A Bayesian Network Model for Interesting Itemsets
Mining itemsets that are the most interesting under a statistical model of the underlying data is a commonly used and well-studied technique for exploratory data analysis, with the most recent interestingness models exhibiting state of the art perfor…
Authors: Jaroslav Fowkes, Charles Sutton
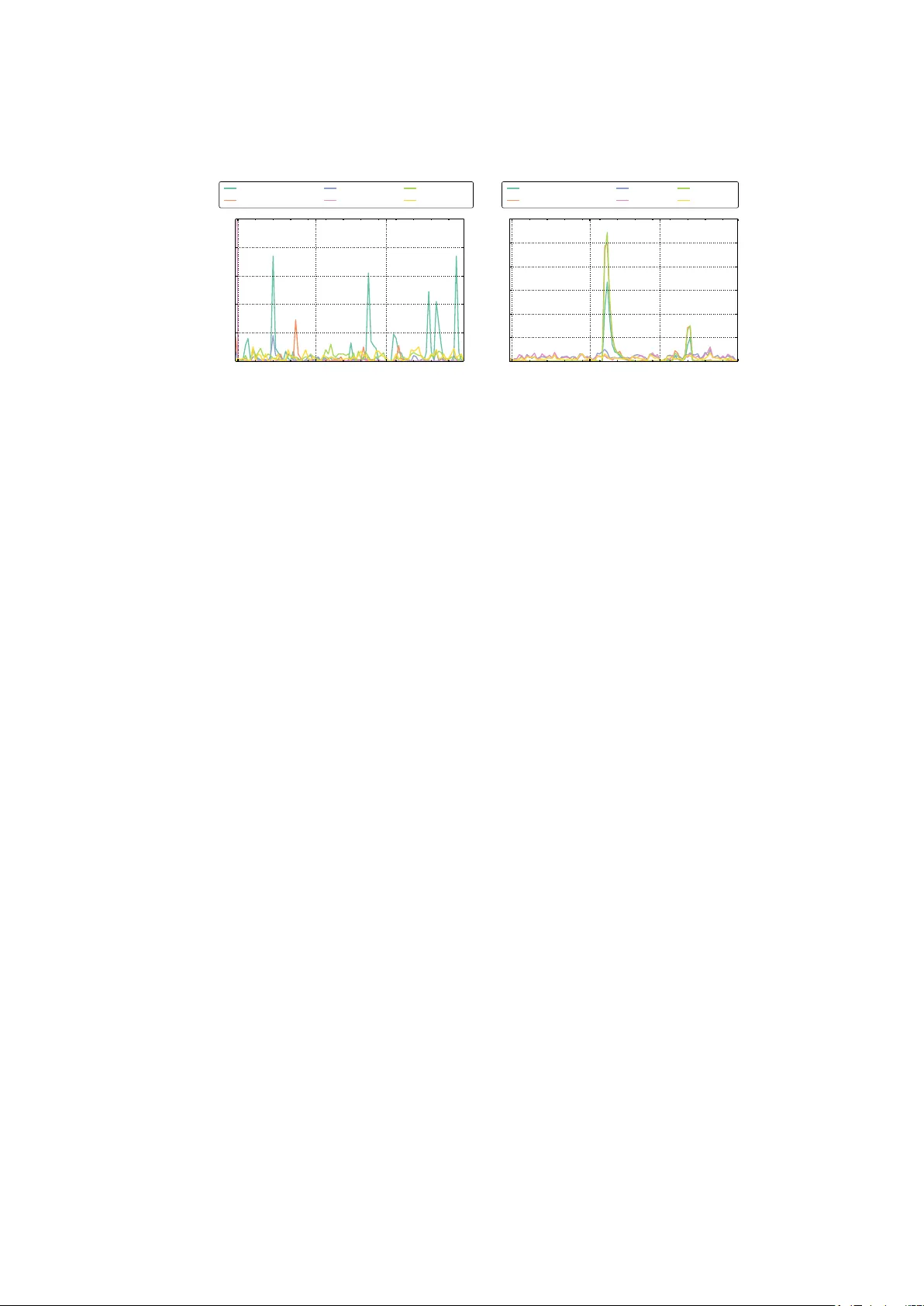
A Ba y esian Net w ork Mo del for In teresting Itemsets Jarosla v F o wkes ( ) and Charles Sutton Sc ho ol of Informatics, Universit y of Edinburgh, Edin burgh, EH8 9AB, UK {jfowkes,csutton}@inf.ed.ac.uk Abstract. Mining itemsets that are the most in teresting under a statis- tical mo del of the underlying data is a commonly used and well-studied tec hnique for exploratory data analysis, with the most recent interest- ingness mo dels exhibiting state of the art p erformance. Contin uing this highly promising line of w ork, we prop ose the first, to the b est of our kno wledge, generativ e model o v er itemsets, in the form of a Ba yesian net- w ork, and an asso ciated nov el measure of interestingness. Our mo del is able to efficiently infer interesting itemsets directly from the transaction database using structural EM, in which the E-step employs the greedy appro ximation to weigh ted set cov er. Our approach is theoretically sim- ple, straigh tforward to implemen t, trivially parallelizable and retrieves itemsets whose quality is comparable to, if not better than, existing state of the art algorithms as we demonstrate on several real-world datasets. 1 In tro duction Itemset mining is one of the most imp ortan t problems in data mining, with applications including mark et basket analysis, mining data streams and mining bugs in source co de [ 1 ]. Early w ork on itemset mining fo cused on algorithms that iden tify all itemsets which meet a given criterion for pattern quality , suc h as all fr e quent itemsets whose supp ort is ab ov e a user-sp ecified threshold. Although app ealing algorithmically , the list of frequent itemsets suffers from p attern ex- plosion , i.e., is typically long, highly redundant and difficult to understand [ 1 ]. In an attempt to address this problem, more recent work fo cuses on mining in- ter esting itemsets , smaller sets of high-quality , non-redundan t itemsets that can b e examined by a data analyst to get an ov erview of the data. Several different approac hes ha ve been prop osed for this problem. Some of the most successful recen t approaches, suc h as MTV [ 19 ], KRIMP [ 28 ] and SLIM [ 26 ] are based on the minimum description length (MDL) principle, meaning that they define an enco ding scheme for compressing the database based on a set of itemsets, and searc h for the itemsets that b est compress the data. These metho ds hav e b een sho wn to lead to m uch less redundant pattern sets than frequen t itemset mining. In this paper, w e in tro duce an alternativ e, but closely related, viewpoint on in teresting itemset mining metho ds, by starting with a probabilistic model of the data rather than a compression sc heme. W e define a gener ative mo del of the data, that is, a probability distribution ov er the database, in the form of a Ba yesian net work mo del, based on the in teresting itemsets. T o infer the in teresting items, we use a probabilistic learning approach that directly infers the itemsets that b est explain the underlying data. Our metho d, which we call the Inter esting Itemset Miner (IIM) 1 , is to the b est of our knowledge, the first generativ e mo del for interesting itemset mining. In terestingly , our viewpoint has a close connection to MDL-based approaches for mining itemsets that b est compress the data (Section 3.9 ). Ev ery probability distribution implicitly defines an optimal compression algorithm, and conv ersely ev ery compression sc heme implicitly corresponds to a probabilistic model. Ex- plicitly taking the probabilistic mo delling p erspective rather than an MDL p er- sp ectiv e has t wo adv an tages. First, fo cusing on the probability distribution re- liev es us from sp ecifying the many bo ok-k eeping details required by a lossless co de. Second, the probabilistic mo delling p ersp ectiv e allows us to exploit p ow- erful methods for probabilistic inference, learning, and optimization, suc h as submo dular optimization and structural exp ectation maximization (EM). The collection of interesting itemsets under I IM can b e inferred efficiently using a structural EM framework [ 9 ]. One can think of our mo del as a proba- bilistic relative of some of the early work on itemset mining that formulates the task of finding in teresting patterns as a cov ering problem [ 11 , 28 ], except that in our w ork, the set cov er problem is used to identify itemsets that cov er a trans- action with maximum pr ob ability . The set co ver problem arises naturally within the E step of the EM algorithm. On real-world datasets we find that the inter- esting itemsets seem to capture meaningful domain structure, e.g. represen ting phrases such as anomaly dete ction in a corpus of researc h papers, or regions such as western US states in geographical data. Notably , we find that I IM returns a m uch more div erse list of itemsets than current state of the art algorithms (T a- ble 2 ), which seem to b e of similar quality . Ov erall, our results suggest that the in teresting itemsets found by IIM are suitable for manual examination during exploratory data analysis. 