO trans- missions originated from each c luster are per formed , transmit- ting the bits of th e acti ve source node in each cluster to its respective d estination cluster . Note that in the current case, there is only one MIMO transmission or iginated fro m each cluster , so there are only n/ M MIMO transmissions that need to be per formed in total. Th is will requ ire total time n/ M . Phase 3: Cooperate to Decode Clusters work in pa rallel. Each cluster receiv ed at most log n MI MO transmissions in phase 2 by Lemma 5.1-b , each MI MO transmission intend ed for a different destination node in the cluster . The r eceived observations at each node are q uantized into Q bits and are to be conveyed to the actual destination nod es. The tra ffic inside each cluster is at most o f exchan ging QM log n bits a nd can be completed using TDMA in a t most QM log n time slots. (See Figure 5.) The opera tion continues with the next session b y choosing a new set o f n/ M source no des rando mly among th e n odes that have not yet ac complished th e above steps. Note that all source-d estination p airs will acc omplish th e three steps in a total of M sessions. W ith this rath er smoo ther op eration on the network le vel, we accomplish to serve n/ M sour ce-destination pairs in each session, that is transfer M × n M bits in total to their destinations in M + n M + QM log n time slots yielding agg regate thro ughp ut M × n M M + n M + Q M lo g n (4) which is max imized by the choice M = √ n y ielding ag- gregate throu ghput T ( n ) = 1 2+ Q √ n log n . T he delay experien ced by each bit is now much less co mpared to the three phase scheme in Section III-A, since it is again dictated by th e to tal time spent in the three phases (d enomin ator o f (4)), which is now less than D ( n ) = (2 + Q ) √ n log n . Note that instead of choosing M = √ n , which is the optimal choice to max imize th e through put ach iev ed by the scheme, o ne can choo se M = n b with 0 ≤ b ≤ 1 / 2 . In th is case, we also restrict the n umber of source-destin ation pair s to be served in each sess ion to M , which can b e less than the 7 1 s s 2 d 2 2 d d 1 d 1 Fig. 5. The three phase scheme with better scheduli ng. T he figure illustrate s the operation in one session. total number of clu sters n/ M . Indeed, we o perate one sou rce node in each of the M ( ≤ n/ M ) clusters and simply keep the remaining clusters in activ e. The expression f or the ag gregate throug hput becomes M × M M + M + QM lo g n which implies that the scheme achieves ag gregate throughpu t T ( n ) = n b / lo g n and delay D ( n ) = n b log n fo r any 0 ≤ b ≤ 1 / 2 . Note that th is throug hput- delay trade- off dif fer s only by log n from the trade- off achieved by multi-hop schemes. B. Better Scheduling for the Hierarc h ical Co operation S cheme In th is section, we ado pt the scheduling ide a of Section V -A to the m odified hierarch ical scheme pr esented in Sectio n IV. Howe ver, th is mo dification is not trivial and req uires us to consider a generalized version of the network multiple access problem . Definition 5.1 (Th e Generalized Network MAC Pr ob lem): Consider th e assumptio ns on the n etwork and c hannel mo del giv en in Section II. Let each of the n nod es in the ne twork be interested in con veying indep endent informa tion to a su bset A ( n ) o f the n odes ( A ( n ) ≤ n ), wher e the A ( n ) nod es are chosen random ly amo ng th e n nodes in the network. In particular, let u s assume that each node in the network has an indepen dent 1 b it message (or L independ ent bits, with L co nstant) to send to ea ch of these A ( n ) nodes and the quantity of interest is the minima l time G ( n ) require d to accomplish this task. W e define this to be the g eneralized network multiple access pro blem. The following theor em provides an achiev ab le solution to this prob lem. W e skip the p roof of the theorem since it is similar in spirit to the pr oof of Theor em 4.1. Theor em 5.1: For any integer h > 0 , if A ( n ) ≥ n h h +1 , then the network multiple acc ess proble m can be solved in G ( n ) ≤ K A ( n ) n n h +1 h log( n ) time-slots w .h.p ., fo r some constant K > 0 independent of n . Note that the g eneralized network multiple access prob lem contains the network multiple access problem discussed earlier as a specia l case with A ( n ) = n . Plu gging A ( n ) = n in Theorem 5 .1, we recover the re sult of Theorem 4.1 with an extra log n factor . Indeed, wh en th e condition A ( n ) ≥ n h h +1 is satisfied with strict ineq uality in o rder, t he extra log n factor in Theorem 5.1 is not needed . Ho wev er , it is n eeded to account for the case A ( n ) = n h h +1 , in which case it arises due to p art-b of Lemma 5. 