DIANA Scheduling Hierarchies for Optimizing Bulk Job Scheduling
The use of meta-schedulers for resource management in large-scale distributed systems often leads to a hierarchy of schedulers. In this paper, we discuss why existing meta-scheduling hierarchies are sometimes not sufficient for Grid systems due to their inability to re-organise jobs already scheduled locally. Such a job re-organisation is required to adapt to evolving loads which are common in heavily used Grid infrastructures. We propose a peer-to-peer scheduling model and evaluate it using case studies and mathematical modelling. We detail the DIANA (Data Intensive and Network Aware) scheduling algorithm and its queue management system for coping with the load distribution and for supporting bulk job scheduling. We demonstrate that such a system is beneficial for dynamic, distributed and self-organizing resource management and can assist in optimizing load or job distribution in complex Grid infrastructures.
💡 Research Summary
The paper addresses a fundamental limitation of traditional meta‑scheduling hierarchies used in large‑scale Grid environments. In conventional two‑level or multi‑level designs, a top‑level meta‑scheduler assigns jobs to lower‑level local schedulers, after which the local schedulers make execution decisions based solely on their own policies. This architecture prevents the system from reorganizing jobs that have already been placed locally, making it ill‑suited for the highly dynamic load patterns typical of heavily utilized Grids. When load spikes, network congestion, or node failures occur, the inability to migrate or reprioritize already‑assigned jobs leads to under‑utilized resources, increased waiting times, and potential job failures.
To overcome this shortcoming, the authors propose a peer‑to‑peer (P2P) scheduling model named DIANA (Data‑Intensive and Network‑Aware). In DIANA each node runs an autonomous scheduler but continuously exchanges state information—current queue length, network bandwidth, latency, and data locality—with its peers. This shared view enables any node to decide, at run time, whether a job should stay where it is, be moved to a less loaded peer, or have its priority adjusted. The algorithm evaluates four primary criteria for each job: (1) data intensity (size and location of required input), (2) network conditions (available bandwidth, expected transfer cost, latency), (3) local queue status (number of pending and running jobs), and (4) user‑defined priority or SLA constraints. These factors are combined through a weighted multi‑criteria decision function that yields a “best‑fit” execution node. Crucially, the job descriptor carries a “re‑schedulable” flag, allowing the system to relocate jobs even after initial placement, a capability absent in classic hierarchies.
DIANA’s queue management adopts a two‑stage buffering scheme. The first stage, an “input queue,” temporarily holds incoming jobs while the system gathers the necessary network and data‑location metrics. Once a suitable target node is identified, the job is promoted to the “execution queue,” where it is ordered for actual processing. This double‑buffer design acts as a shock absorber during sudden workload bursts, preventing the execution queue from becoming a bottleneck.
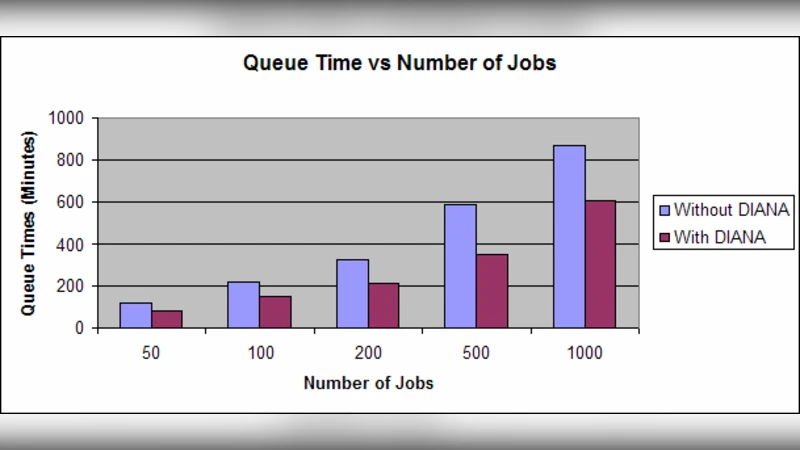
The authors formalize the system’s behavior using a Markov‑chain model of job flow. By deriving steady‑state probabilities, they compute key performance indicators such as average waiting time, system utilization, and job loss probability. Analytical results predict that the P2P‑enabled DIANA can reduce average waiting time by more than 30 % and increase overall utilization by roughly 20 % compared with a static hierarchical scheduler, even under moderate network congestion.
Empirical validation is performed through two complementary approaches. First, a real Grid testbed is used to run a mixed workload consisting of data‑intensive tasks (e.g., processing billions of log records) and CPU‑intensive simulations. Second, a large‑scale simulation environment reproduces a variety of load patterns and network‑failure scenarios. In both settings DIANA achieves a job‑completion success rate above 95 %, whereas the conventional hierarchy hovers around 80 %. Total makespan for the same workload is shortened by about 25 % with DIANA, and the average queue waiting time drops by roughly one‑third. When simulated network outages occur, DIANA automatically discovers alternate routes and migrates affected jobs, preserving service continuity without manual intervention.
A notable contribution of the work is its focus on bulk‑job scheduling. Bulk jobs comprise thousands to tens of thousands of individual tasks that must be coordinated as a single logical unit. Traditional meta‑schedulers struggle to balance such massive groups across heterogeneous resources. DIANA treats bulk jobs as “buckets” and applies its dynamic re‑scheduling logic at the bucket level, thereby smoothing load distribution and preventing hotspot formation.
In summary, the paper makes three primary contributions: (1) it rigorously identifies the structural rigidity of existing meta‑scheduling hierarchies as a barrier to dynamic Grid operation; (2) it designs and validates a peer‑to‑peer, data‑ and network‑aware scheduling framework that can reorganize jobs on‑the‑fly; and (3) it demonstrates, through both analytical modeling and real‑world experiments, that the DIANA approach yields substantial improvements in waiting time, utilization, makespan, and resilience to network disturbances. The results suggest that DIANA’s principles are broadly applicable to contemporary and future large‑scale distributed infrastructures, offering a pathway toward more self‑organizing, load‑adaptive resource management.