2 Related W ork Itemset mining w as first introduced by Agraw al and Srikant [ 2 ], along with the Apriori algorithm, in the con text of market bask et analysis which led to a n um b er of other algorithms for frequent itemset mining including Eclat and FPGrowth. F requen t itemset mining suffers from p attern explosion : a h uge num ber of highly redundan t frequent itemsets are retrieved if the given minim um supp ort thresh- old is to o low. One wa y to address this is to mine c omp act r epr esentations of frequen t itemsets suc h as maximal frequent, closed frequent and non-deriv able itemsets with efficient algorithms suc h as CHARM [ 31 ]. How ever, even mining suc h compact representations do es not fully resolve the problem of pattern ex- plosion (see Chapter 2 of [ 1 ] for a survey of frequent itemset mining algorithms). An orthogonal research direction has b een to mine tiles instead of itemsets, i.e., subsets of ro ws and c olumns of the database view ed as binary transaction 1 https://github.com/mast- group/itemset- mining 2 b y item matrices. The analogous approach is then to mine lar ge tiles , i.e., sub- matrices with only 1s whose area is greater than a giv en minim um area threshold. The Tiling algorithm [ 11 ] is an example of an efficient implemen tation that uses the greedy algorithm for set cov er. Note that there is a corresp ondence b etw een tiles and itemsets: every large tile is a closed frequent itemset and th us algorithms for large tile mining also suffer from pattern explosion to some extent. In an attempt to tackle this problem, mo dern approaches to itemset mining ha ve used the minimum description length (MDL) principle to find the set of itemsets that best summarize the database. MTV [ 20 ] uses MDL coupled with a maximum entr opy (MaxEnt) mo del to mine the most informativ e itemsets. MTV mines the set of top itemsets with the highest likelihoo d under the mo del via an efficient con vex b ound that allows man y candidate itemsets to b e pruned and employs a metho d for more efficiently inferring the mo del itself. Due to the partitioning constraints necessary to keep computation feasible, MTV typically only finds in the order of tens of itemsets, whereas I IM has no such restriction. KRIMP [ 28 ] employs MDL to find the subset of frequen t itemsets that yields the best lossless compression of the database. While in principle this could b e form ulated as a set cov er problem, the authors employ a fast heuristic that do es not allo w the itemsets to o verlap (unlike IIM) even though one might exp ect that doing so could lead to b etter compression. In contrast, I IM employs a set co ver framew ork to identify a set of itemsets that cov er a transaction with highest probabilit y . The main drawbac k of KRIMP is the need to mine a set of frequent itemsets in the first instance, which is addressed by the SLIM algorithm [ 26 ], an extension of KRIMP that mines itemsets directly from the database, iteratively joining co-o ccurring itemsets such that compression is maximised. The MaxEnt mo del can also b e extended to tiles, here kno wn as the R asch mo del, and, unlike in the itemset case, inference takes p olynomial time. Kon- tonasios and De Bie [ 16 ] use the Rasc h mo del to find the most surprising set of noisy tiles (i.e., sub-matrices with predominan tly 1s but some 0s) b y com- puting the likelihoo d of tile entries cov ered b y the set. The inference problem then takes the form of weigh ted budgeted maxim um set cov er, which can again b e efficien tly solved using the greedy algorithm. The problem of Bo olean matrix factorization can b e viewed as finding a set of frequent noisy tiles which form a lo w-rank appro ximation to the data [ 22 ]. The MINI algorithm [ 10 ] finds the itemsets with the highest surprisal under statistical indep endence models of items and transactions from a precomputed set of closed frequent itemsets. OPUS Miner [ 29 ] is a branch and b ound algorithm for mining the top self-sufficient itemsets, i.e., those whose frequency cannot b e explained solely by the frequency of either their subsets or of their sup ersets. In contrast to previous w ork, I IM maintains a generativ e mo del, in the form of a Bay esian netw ork, dir e ctly o ver itemsets as opp osed to indirectly o ver items. Existing Ba yesian netw ork mo dels for itemset mining [ 14 , 15 ] hav e had limited success as mo delling dep endencies b et w een the items makes inference for larger datasets prohibitiv e. In I IM inference takes the form of a weigh ted set cov er problem, whic h can be solv ed efficiently using the greedy algorithm (Section 3.3 ). 3 The structure of I IM’s statistical mo del is similar to existing models in the literature suc h as Rephil ([ 24 ], §26.5.4) for topic mo delling and QMR-DT [ 25 ] for medical diagnosis. Rephil is a multi-lev el graphical mo del used in Go ogle’s A dSense system. QMR-DT is a bi-partite graphical mo del used for inferring significan t diseases based on medical findings. How ev er, the main contribution of our pap er is to show that a binary latent v ariable model can b e useful for selecting itemsets for exploratory data analysis. 3 In teresting Itemset Mining In this section we will formulate the problem of identifying a set of interesting itemsets that are useful for explaining a database of transactions. First we will define some preliminary concepts and notation. An item i is an element of the univ erse U = { 1 , 2 , . . . , n } that indexes database attributes. A tr ansaction X is a subset of the univ erse U and an itemset S is simply a set of items i . The set of interesting itemsets I w e wish to determine is therefore a subset of the p o wer set (set of all p ossible subsets) of the universe. F urther, we say that an itemset S is supp orte d by a transaction X if S ⊆ X . 