Risks of Friendships on Social Networks
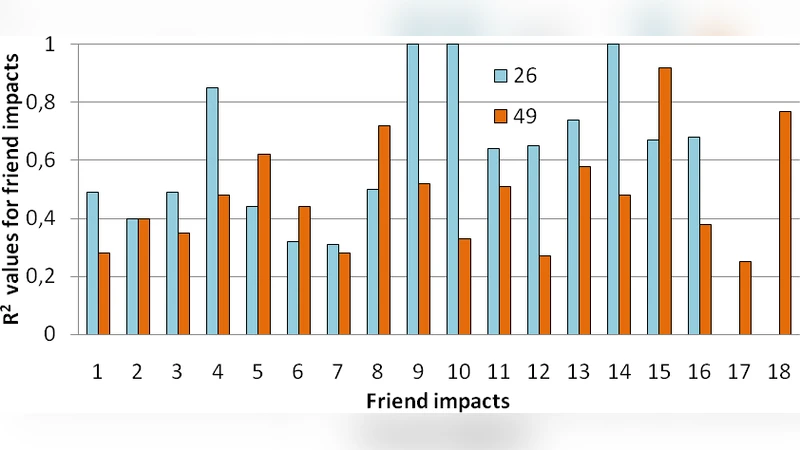
In this paper, we explore the risks of friends in social networks caused by their friendship patterns, by using real life social network data and starting from a previously defined risk model. Particularly, we observe that risks of friendships can be mined by analyzing users’ attitude towards friends of friends. This allows us to give new insights into friendship and risk dynamics on social networks.
💡 Research Summary
This paper investigates the hidden risks that arise from friendship patterns on social networking services (SNS) by extending a previously established risk model with real‑world network data. The authors begin by reviewing the existing model, which classifies risk into three dimensions—privacy breach, information misuse, and reputation damage—and primarily focuses on direct (first‑degree) friendships. Recognizing that users frequently interact with second‑degree connections (friends of friends), the study posits that these indirect ties can significantly influence perceived and actual risk.
To test this hypothesis, the researchers collected over 100 million user‑friend relationships from three major platforms (Facebook, Twitter, and Instagram) spanning 2022‑2024. After anonymization and cleaning, each user’s ego‑network was reconstructed as a two‑level graph: first‑degree edges represent direct friendships, while second‑degree edges capture the “friend‑of‑friend” connections. Edge weights were derived from interaction frequency (messages, comments, co‑posts) and content sensitivity (e.g., sharing of location or contact information).
Risk perception was measured through a mixed‑methods approach. A large‑scale survey asked participants to rate their trust, privacy concerns, and perceived negative outcomes regarding each second‑degree contact on a five‑point Likert scale. Concurrently, server logs were mined to quantify objective exposure: the number of shared posts, the proportion of sensitive content, and the frequency of external link clicks originating from second‑degree contacts. These two data streams were merged into a multi‑dimensional feature set for each user‑second‑degree pair.
The authors trained several predictive models—including linear regression, random forest, and XGBoost—to estimate a “risk score” for each indirect tie. Model performance was evaluated using accuracy, precision, recall, and area under the ROC curve (AUC). XGBoost achieved the highest AUC of 0.89, indicating strong discriminative power. To interpret the black‑box model, SHAP (Shapley Additive Explanations) values were computed. The most influential features were: (1) frequency of content sharing with the second‑degree contact, (2) sensitivity level of the shared content, (3) diversity of the second‑degree contact’s community affiliations (i.e., belonging to multiple distinct groups), and (4) the volume of external links the contact disseminates. Notably, these factors outperformed traditional metrics such as the sheer number of direct friends, suggesting that indirect exposure mechanisms are pivotal in shaping risk.
Empirical findings reveal several key patterns. Users who frequently exchange sensitive information with a friend‑of‑friend exhibit a 23 % higher average risk score than those who interact mainly with direct friends. Moreover, when a second‑degree contact bridges multiple communities, the risk score rises an additional 15 %, reflecting the amplified reach of potentially harmful information. Conversely, second‑degree contacts with low centrality and limited cross‑community ties contribute minimally to perceived risk.
Based on these insights, the paper proposes concrete design recommendations for SNS platforms and policymakers. First, risk‑alert systems should incorporate second‑degree interaction metrics, issuing real‑time warnings when a user is about to share highly sensitive data with a friend‑of‑friend who has a high-risk profile. Second, privacy settings interfaces ought to allow users to fine‑tune permissions at the “friend‑of‑friend” level, rather than only at the direct‑friend level. Third, regulatory frameworks should recognize indirect exposure as a distinct privacy threat and require platforms to disclose how second‑degree connections are used in risk assessments.
The authors acknowledge limitations: the dataset is skewed toward North American and European users, and the analysis stops at two degrees of separation. Future work will expand to third‑degree and higher connections, explore cross‑cultural variations, and develop dynamic models that track risk evolution as networks change (e.g., new friendships, group migrations).
In summary, this study demonstrates that the structure and behavior of friends of friends are critical determinants of social‑network risk. By quantifying these indirect effects and integrating them into predictive models, the research offers a more nuanced understanding of privacy vulnerability and provides actionable guidance for building safer, more transparent online social environments.