1. W e are now read y to ap ply the schedu ling idea in Sec- tion V -A to the hierarchic al coopera tion scheme. Consider dividing the network into clusters of M 1 nodes and then further d ivide these clu sters in to smaller clusters of size M 2 . Follo wing th e sch eduling id ea in Section V -A, let us organize M 1 / M 2 sessions and for each session rando mly ch oose one small cluster inside every large cluster . On ly the source nodes located in the chosen small clusters an d their correspo nding destination nodes will be served at each s ession. As usual, we are operatin g in three successiv e phases in each session: Phase 1: Setting U p T ransmit Coo peration T he a ctiv e small clusters operate in par allel. Note th at there is a sing le activ e cluster of size M 2 inside e very large c luster of size M 1 . Let S be the chosen small cluster inside the larger cluster L that will operate in th e current session . In this p hase, each of the M 2 source nodes in S ne ed to distribute their M 1 bits among the M 1 nodes in the larger cluster L , ea ch of the M 1 bits goes to a different nod e. This can be accomplished in two sub-pha ses: • Sub-Phase 1: MIMO t ransmissions Successiv e MIMO transmissions are performed between nodes in S and each node in L . In e ach of these MIMO transmissions, say the one be tween S and a n ode d in L (located ou tside o f S ), the M 2 nodes in S are simultan eously tra nsmitting the 1 bit messages th ey would like to communicate to d . The M 2 nodes located in the same small cluster with d are acting as a d istributed receive antenna array fo r this MIMO transmission. Since these MIMO tra nsmissions should b e r epeated for every nod e in L , th is su b-phase takes a total of M 1 time-slots. See Figur e 6. • Sub-Phase 2: Coo perate to Decode All small clusters in the network work in parallel. In particular, each small cluster in L has received M 2 MIMO transmissions fro m S in the previous phase, one MIMO transmission for each node in this small cluster . Thu s, ea ch no de in the small cluster has M 2 observations, one fro m each of th e MIM O transmissions and each o bservation is to be co n veyed to a different no de in th e cluster . Quantizing each obser vation into Q bits, we get the network mu ltiple access problem defined in Section IV in a ne twork o f size M 2 , an d by Theorem 4.1 this prob lem can be handled in QM h 1 +1 h 1 2 time-slots for any integer h 1 > 0 . 8 Fig. 6. The figure illustrates sub-phase 1 of phase 1 of the modified hierarc hical scheme with bett er scheduling. Note that there is only one small cluster distributi ng bi ts inside eve ry large cluster . Phase 2: MIMO T ransmissions A t the en d of the first phase, all source no des in the active small clusters hav e distributed their M 1 bits am ong th e nodes in the larger cluster . Now , suc cessi ve lo ng-distan ce M 1 × M 1 MIMO transmissions between large clu sters ar e perfo rmed. Durin g each MI MO transmission, th e M 1 bits of a particular sou rce no de in the activ e small c luster a re transferred to the destination cluster where its d estination nod e is located. The nu mber of MI MO transmissions to be perfo rmed in this p hase is equ al to the total nu mber of source nodes a ctiv e in this session. Hence the total pha se can be completed in n M 1 × M 2 time-slots. Phase 3 : C ooperate to Decode By pa rt-a of Lemma 5.1, there are or der M 2 destination n odes loc ated in each of the large clusters. Thus, each large cluster has r eceiv ed M 2 MIMO transmissions in th e previous phase, and the quantized MIMO observations spread over the M 1 nodes of the large cluster should be collected at the corre sponding M 2 destination nodes. This is the generalize d network multiple acc ess p roblem of size M 1 with A ( M 1 ) = M 2 . By Theor em 5.1, it can be solved in Q M 2 M 1 × M h 2 +1 h 2 1 log M 1 time-slots f or any in teger h 2 > 0 provided that A ( M 1 ) ≥ M h 2 h 2 +1 1 . Gathering ev erything together, at ev e ry session of this modified hierarch ical coop eration sch eme, we deliver M 1 × M 2 × n M 1 bits to th eir destinations in a total of M 1 + Q M h 1 +1 h 1 2 + n M 1 × M 2 + Q M 2 M 1 × M h 2 +1 h 2 1 log M 1 time-slots. The agg regate throughpu t is given by n M 1 × M 2 × M 1 M 1 + Q M h 1 +1 h 1 2 + n M 1 × M 2 + Q M 2 M 1 × M h 2 +1 h 2 1 log M 1 which is maxim ized by the ch oice h = h 2 = h 1 + 1 , M 1 = n h h +1 and M 2 = M h − 1 h 1 , yielding ag gregate thr ough put T ( n ) = n h h +1 log n and d elay D ( n ) = n h h +1 log n . Note that