3.1 Problem F orm ulation Our aim in this w ork is to infer a set of interesting itemsets I from a database of transactions. By inter esting , w e mean a set of itemsets that will b est help a human analyst to understand the imp ortan t properties of the database, that is, interesting itemsets should reflect the imp ortan t probabilistic dep endencies among items, while b eing sufficiently concise and non-redundant that they can b e examined man ually . These criteria are inherently qualitativ e, reflecting the fact that the goal of data mining is to build human insight and understanding. In this work, we formalize interestingness as those itemsets that best explain the transaction database under a statistic al mo del of itemsets. Specifically we will use a gener ative mo del, i.e., a mo del that starts with a set of in teresting itemsets I and from this set generates the transaction database. Our goal is then to infer the most likely generating set I under our chosen generativ e mo del. W e wan t the mo del to be as simple as p ossible y et p o werful enough to capture correlations b et w een transaction items. A simple suc h mo del is to iteratively sample itemsets S from I and let their union form a transaction X . Sampling S from I uniformly w ould b e uninformative, but if we asso ciate each interesting itemset S ∈ I with a probability π S , we can sample the indicator v ariable z S ∼ Bernoulli ( π S ) and include S in X if z S = 1 . W e formally define this generative mo del next. 3.2 Ba yesian Netw ork Model W e propose a simple directed graphical mo del for generating a database of trans- actions X (1) , . . . , X ( m ) from a set I of interesting itemsets. The parameters of our mo del are Bernoulli probabilities π S for each in teresting itemset S ∈ I . The generativ e story for our mo del is, indep enden tly for each transaction X : 4 1. F or eac h itemset S ∈ I , decide independently whether to include S in the transaction, i.e., sample z S ∼ Bernoulli ( π S ) . 2. Set the transaction to b e the set of items in all the itemsets selected ab o v e: X = [ S | z S =1 S. Note that the mo del allows individual items to b e generated multiple times from differen t itemsets, e.g. e ggs could b e generated b oth as part of a breakfast itemset { b ac on, e ggs } and as as part of a cake itemset { flour, sugar, e ggs }. No w given a set of itemsets I , let z , π denote the vectors of z S , π S for all S ∈ I . Assuming z , π are fully determined, it is evident from the generativ e mo del that the probability of generating a transaction X is p ( X, z | π ) = ( Q S ∈I π z S S (1 − π S ) 1 − z S if X = S z S =1 S , 0 otherwise . (1) 3.3 Inference Assuming the parameters π in the model are kno wn, w e can infer z for a sp ecific transaction X b y maximizing the p osterior distribution p ( z | X , π ) ov er z : max z Y S ∈I π z S S (1 − π S ) 1 − z S s.t. X = [ S | z S =1 S. (2) T aking logs and rewriting ( 2 ) in a more standard form we obtain min z X S ∈I z S ( − ln( π S )) + (1 − z S ) ( − ln(1 − π S )) s.t. X S | i ∈ S z S ≥ 1 ∀ i ∈ X , z S ∈ { 0 , 1 } ∀ S ∈ I (3) whic h is (up to a p enalty term) the weigh ted set-cov er problem (see e.g. [ 17 ], §16.1) with weigh ts w S ∈ R + giv en b y w S : = − ln( π S ) . This is an NP-hard problem in general and so impractical to solve directly in practice. It is imp ortan t to note that the weigh ted set cov er problem is a sp ecial case of minimizing a linear function sub ject to a submodular constrain t, 2 whic h we form ulate as follows (cf. [ 30 ]). Given the set of in teresting itemsets T : = { S ∈ I | S ⊆ X } that supp ort the transaction, a real-v alued w eigh t w S for each itemset S ∈ T and a non- decreasing submo dular function f : 2 T → R , the aim is to find a cov ering C ⊂ T of minim um total weigh t, i.e., such that f ( C ) = f ( T ) and P S ∈C w S is minimized. 2 Note that the p osterior p ( z | X ) would not b e submodular if w e were to use a noisy-OR mo del for the conditional probabilities. 5 Algorithm 1 Hard-EM Input: Set of itemsets I and initial probability estimates π (0) k ← 0 do k ← k + 1 E-step: ∀ X ( j ) solv e ( 3 ) to get z ( j ) S ∀ S ∈ T j M-step: π ( k ) S ← 1 m P m j =1 z ( j ) S ∀ S ∈ I while k π ( k − 1) − π ( k ) k > ε Remo ve from I itemsets S with π S = 0 return I , π ( k ) F or w eighted set co ver w e simply define f ( C ) to b e the n umber of items in C , i.e., f ( C ) : = |∪ S ∈C S | . Note that f ( T ) = | X | by construction. W e can then approximately solve the weigh ted set co ver problem ( 3 ) using the greedy approximation algorithm for submo dular functions. The greedy algorithm builds a co vering C by repeatedly c ho osing an itemset S that minimizes the w eight w S divided by the num b er of items in S not yet co vered b y the cov ering. In order to minimize CPU time sp en t solving the w eigh ted set co ver problem, w e cac he the itemsets and cov erings for each transaction as needed. It has been sho wn [ 4 ] that the greedy algorithm ac hieves a ln | X | + 1 ap- pro ximation ratio to the w eighted set cov er problem and moreo ver the following inappro ximability theorem shows that this ratio is essentially the b est p ossible. Theorem 1 (F eige [ 7 ]). Ther e is no (1 − o (1)) ln | X | -appr oximation algorithm to the weighte d set c over pr oblem unless NP ⊆ DTIME ( | X | O (log log | X | ) ) , i.e., un- less NP has slightly sup erp olynomial time algorithms. The run time complexit y of the greedy algorithm is O ( | X ||T | ) , how ev er b y main- taining a priorit y queue this can b e impro ved to O ( | X | log |T | ) (see e.g. [ 5 ]). Note that there is also an O ( | X ||T | ) -run time primal-dual approximation algo- rithm [ 3 ], how ev er this has an approximation order of f = max i |{ S | i ∈ S }| , i.e., the frequency of the most frequen t elemen t, whic h w ould b e worse in our case. 3.4 Learning Giv en a set of itemsets I , consider no w the case where b oth v ariables z , π in the mo del are unknown. In this case we can use the hard EM algorithm [ 6 ] for parameter estimation with latent v ariables. The hard EM algorithm in our case is merely a simple lay er on top of the inference algorithm ( 3 ). Supp ose there are m transactions X (1) , . . . , X ( m ) with supp orting sets of itemsets T (1) , . . . , T ( m ) , then the hard EM algorithm is given in Algorithm 1 . T o initialize π , a natural c hoice is simply the supp ort (i.e., relative frequency) of each itemset in I . 