Cloud Computing and Grid Computing 360-Degree Compared
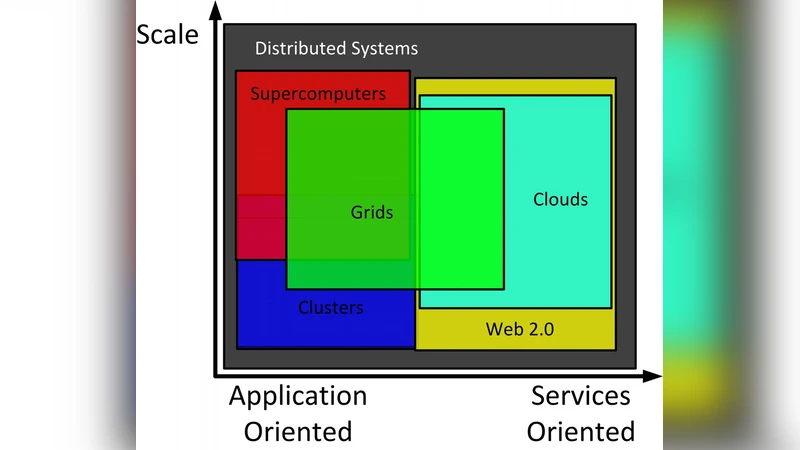
Cloud Computing has become another buzzword after Web 2.0. However, there are dozens of different definitions for Cloud Computing and there seems to be no consensus on what a Cloud is. On the other hand, Cloud Computing is not a completely new concept; it has intricate connection to the relatively new but thirteen-year established Grid Computing paradigm, and other relevant technologies such as utility computing, cluster computing, and distributed systems in general. This paper strives to compare and contrast Cloud Computing with Grid Computing from various angles and give insights into the essential characteristics of both.
💡 Research Summary
The paper sets out to provide a comprehensive, side‑by‑side comparison of Cloud Computing and Grid Computing, two paradigms that both aim to make large‑scale computing resources available on demand but differ markedly in architecture, service models, management practices, cost structures, security mechanisms, performance characteristics, and typical application domains. It begins with a brief historical overview: cloud computing emerged in the early 2000s as a commercial evolution of virtualization and Web 2.0, promoting the idea of delivering IT infrastructure, platforms, and software as services (IaaS, PaaS, SaaS). Grid computing, by contrast, originated in the mid‑1990s within the scientific community, focusing on the coordinated sharing of heterogeneous, geographically dispersed resources through virtual organizations (VOs).
The authors then introduce an eight‑axis “360‑degree” framework for analysis. The first axis, definition, highlights that clouds are service‑oriented, multi‑tenant environments defined by Service Level Agreements (SLAs), whereas grids are resource‑oriented, policy‑driven collaborations that emphasize shared access to high‑performance clusters and supercomputers. The second axis, architecture, contrasts the data‑center‑centric, heavily virtualized infrastructure of clouds—relying on hypervisors, containers, and orchestration platforms such as OpenStack or Kubernetes—with the distributed, often bare‑metal clusters of grids that are managed by batch schedulers (PBS, SLURM) and specialized data‑movement protocols (GridFTP, RLS).
In the service‑model axis, clouds provide on‑demand, elastic provisioning of compute, storage, and networking, while grids typically expose a batch‑oriented job submission interface and require users to pre‑allocate quotas. Operational management is another point of divergence: clouds automate billing, monitoring, and auto‑scaling, whereas grid users are responsible for crafting job scripts, handling workflow dependencies, and negotiating resource allocations through VO policies.
Cost models form the fifth axis. Cloud economics are dominated by a pay‑as‑you‑go OPEX model, allowing organizations to avoid upfront capital expenditures. Grid economics are usually based on shared, often government‑funded, infrastructure where participating institutions contribute to capital costs and users consume resources within allocated quotas at little or no direct charge. Security and reliability, the sixth axis, show clouds employing multi‑tenant isolation, federated identity (OAuth, SAML), and SLA‑backed uptime guarantees. Grids rely on PKI‑based certificates, VO trust relationships, and physical redundancy, but their reliability is more tightly coupled to the underlying network and hardware resilience.
Performance and scalability, the seventh axis, reveal that clouds excel at horizontal scaling and rapid elasticity, making them ideal for web services, big‑data analytics, and AI workloads that can tolerate variable performance. Grids, on the other hand, are optimized for massive parallelism, low‑latency interconnects (e.g., InfiniBand), and deterministic execution—attributes essential for scientific simulations, climate modeling, and particle‑physics calculations.
The final axis examines application domains and future trends. Cloud computing is now pervasive across commercial SaaS, mobile back‑ends, DevOps pipelines, and emerging edge‑computing scenarios. Grid computing remains the backbone of data‑intensive scientific research, though it is increasingly being integrated with cloud resources to form hybrid environments that combine the elasticity of clouds with the raw performance of grids. The authors anticipate that container‑native microservices, serverless execution, and AI‑driven resource orchestration will drive the next wave of cloud evolution, while grids will focus on workflow automation, advanced scheduling algorithms, and tighter coupling with public‑cloud APIs.
In conclusion, the paper argues that despite their distinct philosophies—service‑centric versus resource‑centric—cloud and grid computing are complementary. Organizations should evaluate workload characteristics, cost constraints, security requirements, and performance needs to decide whether to adopt a pure cloud, a pure grid, or a hybrid solution that leverages the strengths of both paradigms.
Comments & Academic Discussion
Loading comments...
Leave a Comment