Characterising Web Site Link Structure
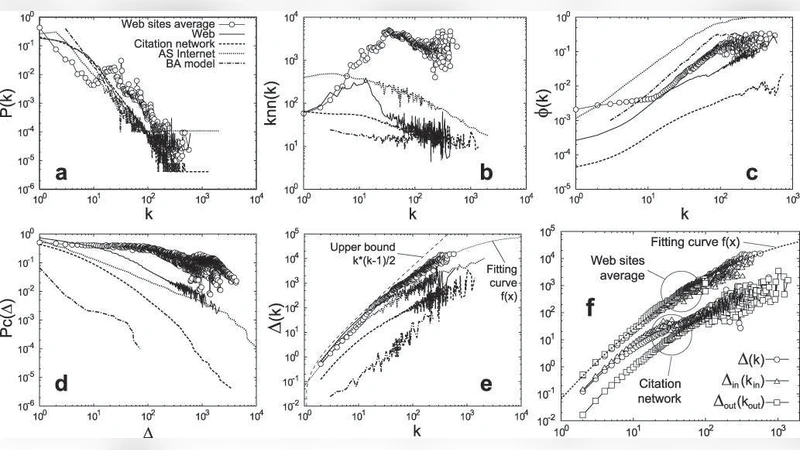
The topological structures of the Internet and the Web have received considerable attention. However, there has been little research on the topological properties of individual web sites. In this paper, we consider whether web sites (as opposed to the entire Web) exhibit structural similarities. To do so, we exhaustively crawled 18 web sites as diverse as governmental departments, commercial companies and university departments in different countries. These web sites consisted of as little as a few thousand pages to millions of pages. Statistical analysis of these 18 sites revealed that the internal link structure of the web sites are significantly different when measured with first and second-order topological properties, i.e. properties based on the connectivity of an individual or a pairs of nodes. However, examination of a third-order topological property that consider the connectivity between three nodes that form a triangle, revealed a strong correspondence across web sites, suggestive of an invariant. Comparison with the Web, the AS Internet, and a citation network, showed that this third-order property is not shared across other types of networks. Nor is the property exhibited in generative network models such as that of Barabasi and Albert.
💡 Research Summary
The paper addresses a gap in the literature concerning the topological properties of individual web sites, as opposed to the well‑studied structure of the global Web or the Internet. To investigate whether distinct sites share any structural regularities, the authors performed exhaustive crawls of 18 web sites that span a wide range of domains (government ministries, commercial enterprises, university departments) and sizes (from a few thousand pages to several million pages). Each site was represented as a directed graph where nodes correspond to pages and edges to hyperlinks.
The analysis proceeds in three stages, corresponding to first‑order (node degree), second‑order (pairwise connectivity), and third‑order (triadic) topological measures. First‑order results show substantial variation across sites: average out‑degree, degree distribution shape, and average shortest‑path length differ markedly, reflecting the diverse content management policies, navigation designs, and organizational structures of the sampled sites. Second‑order analysis, which examines the number of common neighbors between linked node pairs, also reveals site‑specific patterns; some sites exhibit dense overlapping neighborhoods indicative of heavy cross‑referencing, while others display sparser pairwise connectivity, suggesting a more hierarchical layout.
The most striking finding emerges from the third‑order analysis. The authors compute the clustering coefficient and the frequency of triangles (three nodes mutually linked) for each site. Despite the wide variation in size and domain, all 18 sites display remarkably similar clustering coefficients and triangle‑to‑edge ratios. This consistency suggests the existence of an invariant property of web‑site link structures that is independent of scale or content type. The authors term this phenomenon a “third‑order invariant.”
To assess the uniqueness of this invariant, the paper compares the web‑site data with three reference networks: the global Web (as captured by a large‑scale crawl), the autonomous‑system (AS) level Internet topology, and a citation network of scientific papers. In each case, the third‑order measures differ substantially from those observed in the individual sites. Moreover, synthetic networks generated by the classic Barabási‑Albert preferential‑attachment model, which reproduces the power‑law degree distribution of many real‑world networks, fail to exhibit the same clustering consistency. Hence, the invariant is not a generic consequence of scale‑free growth or random attachment; it appears to be a specific hallmark of how human‑curated web sites are constructed.
The authors discuss several implications. First, the invariant could serve as a diagnostic tool: deviations from the expected clustering level might indicate poor site architecture, navigation problems, or even malicious manipulation (e.g., link farms or phishing pages). Second, the finding opens avenues for automated quality assessment and anomaly detection in large‑scale web‑crawling pipelines. Third, understanding the design principles that give rise to this invariant could inform best‑practice guidelines for web developers seeking to balance navigability, redundancy, and maintainability.
The paper concludes by outlining future work: expanding the sample size to include hundreds of sites, tracking temporal evolution to see whether the invariant persists through redesigns or content growth, and integrating the third‑order metric into machine‑learning models for site classification or security screening. Overall, the study provides compelling evidence that, while first‑ and second‑order topological characteristics of web sites are highly heterogeneous, a robust third‑order structural pattern exists across diverse sites, distinguishing them from other complex networks and from standard generative models.