3.5 Inferring new itemsets W e infer new itemsets using structural EM [ 9 ], i.e., w e add a candidate itemset S 0 to I if doing so improv es the optimal v alue p of the problem ( 3 ) av eraged across 6 Algorithm 2 Structural-EM (one iteration) Input: Itemsets I , probabilities π , optima p ( j ) of ( 3 ) ∀ X ( j ) Set profit p ← 1 m P m j =1 p ( j ) do Generate candidate S 0 using Candida te-Gen I ← I ∪ { S 0 } , π S 0 ← 1 E-step: ∀ X ( j ) solv e ( 3 ) to get z ( j ) S ∀ S ∈ T j M-step: π 0 S ← 1 m P m j =1 z ( j ) S ∀ S ∈ I ∀ X ( j ) , solve ( 3 ) using π 0 S , z ( j ) S ∀ S ∈ T j to get the optimum p ( j ) Set new profit p 0 ← 1 m P m j =1 p ( j ) I ← I \ { S 0 } while p 0 ≤ p {until one go od candidate found} I ← I ∪ { S 0 } return I , π 0 transactions. In terestingly , there is an implicit regularization effect here. Observ e from ( 3 ) that when a new candidate S 0 is added to the mo del, a corresp onding term ln(1 − π S 0 ) is added to the log-lik eliho o d of all transactions that S 0 do es not supp ort. F or large databases, this amoun ts to a significan t p enalt y on candidates. T o get an estimate of maximum b enefit to including candidate S 0 , we must carefully c hoose an initial v alue of π S 0 that is not too low, to a void getting stuc k in a lo cal optimum. T o infer a go od π S 0 , w e force the candidate S 0 to explain all transactions it supp orts b y initializing π S 0 = 1 and up date π S 0 with the probabilit y corresponding to its actual usage once we hav e inferred all the co verings. Giv en a set of itemsets I and corresponding probabilities π along with transactions X (1) , . . . , X ( m ) , each iteration of the structural EM algorithm is is giv en in Algorithm 2 ab o ve. In practice, w e cac he the set of candidates that hav e b een rejected b y the Structural-EM function to av oid reconsidering them. 3.6 Candidate generation The Structural-EM algorithm (Algorithm 2 ) requires a metho d to generate new candidate itemsets S 0 that are to be considered for inclusion in the set of in teresting itemsets I . One p ossibility would b e to use the Apriori algorithm to recursiv ely suggest larger itemsets starting from singletons, how ever preliminary exp erimen ts found this w as not the most efficien t metho d. F or this reason we tak e a slightly different approach and recursively com bine the interesting item- sets in I with the highest supp ort first (Algorithm 3 ). In this wa y our candidate generation algorithm is more likely to prop ose viable candidate itemsets earlier and in practice we find that this heuristic works well. W e did try pruning p oten- tial itemset pairs to join using a χ 2 -test, ho wev er this substan tially slow ed down the algorithm and barely improv ed the mo del likelihoo d. In order to determine the supp orts of the itemsets to b e combined, we store the transaction database in a Memory-Efficient Itemset T ree ( MEI-Tree ) [ 8 ] 7 Algorithm 3 Candida te-Gen Input: Itemsets I , cached supports σ , queue length q if @ priority queue Q for I then Initialize σ -ordered priority queue Q Sort I b y decreasing itemset supp ort using σ for all distinct pairs S 1 , S 2 ∈ I , highest ranked first do Generate candidate S 0 = S 1 ∪ S 2 Cac he supp ort of S 0 in σ and add S 0 to Q if |Q| = q break end for end if Pull highest-ranked candidate S 0 from Q return S 0 Algorithm 4 I IM (Interesting Itemset Miner) Input: Database of transactions X (1) , . . . , X ( m ) Initialize I with singletons, π with their supp orts Build MEI-Tree from transaction database while not con verged do A dd itemsets to I , π using Structural-EM Optimize parameters for I , π using Hard-EM end while return I , π and query the tree for the support of a giv en itemset. A MEI-Tree stores itemsets in a tree structure according to their prefixes in a memory efficien t manner. T o minimize the memory usage of the MEI-Tree further, we first sort the items in order of decreasing supp ort (as in the FPGro wth algorithm) as this often results in a sparser tree [ 13 ]. Note that a MEI-Tree is essentially an FP-tree [ 13 ] with node-compression and without no de-links for nodes containing the same item. An itemset supp ort query on the MEI-Tree efficiently searches the tree for all occurrences of the given itemset and adds up their supports (see Figure 4 in [ 8 ] for the actual algorithm). With the wide a v ailabilit y of 100GB+ shared memory systems, it is reasonable to exp ect the MEI-Tree to fit into memory for all but the largest of datasets. The queue length parameter in the Candida te-Gen algorithm effectively imp oses a limit on the n umber of iterations the algorithm can sp end suggesting candidate itemsets. 3.7 Mining In teresting Itemsets Our complete interesting itemset mining (I IM) algorithm is giv en in Algorithm 4 . Note that the Hard-EM parameter optimization step need not b e p erformed at every iteration, in fact it is more efficient to suggest several candidate item- sets b efore optimizing the parameters. As all op erations on transactions in our 8 algorithm are trivially parallelizable, we p erform the E and M -steps in both the hard and structural EM algorithms in parallel. 