these choices f or M 1 and M 2 satisfy the constrain t A ( M 1 ) = M 2 ≥ M h 2 h 2 +1 1 . Note that at this point, we have proven that all p oints on the th roug hput-d elay scaling curve ( T ( n ) , D ( n )) = ( n h h +1 / lo g n, n h h +1 log n ) with h b eing a p ositiv e integer are a chiev ab le. In order to show that a ll points o n the line ( T ( n ) , D ( n )) = ( n b / lo g n, n b log n ) with 0 ≤ b < 1 are achiev ab le, we can choose M 1 = n b with 0 ≤ b ≤ h h +1 in the ab ove d iscussion, while main taining the re lationships M 2 = M h − 1 h 1 and h = h 2 = h 1 + 1 . Extendin g the argu ment at th e end o f Section V -A, we also restrict the number of small cluster s to be served in each session to M 1 /h 1 which can now be less than the total number of large clusters n/ M 1 ( ≥ M 1 /h 1 ) . Indeed, we operate on e small cluster in e ach of the M 1 /h 1 large clu sters and simply keep the remaining large clusters inacti ve. The expression f or the a ggregate th rough put becomes M 1 h 1 × M 2 × M 1 M 1 + Q M h 1 +1 h 1 2 + M 1 h 1 × M 2 + Q M 2 M 1 × M h 2 +1 h 2 1 log M 1 which shows that we can achie ve aggregate through put T ( n ) = M 1 / lo g M 1 and d elay D ( n ) = M 1 log M 1 . Recalling that M 1 = n b , we get the po ints o n the throug hput-d elay scaling curve ( T ( n ) , D ( n )) = ( n b / lo g n, n b log n ) f or any 0 ≤ b ≤ h h +1 and h > 0 . This conclud es the proo f of the main result of this pape r . V I . C O N C L U S I O N The present work shows that hierarch ical co operatio n not only can lead to high er th rough put in ad ho c n etworks, but also to reasonable end- to-end delay , giv en that some extra care is taken in setting up coop eration at the lower levels and scheduling comm unication s. Mean while, we have discu ssed the n etwork multip le-access problem in the presen t paper, which is of inte rest in its own right. R E F E R E N C E S [1] P . Gupta and P . R. Kumar , The Capacity of W irele ss Networks , IEEE Tra ns. on Information Theory 42 (2), pp. 388–404 , March 2000. [2] A. El Gamal, J. Mammen, B. Prabhakar , D. Shah, Optimal Throughpu t- Delay Scaling in W ireless Networks-P art I: The F luid Model , IEEE Trans. on Information Theory 52(6), pp. 2568-2592, 2006. [3] A. El Gamal, J. Mammen, B. Prabhakar , D. Shah, Optimal Throughpu t- Delay Scaling in W irele ss Networks-P art II: Constant-Si ze P acke ts , IEEE Tra ns. on Information Theory 52(11), pp. 5111-5116, 2006. [4] A. ¨ Ozg ¨ ur , O. L ´ ev ˆ eque, D. T se, Hiera rc hical cooperati on achie ves optimal capacit y scaling in ad hoc ne tworks , IEEE Transact ions on In formation Theory , V ol. 53 (10), pp. 3549-3572, October 2007. [5] M. Grossglauser and D. Tse, Mobil ity Increases the Capacity of Ad- hoc W ir eless Netwo rks , IEEE/A CM T ransacti ons on Networki ng 10(4), pp. 477-486, 2002. [6] M. J. Neely and E. Modiano, Capacity and Delay T radeof fs for Ad-Hoc Mobile Networks , IEEE Transact ions on Information Theory , V ol. 51 (6), pp. 1917-1937, June 2005. [7] G. Sharma, R. R. Mazumdar and N. B. Shroff, Delay and Capacity T rade-of fs in Mobile Ad Hoc Networks: A Global P erspective , 2006 IEEE INFOCOM Conference, Barcelona , Spain, April 2006. [8] M. Neely , E. Modiano and Y . S. Cheng, Logarit hmic Delay for N × N P ack et Switc hes Under the Cr ossbar Constraint , IE EE/A CM Trans. on Networ king, V ol. 15 (3), June 2007. [9] Gallager R. G. , Information Theory and Reliable Communication , Wil ey & Sons Inc., 1968. [10] E. T elatar , Capacity of Multi-Ant enna Gaussian Channels” E uropean Tra ns. on T elecommunic ations, ET T , vol.10 (6), pp. 585-596, Nov . 1999. 9 A yfer ¨ Ozg ¨ ur recei ved B. Sc. degree s in electri cal enginee ring and physics from Middle E ast T echnical Univ ersity , Turk ey , in 2001 and M.Sc. degree in elect rical engineering from the same uni versit y in 2004. She is now a Ph.D. student at the Laboratory of In formation Theory , Swiss Federal Instit ute of T echnolo gy-Lausanne. Her researc h interests incl ude wireless communic ations and information theory . O l i vier L ´ ev ˆ eque was born in Switzerland i n 1971. H e recei ved the physic s diploma from E PFL in 1995 and complete d his Ph.D. in mathemati cs at EPFL in 2001. Si nce then, he has been with the Laboratory of Information Theory at E PFL. He spent the a cademic al year 2005-2006 at the Electrical Engineeri ng Department of Stanford U ni versity , where he was appo inted as lectu rer . His rese arch inte rests incl ude stochastic analy sis, random m atrice s, wireless communic ations and informa tion theory . 10
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment