Effects of component-subscription network topology on large-scale data centre performance scaling
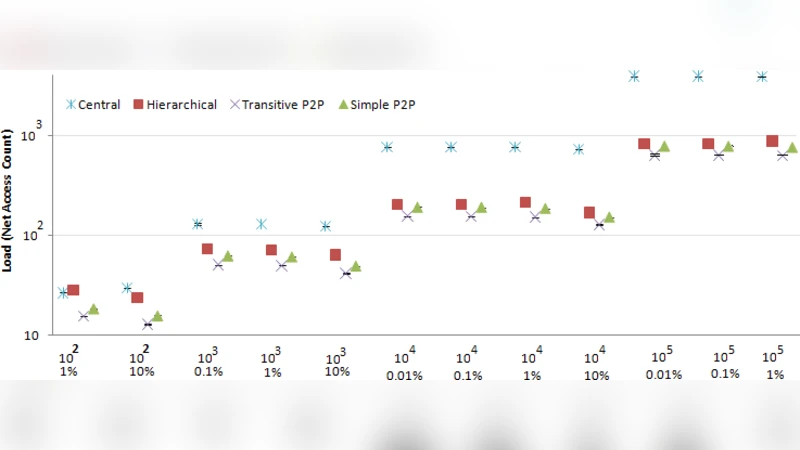
Modern large-scale date centres, such as those used for cloud computing service provision, are becoming ever-larger as the operators of those data centres seek to maximise the benefits from economies of scale. With these increases in size comes a growth in system complexity, which is usually problematic. There is an increased desire for automated “self-star” configuration, management, and failure-recovery of the data-centre infrastructure, but many traditional techniques scale much worse than linearly as the number of nodes to be managed increases. As the number of nodes in a median-sized data-centre looks set to increase by two or three orders of magnitude in coming decades, it seems reasonable to attempt to explore and understand the scaling properties of the data-centre middleware before such data-centres are constructed. In [1] we presented SPECI, a simulator that predicts aspects of large-scale data-centre middleware performance, concentrating on the influence of status changes such as policy updates or routine node failures. […]. In [1] we used a first-approximation assumption that such subscriptions are distributed wholly at random across the data centre. In this present paper, we explore the effects of introducing more realistic constraints to the structure of the internal network of subscriptions. We contrast the original results […] exploring the effects of making the data-centre’s subscription network have a regular lattice-like structure, and also semi-random network structures resulting from parameterised network generation functions that create “small-world” and “scale-free” networks. We show that for distributed middleware topologies, the structure and distribution of tasks carried out in the data centre can significantly influence the performance overhead imposed by the middleware.
💡 Research Summary
The paper investigates how the topology of the internal subscription network influences the scalability and performance of middleware in very large data‑centers. As cloud providers build ever‑larger facilities, traditional management techniques scale worse than linearly, making it essential to understand middleware behavior before such infrastructures are deployed. The authors previously introduced SPECI, a discrete‑event simulator that models the propagation of status updates (policy changes, node failures, etc.) across a data‑center where each node subscribes to a set of other nodes. In the original work, subscriptions were assumed to be uniformly random, an unrealistic simplification.
In this study the authors replace the random assumption with three more realistic network generation models. First, a regular two‑dimensional lattice where each node only subscribes to its immediate geometric neighbours, representing strict locality constraints. Second, a Watts‑Strogatz “small‑world” network, generated by rewiring a regular ring with a configurable probability to create high clustering together with short average path lengths. Third, a Barabási‑Albert “scale‑free” network, where a preferential‑attachment process yields a power‑law degree distribution and a few hub nodes that dominate the subscription graph.
For each topology the same workload is applied: a mix of periodic policy updates and stochastic node failures, with recovery mechanisms that attempt to re‑establish correct state information. The authors measure three key metrics: (1) average latency of update propagation, (2) total number of messages exchanged (network traffic), and (3) time to recover from a failure (time until all surviving nodes have a consistent view).
Results show distinct trade‑offs. The lattice topology produces the longest propagation delays because information must travel many hops, but traffic is evenly spread, avoiding hotspots. The small‑world topology dramatically reduces average latency (by roughly 30 % compared with the lattice) while preserving high clustering; however, localized bursts of traffic can appear in tightly‑connected clusters. The scale‑free topology yields the fastest propagation when hub nodes are healthy, but a single hub failure causes a steep increase in recovery time and concentrates traffic on the remaining hubs, raising the risk of network saturation.
These findings imply that middleware performance cannot be accurately predicted using a random‑subscription model; the underlying graph structure has a decisive impact. Designers of future hyperscale data‑centers can exploit this insight by deliberately shaping subscription relationships: limiting the fan‑out of critical services, adding redundancy for hub nodes, or employing dynamic re‑wiring to maintain a small‑world balance between locality and global reachability. The paper concludes by recommending that real‑world data‑center logs be mined to infer actual subscription graphs and that adaptive topology‑management algorithms be developed to keep middleware overhead low while preserving resilience as the system scales.
Comments & Academic Discussion
Loading comments...
Leave a Comment