3.8 In terestingness Measure No w that we hav e inferred the mo del v ariables z , π , w e are able to use them to rank the retriev ed itemsets in I . There are t wo natural rankings one can employ , and b oth hav e their strengths and weaknesses. The ob vious approach is to rank eac h itemset S ∈ I according to its probability under the model π S , ho wev er this has the disadv antage of strongly fa v ouring frequen t itemsets ov er rare ones, an issue we would lik e to av oid. Instead, w e prefer to rank the retriev ed itemsets ac- cording to their inter estingness under the model, that is the ratio of transactions they explain to transactions they supp ort. One can think of interestingness as a measure of how necessary the itemset is to the mo del: the higher the interesting- ness, the more supp orted transactions the itemset explains. Thus in terestingness pro vides a more balanced measure than probability , at the expense of missing some frequent itemsets that only explain some of the transactions they supp ort. W e define interestingness formally as follows. Definition 1. The interestingness of an itemset S ∈ I r etrieve d by IIM (A lgo- rithm 4 ) is define d as int ( S ) = P m j =1 z ( j ) S supp ( S ) and r anges fr om 0 (le ast inter esting) to 1 (most inter esting). An y ties in the ranking can b e broken using the itemset probability π S . 3.9 Corresp ondence to existing mo dels There is a close connection b etw een probabilistic mo dels and the MDL principle [ 18 ]. Given a probabilistic model p ( X | π , I ) of a single transaction, b y Shannon’s theorem the optimal code for the model will encode X using appro ximately − log 2 p ( X | π , I ) bits. So by finding a set of itemsets that maximizes the proba- bilit y of the data, w e are also finding itemsets that minimize description length. Con versely , any enco ding scheme implicitly defines a probabilistic mo del: given an enco ding scheme E that assigns each transaction X to a string of L ( X ) bits, w e can define p ( X | E ) ∝ 2 − L ( X ) , and then E is an optimal co de for p ( X | E ) . In terpreting previous MDL-based itemset mining metho ds in terms of their im- plicit probabilistic mo dels provides in teresting insigh ts in to these metho ds. MTV uses a MaxEnt distribution o ver itemsets S ∈ I , which for a transaction X can b e written (cf. [ 20 ]): p ( X ) = π 0 Y S ∈I π 1 X ( S ) S where the indicator function 1 X ( S ) = 1 if X supp orts S and 0 otherwise. Th us if an itemset is present in the MaxEnt mo del it must b e use d to explain a supp orted 9 transaction, contrast this with I IM ( 1 ) where there is a laten t v ariable z ( j ) S for eac h transaction X ( j ) that infers if an itemset is use d to explain the transaction. KRIMP by contrast, uses an itemset indep endence mo del, which for an item- set S ∈ I is giv en b y (cf. [ 28 ]): p ( S ) = m X j =1 z ( j ) S , X I ∈I m X k =1 z ( k ) I where the z ( j ) S , and therefore itemset co verings for X ( j ) , are determined using a heuristic appr oximation . That is, unlik e IIM, the itemset cov erings are not c hosen to maximise the probability under the statistical mo del. Instead, for each transaction X , frequent itemsets S ∈ I are chosen in order of de cr e asing size and supp ort and added to the co vering if they impro ve the compression, un til all elemen ts of X are co vered. A dditionally , itemsets in the cov ering are not allo wed to o verlap, in con trast to I IM whic h do es allo w ov erlap if it is deemed necessary . SLIM uses the same approac h as KRIMP but iteratively finds the candidate itemsets S directly from the dataset. It emplo ys a greedy heuristic to do this: starting with a set of singleton itemsets I , pairwise combinations of itemsets in I are considered as candidate itemsets S in order of highest estimated compression gain. IIM uses a v ery similar heuristic that iterativ ely extends itemsets b y the most frequent itemset in its candidate generation step (Section 3.6 ). Ho wev er, IIM is differen t from these metho ds in that they all con tain an explicit p enalty term for the description length of the itemset database, whic h corresp onds to a prior distribution p ( I ) o ver itemsets. W e did not find in practice that an explicit prior distribution w as necessary but it w ould b e possible to trivially incorp orate it. Also, if we view I IM as an MDL-type metho d, not only the presence of an itemset, but also its absence is explicitly enco ded (in the form of (1 − π S ) 1 − z ( j ) S in ( 1 )). As a result, there is an implicit p enalt y for adding to o man y patterns to the model and one do es not need to use a co de table which w ould serv e as an explicit p enalt y for greater mo del complexity . One can also think of IIM as a probabilistic tiling metho d: each interesting itemset S ∈ I can b e though t of as a binary submatrix of transactions for which z S = 1 b y items in S , where the c hoice of items and transactions in the tile are inferr e d dir e ctly from I IM’s statistical mo del. That is, I IM form ulates the inference problem ( 3 ) as a weighte d set c over for e ach tr ansaction where the w eights corresp ond to itemset pr ob abilities . This is in contrast to existing tiling metho ds: Geerts et al. [ 11 ] find k tiles cov ering the largest num b er of database en tries and is thus an instance of maximum c over age . K ontonasios and De Bie [ 16 ] extend this to inferring a cov ering of noisy tiles using budgete d maximum c over age , that is, finding a co v ering that maximizes the sum of the surprisal of each tile, under a MaxEnt mo del constrained by expected ro w and column margins, sub ject to the sum of the description lengths of each tile b eing smaller than a given budget. 