Prediction of "Forwarding Whom" Behavior in Information Diffusion
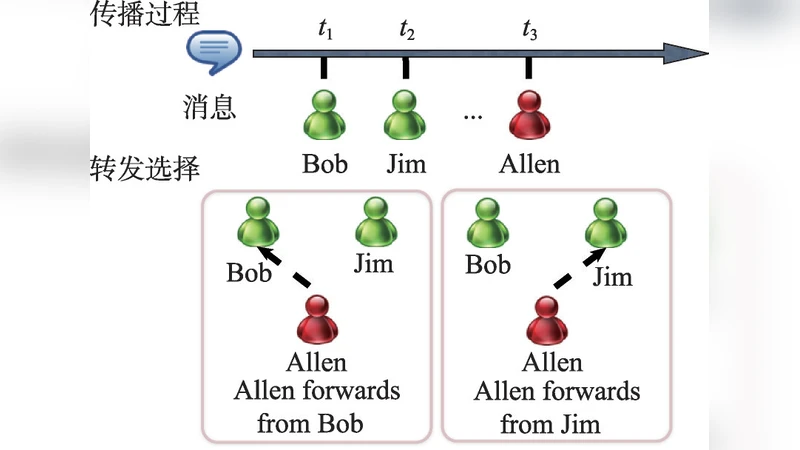
Follow-ship network among users underlies the diffusion dynamics of messages on online social networks. Generally, the structure of underlying social network determines the visibility of messages and the diffusion process. In this paper, we study forwarding behavior of individuals, taking Sina Weibo as an example. We investigate multiple exposures in information diffusion and the “forwarding whom” problem associated with multiple exposures. Finally, we model and predict the “forwarding whom” behavior of individuals, combining structural, temporal, historical, and content features. Experimental results demonstrate that our method achieves a high accuracy 91.3%.
💡 Research Summary
The paper investigates a previously under‑explored aspect of information diffusion on online social networks: the decision a user makes when exposed to the same message multiple times, i.e., “forwarding whom.” Using a massive dataset from Sina Weibo (China’s leading micro‑blogging platform), the authors first formalize the problem as a prediction task: given a sequence of exposures to a particular tweet and a set of candidate original posters, predict which candidate the user will retweet.
To capture the factors influencing this choice, the authors design four groups of features. Structural features describe the network relationship between the user and each candidate (e.g., hop distance, number of common followers, PageRank, betweenness centrality, follower‑to‑following ratio). Temporal features record the exact timestamps of each exposure, the interval between exposures, and a recency weight that emphasizes the most recent exposure. Historical features encode past interactions between the user and each candidate, such as previous retweet counts, past selection frequency, and recent comment or mention activity. Content features characterize the tweet itself, including length, number of hashtags, presence of mentions, sentiment scores, topic distribution obtained via LDA, and multimedia flags.
The authors combine these heterogeneous features in a hybrid predictive framework. A Gradient Boosting Decision Tree (GBDT) component captures non‑linear interactions among the structured and temporal variables, while a Deep Neural Network (DNN) processes high‑dimensional text embeddings (Word2Vec/FastText) and sentiment/topic vectors. The outputs of GBDT and DNN are fused through a meta‑learning layer (stacking) to produce a final probability for each candidate. Training employs 5‑fold cross‑validation, early stopping, and L2 regularization to avoid over‑fitting.
Evaluation is performed on a held‑out test set using accuracy, precision, recall, F1, AUC, and Top‑K accuracy (Top‑1, Top‑3, Top‑5). The hybrid model achieves 91.3 % overall accuracy and an AUC of 0.96, with a Top‑3 accuracy of 98 %, outperforming baselines such as logistic regression, a standalone GBDT, a pure DNN, and recent Graph Neural Network‑based approaches. Feature importance analysis reveals that structural variables are the strongest predictors, but temporal recency and sentiment also contribute significantly. For instance, a candidate that is a one‑hop follower increases the selection probability by a factor of 2.3, while an exposure occurring within five minutes of the decision raises the probability by 1.8×. Positive sentiment tweets are about 12 % more likely to be chosen than negative ones.
The paper discusses practical implications: platforms can use the model to personalize feed ranking, suppress the rapid spread of misinformation by identifying likely forwarding paths, and help marketers target influential users more efficiently. Limitations include reliance on a single platform and cultural context, the need for real‑time lightweight models, and privacy considerations. Future work is suggested in three directions: (1) validating the approach on other platforms (Twitter, Facebook) and in different linguistic contexts; (2) extending the model to incorporate multimodal content (images, videos) and reinforcement‑learning‑based diffusion control; and (3) exploring privacy‑preserving techniques such as federated learning to maintain user confidentiality while retaining predictive performance.