10 0.0 0.2 0.4 0.6 0.8 1.0 Recall 0.0 0.2 0.4 0.6 0.8 1.0 Precision IIM MTV SLIM KRIMP CHARM Fig. 1. Precision against recall for each algorithm on our synthetic database, us- ing the top- k itemsets as a threshold. 3 10 3 10 4 10 5 10 6 10 7 No. T ransactions 10 1 10 2 10 3 10 4 10 5 Time (s) Fig. 2. I IM scaling as the num b er of transactions in our syn thetic database increases. 4 Numerical Exp eriments In this section w e p erform a comprehensiv e qualitative and quantitativ e ev alua- tion of IIM. On syn thetic datasets we sho w that I IM returns a list of itemsets that is largely non-redundan t, con tains few spurious correlations and scales linearly with the n umber of transactions. On a set of real-w orld datasets we show that I IM finds itemsets that are muc h less redundant than state of the art metho ds, while b eing of similar qualit y . Datasets W e use five real-w orld datasets in our n umerical ev aluation (T able 1 ). The plants dataset [ 27 ] is a list of plan t sp ecies and the U.S. or Canadian states where they occur. The mammals dataset [ 23 ] consists of presence records of Europ ean mammals in 50 × 50 km geographical areas. The retail dataset consists of anonymized market basket data from a Belgian retail store [ 12 ]. The ICDM dataset [ 16 ] is a list of ICDM paper abstracts where each item is a stemmed word, excluding stop-words. The Uganda dataset consists of F aceb o ok messages taken from a set of public Uganda-based pages with substan tial topical discussion ov er a p erio d of three mon ths. Eac h transaction in the dataset is an English language message and each item is a stemmed English w ord from the message. IIM R esults W e ran IIM on each dataset for 1 , 000 iterations with a prior- it y queue size of 100 , 000 candidates. The run time and n umber of non-singleton itemsets returned is given in T able 1 (right). W e also inv estigated the scaling of I IM as the num b er of transactions in the database increases, using the mo del trained on the plan ts dataset from Section 4.1 to generate synthetic transaction databases of v arious sizes. W e then ran IIM for 100 iterations on these databases and one can see in Figure 2 that the scaling is linear as exp ected. Our prototype implemen tation can pro cess one million transactions in 30 seconds on 64 cores eac h iteration, so there is reason to hop e that a more highly tuned implemen- 3 Eac h curve is the 11-p oin t interpolated precision i.e., the interpolated precision at 11 equally spaced recall points b etw een 0 and 1 (inclusiv e), see [ 21 ], §8.4 for details. 11 tation could scale to even larger datasets. All exp erimen ts w ere p erformed on a mac hine with 64 AMD Opteron 6376 CPUs and 256GB of RAM. Evaluation Criteria W e will ev aluate I IM along with MTV, SLIM, KRIMP and CHARM with χ 2 -test ranking according to the follo wing criteria: 1. Spuriousness – to assess the degree of spurious correlation in the mined set of itemsets. 2. R e dundancy – to measure how redundant the mined set of itemsets is. 3. Interpr etability – to informally assess ho w meaningful and relev an t the mined itemsets actually are. Note that w e c hose not to compare to the tiling methods from [ 11 , 16 ] as they ha ve b een shown to underp erform on the ICDM dataset [ 20 ]. 4.1 Itemset Spuriousness The set-co ver form ulation of the IIM algorithm ( 3 ) naturally fa v ours adding itemsets to the mo del whose items co-o ccur in the transaction database. One w ould therefore exp ect I IM to largely av oid suggesting itemsets of uncorrelated items and so generate more meaningful itemsets. T o verify this is the case and v alidate our inference pro cedure, we c heck if I IM is able to recov er the itemsets it used generate a syn thetic database. T o obtain a realistic synthetic database, w e sampled 10 , 000 transactions from the I IM generative mo del trained on the plan ts dataset. W e were then able to measure the precision and recall for eac h algorithm, i.e., the fraction of mined itemsets that are generating and the fraction of generating itemsets that are mined, resp ectiv ely . W e used a minim um supp ort of 0 . 0575 for all algorithms (except I IM) as used in [ 20 ] for the plan ts dataset. Figure 1 sho ws the precision-recall curv e for eac h algorithm using the top- k mined itemsets (according to each algorithm’s ranking) as a threshold. One can clearly see that I IM was able to mine ab out 50% of the generating itemsets and almost all the itemsets mined were generating. This not only provides a go od v alidation of IIM’s inference pro cedure and underlying generativ e mo del but also demonstrates that IIM returns few spurious itemsets. F or comparison, SLIM and KRIMP exhibited v ery similar b ehaviour to I IM whereas MTV returned a T able 1. Summary of the real datasets used and I IM results after 1 , 000 iterations. † excluding singleton itemsets. Dataset Items T rans. |I |† Run time ICDM 4 , 976 859 798 163 min Mammals 194 2 , 670 359 22 min Plan ts 70 34 , 781 259 27 min Retail 16 , 470 88 , 162 957 941 min Uganda 33 , 278 124 , 566 928 1086 min T able 2. I ID for the top 50 non-singleton itemsets returned by the algorithms. *re- turned less than 50 non-singleton itemsets. ICDM Mam. Plant Retail Ugan. I IM 4 . 00 7 . 42 4 . 80 3 . 26 3 . 78 MTV 3 . 14 * 5 . 50 * 5 . 00 2 . 52 * 1 . 60 SLIM 2 . 12 * 1 . 76 * 1 . 77 1 . 44 2 . 08 KRIMP 2 . 56 1 . 94 1 . 88 1 . 34 2 . 26 CHARM 1 . 42 1 . 44 1 . 50 1 . 32 1 . 72 12 v ery small set of generating itemsets. The set of top itemsets mined by CHARM con tained many itemsets that w ere not generating. It is not our in tention to draw conclusions ab out the p erformance of the other algorithms as this exp erimental setup naturally fav ours I IM. Instead, we compare the itemsets from I IM with those from MTV, SLIM and KRIMP on real-world data in the next sections. 4.2 Itemset Redundancy W e now turn our atten tion to ev aluating whether I IM returns a less redundant list of itemsets than the other algorithms on real-w orld datasets. A suitable measure of redundancy for a single itemset is the minim um symmetric difference b et w een it and the other itemsets in the list. A v eraging this across all itemsets in the list, we obtain the aver age inter-itemset distanc e (I ID). W e therefore ran all the algorithms on the datasets in T able 1 . This enabled us to calculate, for each dataset, the I ID of the top 50 non-singleton itemsets, whic h we report in T able 2 . F or CHARM, w e to ok the top 50 non-singleton itemsets ranked according to χ 2 from the top 100 , 000 frequent itemsets it returned (as the χ 2 calculation would b e prohibitively slow otherwise). One can clearly see that the top I IM itemsets ha ve a larger I ID on a verage, and are therefore less redundan t, than the KRIMP , SLIM or CHARM itemsets. The top CHARM χ 2 -rank ed itemsets are the most redundan t as exp ected. On all datasets, the I IM itemsets are less redundant than those mined b y the other metho ds, with only one exception. On the Plants dataset, MTV is sligh tly less redundant than IIM, but this is b ecause MTV is unable to return 50 items on this dataset, instead returning only 21 . 4.3 Itemset In terpretabilit y F or the datasets in T able 1 we can directly interpret the mined itemsets and informally assess how meaningful and relev ant they are. ICDM Dataset W e compare the top ten non-singleton itemsets mined by the algorithms in T able 3 (excluding KRIMP whose itemsets are similar for space reasons). The mined patterns are all very informative, con taining technical con- cepts such as supp ort ve ctor machine and common phrases such as p attern dis- c overy . The IIM itemsets suggest the stemmer used to pro cess the dataset could b e impro ved, as we retrieve { p ar ameter, p ar ameters } and { se quenc, se quential }. Plants and Mammals Datasets F or both datasets, all algorithms find itemsets that are spatially coherent, but as w e sho wed in T able 2 , those returned b y I IM are far less redundant. Our no vel in terestingness measure enables I IM to rank correlated itemsets ab ov e singletons and rare itemsets ab o ve frequen t ones, in con trast to the other algorithms. F or example, for the plan ts dataset, the top itemset retrieved by IIM is { Puerto Ric o, Vir gin Islands } whereas MTV returns { Puerto Ric o }, not associating it with the V ir gin Islands (whic h are adjacen t) until the 20th ranked itemset. F or the mammals dataset, the top tw o non-singleton I IM itemsets are a group of four mammals that co exist in Scotland and Ireland and a group of ten mammals that co exist on Sw eden’s b order with 13 T able 3. T op ten non-singleton ICDM itemsets as found b y I IM, MTV and SLIM. I IM MTV SLIM asso ci rule exp erimen t result inform mo del lo cal global syn thetic real cluster algorithm supp ort v ector mac hin svm real datasets larg effici parameter parameters pattern discov p erform set anomali detect associ rule mine prop os problem sequenc sequential frequen t pattern mine algorithm metho d set linear discriminant analysi train classifi asso ci rule syn thetic real life address problem problem result bac kground knowledg classifi class approac h base metho d semi sup ervised mac hin learn base metho d set T able 4. T op six non-singleton Uganda itemsets for each algorithm. I IM MTV SLIM KRIMP soul, rest, peace heal, jesus, amen !, ? whi, ? c hris, brown go d, amen 2, 4 ?, ! b ebe, co ol 2, 4 whi, ? 2, 4 airtel, red whi, ? go d, amen w at, ? ev eri, thing go d, heal da, dat time, ! time, wast 2, ! heal, jesus, amen soul, rest, p eace Norw ay . By contrast, the top four SLIM and KRIMP itemsets list some of the most common mammals in Europ e (see the supplementary material for details). U ganda Dataset The top six non-singleton itemsets found by the algorithms are sho wn in T able 4 ; the IIM itemsets provide muc h more information about the topics of the messages than those from the other algorithms. Figure 3 (left) plots the mentions of each of the top IIM itemsets per day . As one can see, usage of the top itemsets displays temp oral structure (and exhibits spikes of p opularit y), ev en though our mo del do es not explicitly capture this. Of particular interest are the large spik es of { soul, r est, p e ac } corresponding to notable deaths: wealth y businessman James Mulwana on the 15th January , Presiden t Musev eni’s father on the 22nd F ebruary and six sc ho ol students in a traffic acciden t on the 29th Marc h. Also of interest are the 285 mentions of { airtel, r e d } on New Y ear’s Eve corresp onding to mobile provider Airtel’s Red Christmas comp etition for 10K w orth of airtime. The spik e of { b eb e, c o ol } on the 15th Jan uary corresponds to the Ugandan m usician’s wedding announcemen t and the spike on the 24th Jan uary of { chris, br own } refers to man y enth usiastic men tions of the p opular American singer that day . The last tw o itemsets capture common phrases. In comparison, the top-six MTV itemsets are plotted in Figure 3 (right). One can see that the itemsets { he al, jesus, amen };{ go d, amen } and { go d, he al } substan tially o verlap and are strongly correlated with each other, sharing a large spik e on the 8th F ebruary and a smaller spik e on the 11th Marc h. The remaining 14 01/2013 02/2013 03/2013 04/2013 0 20 40 60 80 100 Mentions per day soul, rest, peac chris, brown bebe, cool airtel, red everi, thing time, wast 01/2013 02/2013 03/2013 04/2013 0 100 200 300 400 500 600 Mentions per day heal, jesus, amen god, amen 2, 4 whi, ? god, heal 2, ! Fig. 3. Mentions p er day of the top six non-singleton IIM (left) and MTV (right) itemsets from the Uganda messages dataset ov er three months. itemsets exhibit no interesting spikes as one w ould exp ect. The top six SLIM and KRIMP itemsets in T able 4 all displa y ed random time evolution, as one would exp ect, except for the religious ones we hav e already encountered. 5 Conclusions W e presented a generative model that directly infers itemsets that b est explain a transaction database along with a no vel model-derived measure of in terestingness and demonstrated the efficacy of our approach on b oth syn thetic and real-world databases. In future we would like to extend our approach to directly inferring the asso ciation rules implied b y the itemsets and parallelize our approac h to large clusters so that we can efficiently scale to muc h larger databases. A ckno wledgemen ts. This w ork was supported b y the Engineering and Ph ysical Sciences Researc h Council (grant num b er EP/K024043/1). W e thank John Quinn for sharing the Uganda data. References 1. Aggarw al, C., Han, J.: F requent Pattern Mining. Springer (2014) 2. Agra wal, R., Srikant, R.: F ast algorithms for mining asso ciation rules. In: VLDB. v ol. 1215, pp. 487–499 (1994) 3. Bar-Y ehuda, R., Even, S.: A linear-time appro ximation algorithm for the w eighted v ertex cov er problem. Journal of Algorithms 2(2), 198–203 (1981) 4. Ch v átal, V.: A greedy heuristic for the set-cov ering problem. Math. O.R. 4(3), 233–235 (1979) 5. Cormen, T., Leiserson, C., Rivest, R., Stein, C.: Introduction to Algorithms. MIT Press (2001) 6. Dempster, A., Laird, N., Rubin, D.: Maximum lik eliho od from incomplete data via the EM algorithm. Journal of the Roy al Statistical So ciet y: Series B pp. 1–38 (1977) 15 7. F eige, U.: A threshold of ln n for approximating set co ver. Journal of the ACM 45(4), 634–652 (1998) 8. F ournier-Viger, P ., Mw amikazi, E., Gueniche, T., F aghihi, U.: MEIT: Memory Efficien t Itemset Tree for targeted association rule mining. In: A dv anced Data Mining and Applications, Lecture Notes in Computer Science, vol. 8347, pp. 95– 106 (2013) 9. F riedman, N.: The Ba yesian structural EM algorithm. In: UAI. pp. 129–138 (1998) 10. Gallo, A., De Bie, T., Cristianini, N.: MINI: Mining informative non-redundan t itemsets. In: PKDD, pp. 438–445 (2007) 11. Geerts, F., Go ethals, B., Mielikäinen, T.: Tiling databases. In: Discov ery science. pp. 278–289 (2004) 12. Go ethals, B., Zaki, M.: FIMI rep ository (2004), http://fimi.ua.ac.be/ 13. Han, J., Pei, J., Yin, Y.: Mining frequent patterns without candidate generation. In: SIGMOD Record. vol. 29, pp. 1–12 (2000) 14. He, R., Shapiro, J.: Bay esian mixture mo dels for frequent itemset disco very . arXiv preprin t arXiv:1209.6001 (2012) 15. Jaroszewicz, S., Simovici, D.A.: Interestingness of frequent itemsets using Ba yesian net works as background knowledge. In: SIGKDD. pp. 178–186 (2004) 16. K ontonasios, K.N., De Bie, T.: An information-theoretic approac h to finding in- formativ e noisy tiles in binary databases. In: SDM. pp. 153–164 (2010) 17. K orte, B., V ygen, J.: Combinatorial Optimization: Theory and Algorithms. Algo- rithms and Com binatorics, Springer (2012) 18. MacKa y, D.J.C.: Information Theory , Inference, and Learning Algorithms. Cam- bridge Universit y Press (2003) 19. Mampaey , M., T atti, N., V reek en, J.: T ell me what i need to kno w: succinctly summarizing data with itemsets. In: SIGKDD. pp. 573–581 (2011) 20. Mampaey , M., V reek en, J., T atti, N.: Summarizing data succinctly with the most informativ e itemsets. TKDD 6(4), 16 (2012) 21. Manning, C., Raghav an, P ., Schütze, H.: Introduction to Information Retriev al. Cam bridge Universit y Press (2008) 22. Miettinen, P ., Mielikainen, T., Gionis, A., Das, G., Mannila, H.: The discrete basis problem. IEEE TKDE 20(10), 1348–1362 (2008) 23. Mitc hell-Jones, A., Amori, G., Bogdanowicz, W., Kryštufek, B., Reijnders, P ., Spitzen b erger, F., Stubbe, M., Thissen, J., V ohralík, V., Zima, J.: The A tlas of Europ ean Mammals. T & AD Po yser (1999) 24. Murph y , K.: Machine Learning: A Probabilistic Perspective. MIT Press (2012) 25. Sh we, M.A., Middleton, B., Hec kerman, D., Henrion, M., Horvitz, E., Lehmann, H., Co oper, G.: Probabilistic diagnosis using a reformulation of the INTERNIST- 1/QMR kno wledge base. Metho ds of Information in Medicine 30(4), 241–255 (1991) 26. Smets, K., V reeken, J.: SLIM: Directly mining descriptive patterns. In: SDM. pp. 236–247 (2012) 27. USD A: The PLANTS Database (2008), http://plants.usda.gov/ 28. V reeken, J., V an Leeu wen, M., Sieb es, A.: KRIMP: mining itemsets that compress. Data Mining and Knowledge Disco very 23(1), 169–214 (2011) 29. W ebb, G.I., V reeken, J.: Efficien t disco very of the most interesting associations. TKDD 8(3), 15 (2014) 30. Y oung, N.: Greedy set-co ver algorithms (1974-1979, Chvátal, Johnson, Lo vász, Stein). In: Kao, M. (ed.) Encyclop edia of Algorithms, pp. 379–381 (2008) 31. Zaki, M.J., Hsiao, C.J.: CHARM: An efficient algorithm for closed itemset mining. In: SDM. v ol. 2, pp. 457–473 (2002) 16
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment